机器学习数学原理专题 |
您所在的位置:网站首页 › 函数求导的作用和意义 › 机器学习数学原理专题 |
机器学习数学原理专题
|
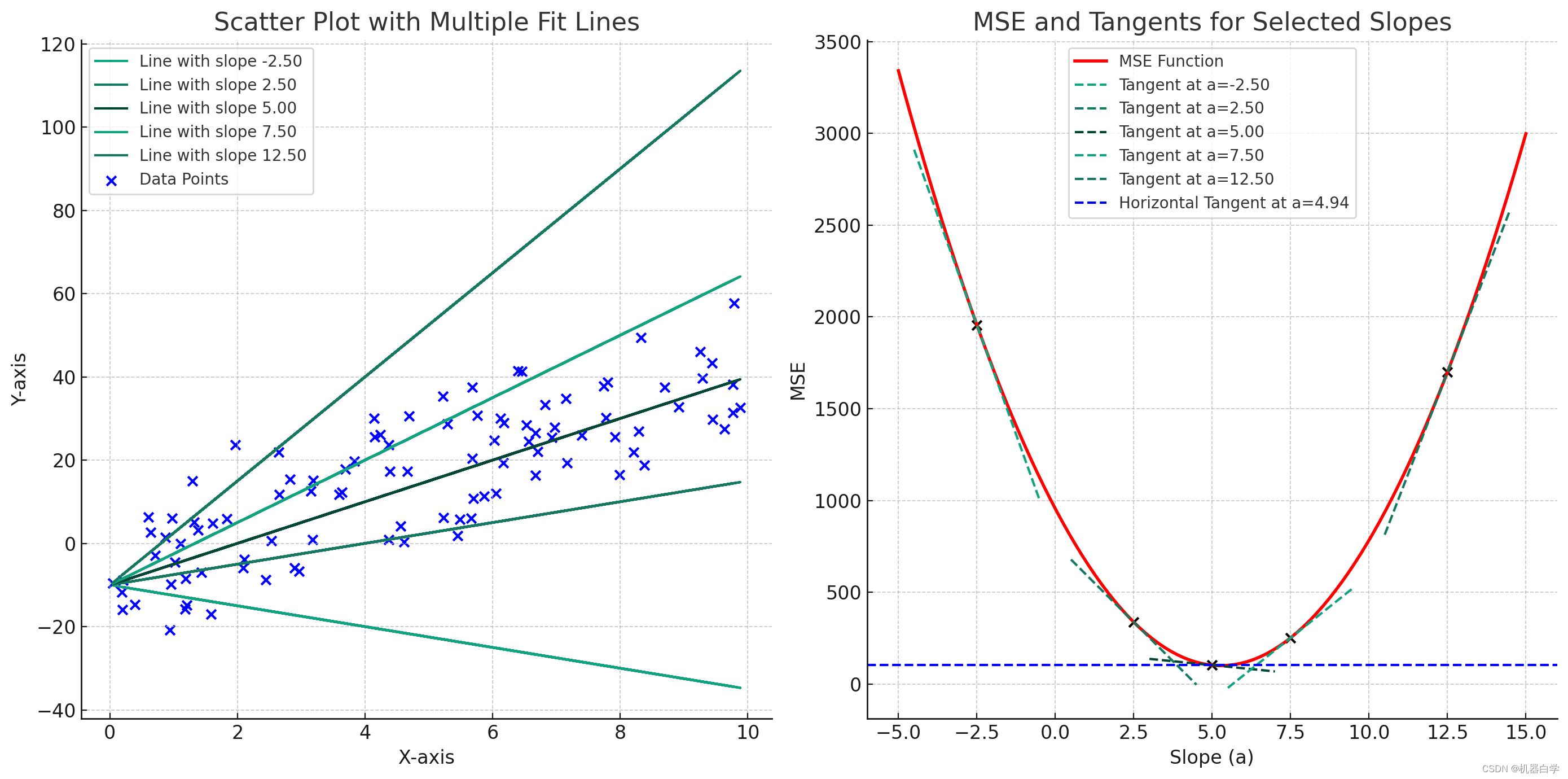
目录 二、从线性模型开始:回归 3.回归损失函数求导 (1)梯度下降法 (2)直接求导法 一、从线性模型开始:回归在之前的文章中我们介绍了回归问题损失函数的推导,现在已知损失函数,想要使用损失函数来更新模型参数以实现最优化,就要涉及损失函数的求导问题了。 回归损失函数推导文章地址:https://blog.csdn.net/qq_58718853/article/details/137536043 3.回归损失函数求导 (1)梯度下降法机器学习的过程是对损失函数求导,然后根据导数优化参数的过程。因为损失函数衡量的是模型输出和实际数据的差异,因此我们希望这个差异值越小越好。对于回归函数的损失函数MSE来说,它具有很好的数学性质。 MSE损失函数是机器学习中不多的有唯一最优解的。MSE是一个凸(凸向x轴)函数,意味着有一个全局最小值。如下右图所示,像一个抛物线。
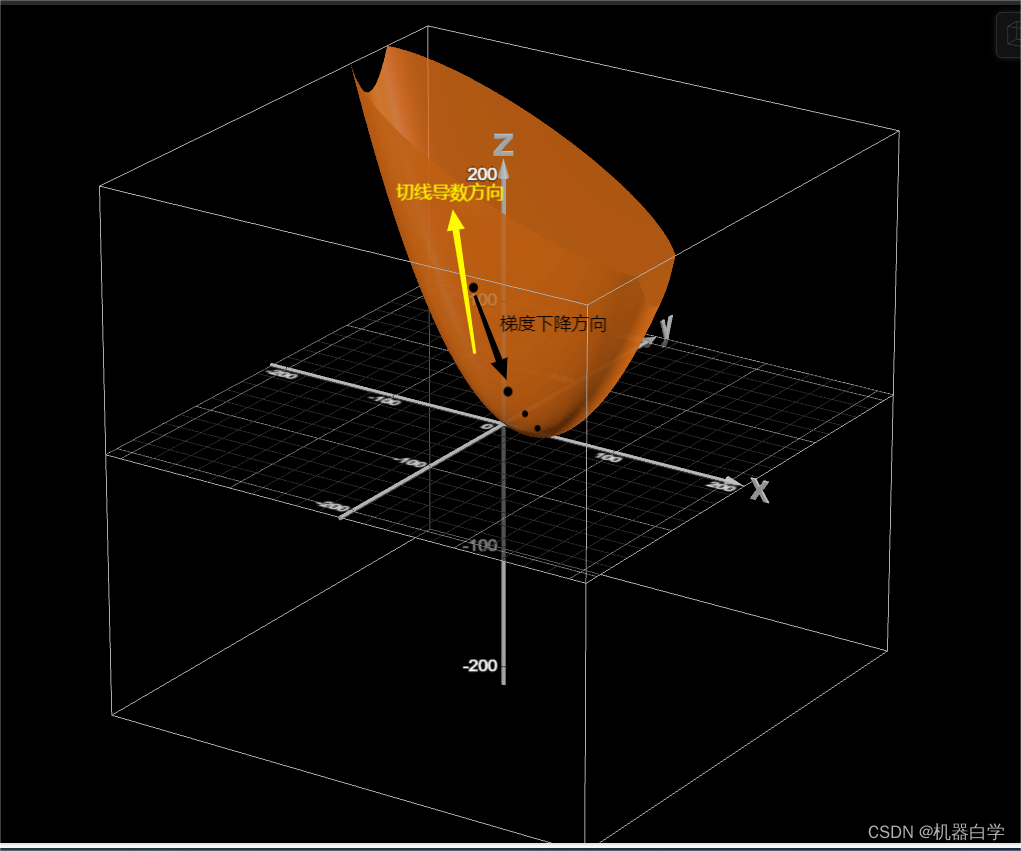
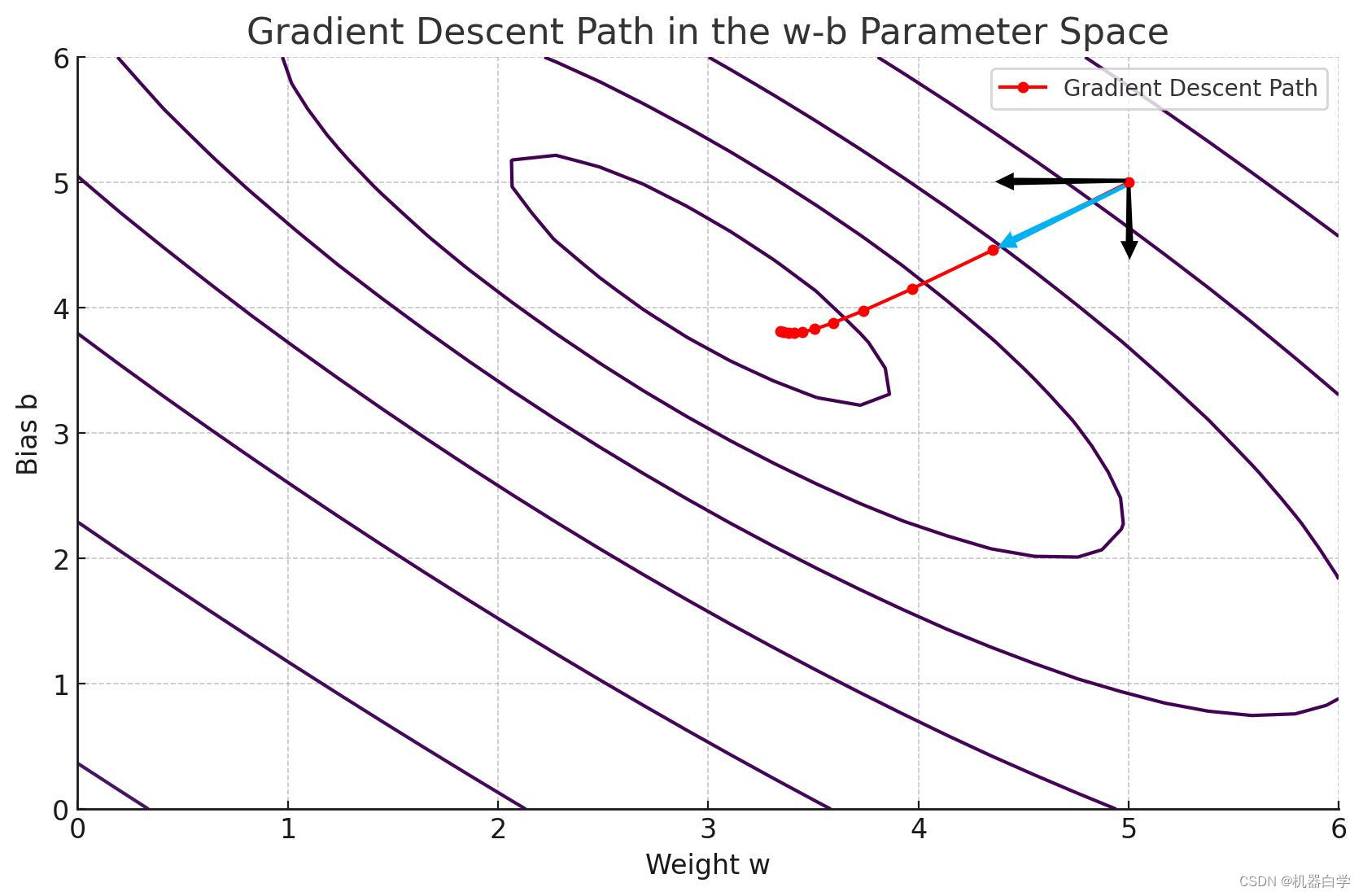
