决策树回归(概念+实例) |
您所在的位置:网站首页 › 决策树的基本结构 › 决策树回归(概念+实例) |
决策树回归(概念+实例)
|
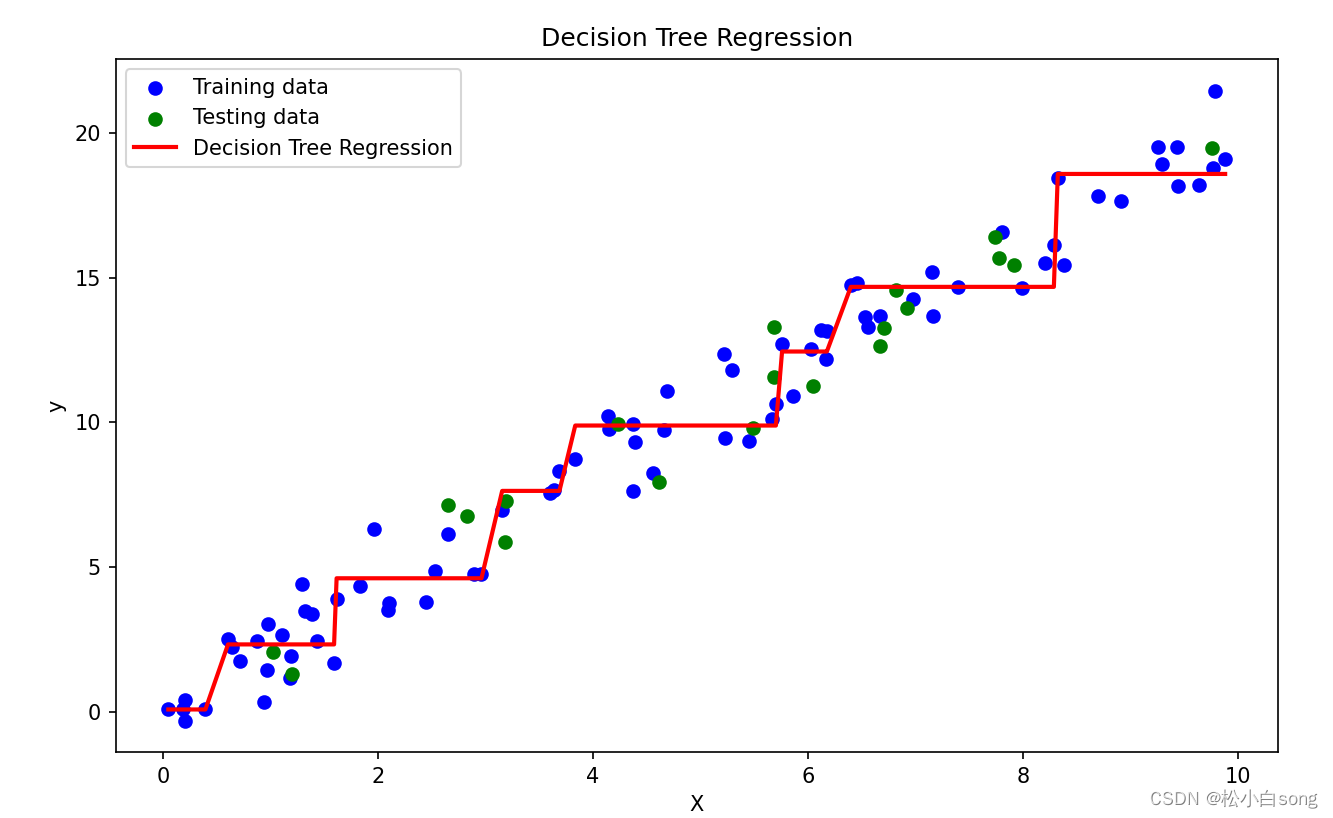
目录 前言 一、基本概念 1. 决策树回归的原理 2. 构建决策树回归模型的步骤 3. 决策树回归的优缺点 4. 决策树回归的应用场景 二、实例 前言决策树回归(Decision Tree Regression)是一种常用的机器学习算法,用于预测连续型变量的取值。它基于树结构来对数据进行建模和预测,通过将数据集划分为不同的区域,并在每个区域内预测一个常数值来实现回归任务。在本文中,我将详细介绍决策树回归的原理、构建过程、优缺点以及应用场景。 一、基本概念 1. 决策树回归的原理决策树回归通过构建一颗树结构来对数据进行建模和预测。树的每个内部节点表示一个属性/特征,每个叶节点表示一个输出值。决策树的构建过程是一个递归的过程,它通过选择最佳的属性/特征来进行数据划分,使得划分后子集的输出值尽可能接近真实值。 决策树的构建过程主要包括以下几个步骤: 选择最佳划分属性/特征:通过某种指标(如信息增益、基尼系数)选择最佳的属性/特征来进行数据划分。划分数据集:根据选择的属性/特征将数据集划分为多个子集。递归构建子树:对每个子集递归地应用上述步骤,直到满足停止条件(如达到最大深度、节点中样本数量小于阈值等)为止。在预测阶段,决策树通过将输入样本沿着树的路径进行遍历,并最终到达叶节点,然后将该叶节点的输出值作为预测结果。 2. 构建决策树回归模型的步骤构建决策树回归模型的一般步骤如下: 步骤1:准备数据集 准备包含输入特征和对应输出值的数据集。 步骤2:选择划分属性 根据某种指标(如均方误差、平方损失)选择最佳的划分属性/特征。 步骤3:划分数据集 根据选择的划分属性将数据集划分为多个子集。 步骤4:递归构建子树 对每个子集递归地应用上述步骤,直到满足停止条件。 步骤5:生成决策树 构建完整的决策树结构。 3. 决策树回归的优缺点优点: 易于理解和解释:决策树可以直观地呈现,易于理解和解释,可以帮助分析人员做出决策。能够处理非线性关系:决策树可以处理非线性关系,不需要对数据进行线性假设。对数据的缺失值不敏感:决策树在构建过程中可以处理数据的缺失值。缺点: 容易过拟合:决策树容易过拟合训练数据,特别是在数据量较小或树的深度较大时。不稳定性:数据的小变化可能导致树结构的显著改变,使得决策树不够稳定。难以处理连续性特征:决策树在处理连续性特征时,需要对其进行离散化处理,可能会损失一部分信息。 4. 决策树回归的应用场景决策树回归在许多领域都有广泛的应用,特别是在以下几个方面: 金融领域:用于预测股票价格、货币汇率等金融指标。医疗领域:用于预测疾病风险、药物反应等医疗相关问题。工业领域:用于预测生产效率、设备故障率等工业数据。零售领域:用于销量预测、市场需求分析等零售业务。 二、实例在这个示例中,我们首先生成了一个简单的示例数据集,然后将数据集划分为训练集和测试集。接着,我们创建了一个最大深度为3的决策树回归模型,并使用训练数据对模型进行了训练。