决策树 |
您所在的位置:网站首页 › 决策树生成以后如何分类 › 决策树 |
决策树
|
决策树的详细说明:https://blog.csdn.net/suipingsp/article/details/41927247 什么是决策树: 决策树是通过一系列规则对数据进行分类的过程。它提供一种在什么条件下会得到什么值的类似规则的方法。决策树分为分类树和回归树两种,分类树对离散变量做决策树,回归树对连续变量做决策树。 2, 一棵决策树的生成过程主要分为以下3个部分: 特征选择:特征选择是指从训练数据中众多的特征中选择一个特征作为当前节点的分裂标准,如何选择特征有着很多不同量化评估标准标准,从而衍生出不同的决策树算法。 决策树生成: 根据选择的特征评估标准,从上至下递归地生成子节点,直到数据集不可分则停止决策树停止生长。 树结构来说,递归结构是最容易理解的方式。 剪枝:决策树容易过拟合,一般来需要剪枝,缩小树结构规模、缓解过拟合。剪枝技术有预剪枝和后剪枝两种。 3,基于信息论的三种决策树算法ID3:ID3算法中根据信息论的信息增益评估和选择特征,每次选择信息增益最大的特征做判断模块。使用信息增益的话其实是有一个缺点,那就是它偏向于具有大量值的属性--就是说在训练集中,某个属性所取的不同值的个数越多,那么越有可能拿它来作为分裂属性,而这样做有时候是没有意义的,另外ID3不能处理连续分布的数据特征,于是就有了C4.5算法。CART算法也支持连续分布的数据特征。 C4.5是ID3的一个改进算法,继承了ID3算法的优点。C4.5算法用信息增益率来选择属性,克服了用信息增益选择属性时偏向选择取值多的属性的不足在树构造过程中进行剪枝;能够完成对连续属性的离散化处理;能够对不完整数据进行处理。C4.5算法产生的分类规则易于理解、准确率较高;但效率低,因树构造过程中,需要对数据集进行多次的顺序扫描和排序。也是因为必须多次数据集扫描,C4.5只适合于能够驻留于内存的数据集。 CART算法的全称是Classification And Regression Tree,采用的是Gini指数(选Gini指数最小的特征s)作为分裂标准,同时它也是包含后剪枝操作。ID3算法和C4.5算法虽然在对训练样本集的学习中可以尽可能多地挖掘信息,但其生成的决策树分支较大,规模较大。为了简化决策树的规模,提高生成决策树的效率,就出现了根据GINI系数来选择测试属性的决策树算法CART。 4,信息熵和gini指数:https://www.cnblogs.com/muzixi/p/6566803.html 信息熵: gini指数:https://blog.csdn.net/e15273/article/details/79648502(例子详细介绍如何计算gini指数)
cart树分为分类树(变量是离散变量)和回归树(变量是连续型),二叉树,ID3是多叉树。 CART算法的重要基础包含以下三个方面: (1)二分(Binary Split):在每次判断过程中,都是对观察变量进行二分。 CART算法采用一种二分递归分割的技术,算法总是将当前样本集分割为两个子样本集,使得生成的决策树的每个非叶结点都只有两个分枝。因此CART算法生成的决策树是结构简洁的二叉树。因此CART算法适用于样本特征的取值为是或非的场景,对于连续特征的处理则与C4.5算法相似。 (2)单变量分割(Split Based on One Variable):每次最优划分都是针对单个变量。 (3)剪枝策略:CART算法的关键点,也是整个Tree-Based算法的关键步骤。 剪枝过程特别重要,所以在最优决策树生成过程中占有重要地位。有研究表明,剪枝过程的重要性要比树生成过程更为重要,对于不同的划分标准生成的最大树(Maximum Tree),在剪枝之后都能够保留最重要的属性划分,差别不大。反而是剪枝方法对于最优树的生成更为关键。 2,处理连续数值型特征 C4.5既可以处理离散型属性,也可以处理连续性属性。在选择某节点上的分枝属性时,对于离散型描述属性,C4.5的处理方法与ID3相同。对于连续分布的特征,其处理方法是: 先把连续属性转换为离散属性再进行处理。虽然本质上属性的取值是连续的,但对于有限的采样数据它是离散的,如果有N条样本,那么我们有N-1种离散化的方法:vj的分到右子树。计算这N-1种情况下最大的信息增益率。另外,对于连续属性先进行排序(升序),只有在决策属性(即分类发生了变化)发生改变的地方才需要切开,这可以显著减少运算量。