其特性意味着我们可以根据中学知识,直接对损失函数求导取零,其对应的参数值就是最优曲线的参数。这是非常特殊的,更常见的是梯度优化方式。 如上图,从一个随机的线出发,其对应于损失函数上一点(x轴代表该线的斜率参数,y值是损失函数值),假设其在最低点左侧,我们可以看到左侧所有点对应的导数(虚线:过该点损失曲线的切线斜率)都是负数。 需注意损失函数是关于参数的函数,因此图中x轴代表的含义是模型参数。在梯度下降法中,参数是减去梯度,因此梯度负数代表模型参数是不断增加。在最优点左侧,模型参数增加可以理解为损失函数上的点不断向右下移动,不断逼近最优点。右侧同理。在最低的梯度为零,没有移动的趋势,处于稳定。 进一步理解是,梯度下降法就像是“有老师监督的持续学习”,损失函数的导数就是“老师”,其正负告模型是学习的偏“右”了,还是偏“左”了,此时模型的参数就会根据“老师的指导”,在数轴上往对应相反(正确)的方向移动。直到到达最优模型,也是损失函数最低点时,“老师闭嘴了”(损失函数求导为0。模型参数就固定下来了。下式为具体的梯度更新公式, 其实之前图例是一个简化的版本,其假设模型参数只有一个。但实际的模型参数是一个向量甚至矩阵,实际的损失函数图像十分复杂,需要升到更高维度的空间,下图给出一个比较简单的两个参数 下图可以看到梯度下降方向和求导方向相反,因此参数更新公式中使用减号。
将上图梯度下降过程投影到二维平面(俯视视角),可以进一步看清不同的参数