最后,我们使用训练好的模型对训练集和测试集进行了预测,并计算了均方误差。同时,我们还绘制了决策树回归模型在训练集上的拟合情况。 代码: # 导入所需的库 import numpy as np from sklearn.model_selection import train_test_split from sklearn.tree import DecisionTreeRegressor from sklearn.metrics import mean_squared_error import matplotlib.pyplot as plt # 生成示例数据集 np.random.seed(0) X = np.random.rand(100, 1) * 10 # 生成100个0到10之间的随机数作为特征 y = 2 * X.squeeze() + np.random.randn(100) # 生成对应的目标值,y = 2 * x + 噪声 # 将数据集划分为训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 创建并训练决策树回归模型 regressor = DecisionTreeRegressor(max_depth=3) # 设置决策树的最大深度为3 regressor.fit(X_train, y_train) # 使用训练好的模型进行预测 y_pred_train = regressor.predict(X_train) y_pred_test = regressor.predict(X_test) # 计算训练集和测试集的均方误差 mse_train = mean_squared_error(y_train, y_pred_train) mse_test = mean_squared_error(y_test, y_pred_test) print("训练集上的均方误差:", mse_train) print("测试集上的均方误差:", mse_test) # 绘制决策树回归模型在训练集上的拟合情况 plt.figure(figsize=(10, 6)) plt.scatter(X_train, y_train, color='blue', label='Training data') plt.scatter(X_test, y_test, color='green', label='Testing data') plt.plot(np.sort(X_train, axis=0), regressor.predict(np.sort(X_train, axis=0)), color='red', linewidth=2, label='Decision Tree Regression') plt.title('Decision Tree Regression') plt.xlabel('X') plt.ylabel('y') plt.legend() plt.show()结果:
|

【本文地址】
今日新闻 |
推荐新闻 |