深度学习 |
您所在的位置:网站首页 › 函数图像步骤 › 深度学习 |
深度学习
|
文章目录
激活函数sigmoidtanhReLULeaky ReLUsoftmax激活函数使用建议
激活函数
激活函数是用来加入非线性因素的,因为线性模型的表达能力不够。引入非线性激活函数,可使深层神经网络的表达能力更加强大。 激活函数应满足: 非线性: 激活函数非线性时,多层神经网络可逼近所有函数。可微性: 优化器大多用梯度下降更新参数。单调性: 当激活函数是单调的,能保证单层网络的损失函数是凸函数。近似恒等性:当参数初始化为随机小值时,神经网络更稳定。激活函数输出值的范围: 激活函数输出为有限值时,基于梯度的优化方法更稳定 激活函数输出为无限值时,建议调小学习率 常见的激活函数有:sigmoid,tanh,ReLU,Leaky ReLU,PReLU,RReLU, ELU(Exponential Linear Units),softplus,softsign,softmax等。 sigmoid
函数图像: 优点: 1、 输出映射在(0,1)之间,单调连续,输出范围有限,优化稳定,可用作输出层; 2、求导容易。 缺点: 1、易造成梯度消失; 2、输出非0均值,收敛慢; 3、幂运算复杂,训练时间长。 sigmoid函数可应用在训练过程中。然而,当处理分类问题作出输出时,sigmoid却无能为力。简单地说,sigmoid函数只能处理两个类,不适用于多分类问题。而softmax可以有效解决这个问题,并且softmax函数大都运用在神经网路中的最后一层网络中,使得值得区间在(0,1)之间,而不是二分类的。 tanh
缺点: 易造成梯度消失;幂运算复杂,训练时间长。 ReLU
缺点: 输出非0均值,收敛慢;Dead ReLU问题:某些神经元可能永远不会被激活,导致相应的参数永远不能被更新。 Leaky ReLU
对于初学者的建议: 1. 首选ReLU激活函数; 2. 学习率设置较小值; 3. 输入特征标准化,即让输入特征满足以0为均值,1为标准差的正态分布; 4. 初始化问题:初始参数中心化,即让随机生成的参数满足以0为均值,2/当前层输入特征个数开根号下为标准差的正态分布。 |
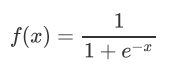
 导数图像:
导数图像: 
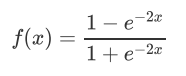 函数图像:
函数图像:  导数图像:
导数图像:  优点:
优点: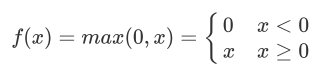 函数图像:
函数图像:  导数图像:
导数图像:  优点:
优点: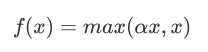 函数图像:
函数图像:  导数图像:
导数图像:  理论上来讲,Leaky ReLU有ReLU的所有优点,外加不会有Dead ReLU问题,但是在实际操作当中,并没有完全证明Leaky ReLU总是好于ReLU。
理论上来讲,Leaky ReLU有ReLU的所有优点,外加不会有Dead ReLU问题,但是在实际操作当中,并没有完全证明Leaky ReLU总是好于ReLU。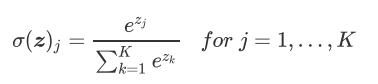 对神经网络全连接层输出进行变换,使其服从概率分布,即每个值都位于[0,1]区间且和为1。
对神经网络全连接层输出进行变换,使其服从概率分布,即每个值都位于[0,1]区间且和为1。【本文地址】
今日新闻 |
推荐新闻 |