之前提到MSE损失函数有一种简单有效的方法快速求解最优模型参数,即将损失函数求导然后取零,其对应的参数值就是是损失最小的最优模型参数。相较梯度下降法的迭代过程,直接求导“一步到位”。下面给出其数学求导公式推导过程。 ① MSE损失函数转为矩阵形式: 之前的似然函数和最小二乘法都推出过MSE损失函数的标准形式如下。 假如将 那么 可以看出标准形式Loss损失函数和新构建矩阵 对于矩阵 此处,再将 假设将每个样本的特征向量按行横向依次拼接,即构建一个大矩阵 因为每个样本特征维有(n+1)(多的一个是加入的误差项)个( ⬇(上标N):第N个样本的数据:第N套房源数据 展开式中小 x 举例: ⬆(下标 n):第N个样本中第n维特征值:n代表房屋面积维度 注意:如果按上述设计大矩阵 此时设计的大矩阵跟模型参数乘积 可以看出 根据矩阵 将上式代入Loss和A的关系式,可得到损失函数的矩阵形式。 MSE损失函数矩阵形式: 关键的模型参数 ②MSE损失函数的矩阵求导讨论 下面对上述矩阵形式的损失函数进行求导讨论。 矩阵求导方法:“XY”拉伸术 1.标量(一个值)不变,向量拉伸 2.“Y”横向拉伸,“X”纵向拉伸 eg: 假设函数 (横向拉伸) (纵向拉伸) 可以看到Y向量下的每一个分量被放在“横向”,X下的每一个变量放在“纵向”上,Y,X对应的分量都是单一标量,可以求出偏导,这样构成的偏导矩阵就是对Y求X偏导结果。 将矩阵形式的损失函数回到之前跟 (纵向拉伸) 通过 那么 提出公因数 可以看到,如果忽略掉常数 这里多出一个常数2,为了计算方便,同时不影响损失函数优化的本质,可以改进我们的损失函数得到损失函数的求导矩阵形式。 