经证明,在决定连续特征的分界点时采用增益这个指标(因为若采用增益率,splittedinfo影响分裂点信息度量准确性,若某分界点恰好将连续特征分成数目相等的两部分时其抑制作用最大),而选择属性的时候才使用增益率这个指标能选择出最佳分类特征。 在C4.5中,对连续属性的处理如下:1. 对特征的取值进行升序排序 2. 两个特征取值之间的中点作为可能的分裂点,将数据集分成两部分,计算每个可能的分裂点的信息增益(InforGain)。优化算法就是只计算分类属性发生改变的那些特征取值。 3. 选择修正后信息增益(InforGain)最大的分裂点作为该特征的最佳分裂点 4. 计算最佳分裂点的信息增益率(Gain Ratio)作为特征的Gain Ratio。注意,此处需对最佳分裂点的信息增益进行修正:减去log2(N-1)/|D|(N是连续特征的取值个数,D是训练数据数目,此修正的原因在于:当离散属性和连续属性并存时,C4.5算法倾向于选择连续特征做最佳树分裂点) 分类树得到的数据结果为:0,1值。而回归树得到的结果为一个值,区间的平均值。所以损失函数为:https://www.cnblogs.com/liuwu265/p/4688403.html 回归树:使用平方误差最小准则。 分类树:使用基尼指数最小化准则 或者看其他指标,auc和KS,反应模型的好坏。 5,CART的剪枝 分析分类回归树的递归建树过程,不难发现它实质上存在着一个数据过度拟合问题。在决策树构造时,由于训练数据中的噪音或孤立点,许多分枝反映的是训练数据中的异常,使用这样的判定树对类别未知的数据进行分类,分类的准确性不高。因此试图检测和减去这样的分支,检测和减去这些分支的过程被称为树剪枝。树剪枝方法用于处理过分适应数据问题。通常,这种方法使用统计度量,减去最不可靠的分支,这将导致较快的分类,提高树独立于训练数据正确分类的能力。决策树常用的剪枝常用的简直方法有两种:预剪枝(Pre-Pruning)和后剪枝(Post-Pruning)。预剪枝是根据一些原则及早的停止树增长,如树的深度达到用户所要的深度、节点中样本个数少于用户指定个数、不纯度指标下降的最大幅度小于用户指定的幅度等;后剪枝则是通过在完全生长的树上剪去分枝实现的,通过删除节点的分支来剪去树节点,可以使用的后剪枝方法有多种,比如:代价复杂性剪枝、最小误差剪枝、悲观误差剪枝等等。 CART常采用事后剪枝方法,构建决策树过程中的第二个关键就是用独立的验证数据集对训练集生长的树进行剪枝。 决策树处理缺失值的办法: 决策树不需要处理缺失值,当然缺失值过多可以舍去这部分特征。 xgb如何处理缺失值,https://blog.csdn.net/qq_19446965/article/details/81637199,https://www.zhihu.com/question/58230411 2.xgboost怎幺处理缺失值? xgboost处理缺失值的方法和其他树模型不同。根据作者TianqiChen在论文[1]中章节3.4的介绍,xgboost把缺失值当做稀疏矩阵来对待,本身的在节点分裂时不考虑的缺失值的数值。缺失值数据会被分到左子树和右子树分别计层损失,选择较优的那一个。如果训练中没有数据缺失,预测时出现了数据缺失,那么默认被分类到右子树。具体的介绍可以参考[2,3]。 .什么样的模型对缺失值更敏感? 树模型对缺失值的敏感度低,大部分时候可以在数据缺失时时使用。 涉及到距离度量(distancemeasurement)时,如计算两个点之间的距离,缺失数据就变得比较重要。因为涉及到"距离离"这个概念,那么缺失值处理不当就会导致效果很差,如K近邻算法(KNN)、支持向量机(SVM)。 线性模型的代价函数(loss function)往往涉及到距离(distance)的计算,计罰筛则值和真实值之间的差别,这容易导致对缺失值敏感。 神经网络的鲁棒强,对于缺失数据不是非常敏感,但一|g没有那么多数据可供使用。 贝叶斯模型对于缺失数据也比较稳定,数据量很小的时候雜贝叶斯模型。 总体来看,对于有缺失值的数据在经过缺失处理后: 数据量很小,朴素贝叶斯 数据量适中或者较大,用树横型,优先xgboost 数据量较大,也可以用神经网络 避免使用距离度量相关的模型,如KNN和SV 深入理解机器学习——基于决策树的模型(一):分类树和回归树https://blog.csdn.net/hy592070616/article/details/81628956 |
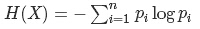
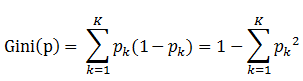

【本文地址】
今日新闻 |
推荐新闻 |