MSE损失函数求导矩阵形式: 仅仅在式子前多乘以一个1/2,用于抵消求导过程中的2倍值作用。 ③MSE损失函数的求导链式法则 求导链式法则: 假设 Z=f(X),Y=g(X),则存在关系式 在矩阵求导中,对一个向量求向量导,使用链式法则时可能存在维度方向不匹配的情况,需要交换调整乘法次序。因此矩阵乘法与普通链式法则的乘法顺序相反。 我们关心的是 那么根据已知条件,我们现在需要关心的就是根据求导链式法则得到的损失函数求导中的 计算 因此需要对Y( 计算 同理需要对Y( 此时使用XY拉伸术,求导结果如下。 可以发现求导结果恰好就是我们之前定义的数据特征集大矩阵 最终,将 ④MSE的矩阵二阶导的凸性保证 在梯度下降法中,我们给出了MSE损失函数的图像(一个开口向上的抛物线),此时损失函数是凸的,因此导数等于零时有唯一最小解。但是并没有证明损失函数一定是凸的,因此对于直接求导法对导数取零以算出最优参数前,还需证明损失函数是凸的,即导数等于零的点一定是函数唯一的最小值点,而不是局部极小值。这需要二阶导来判断。 对上述一阶导结果 现在来研究一下这个二阶导矩阵的形状, 正定矩阵:对于实对称方阵 矩阵合同:存在可逆矩阵 合同、二次型与正定性: 观测二阶导结果,可知一定存在可逆矩阵 终于,我们可以取一阶导为零,然后得到模型的最优解 这意味着我们如果使用线性模型,已知训练的特征数据和目标数据,我们马上就可以根据上式得到最优的模型参数(回归模型各个权值)。 |
【本文地址】