决策树之概念及思想 |
您所在的位置:网站首页 › 决策树概念是什么 › 决策树之概念及思想 |
决策树之概念及思想
|
分类树
分类决策树的核心思想就是在一个数据集中找到一个最优特征,然后从这个特征的选值中找一个最优候选值(这段话稍后解释),根据这个最优候选值将数据集分为两个子数据集,然后递归上述操作,直到满足指定条件为止。 1.最优特征怎么找? 这个问题其实就是决策树的一个核心问题了。我们常用的方法是更具信息增益或者信息增益率来寻找最优特征,信息增益这东西怎么理解呢! 搞清这个概念我们首先需要明白熵这个东西!熵简单的讲就是说我们做一件事需要的代价,代价越高肯定就越不好了。 放到机器学习的数据集中来讲就是我们数据的不确定性,代价越高对应的不确定就越高,我们用决策树算法的目的就是利用数据的一些规则来尽可能的降低数据集的不确定性。 好了,有了这个思想我们要做的事就很简单了,给定一批数据集,我们可以很容易得到它的不确定性(熵),然后呢! 我们要想办法降低这个不确定性,我们需要挖掘数据集中有用的特征,在某个特征的限制下,我们又能得到数据集的不确定性(这个其实就是书上的条件熵), 一般而言给定了一个有用的特征,数据的不确定性肯定降低了(因为有一个条件约束,比没有条件约束效果肯定会好一点,当然你的特征没有用,那就另说了)。 我们用两次的值作差,这个结果的含义很明了,给定了这个特征,让我们数据集的不确定性降低了多少,当然降低的越多这个特征肯定就越好了。 而我们讲了这么多就是要找到那一个让数据集不确定性降低最多的特征。我们认为这个特征是当前特征中最好的一个。
2.我们找到了最优特征,为什么还要找最优特征的最优候选值? 其实呀,找不找主要看我们面对的问题,一般的二分类问题确实没必要找(因为总共就两个类),但对于多分类问题,这个还是建议找,为什么要找呢? 我们来分析一下:假如我们的某个最优特征有三个类别:我们如果不找就直接分为三个子节点了。这样会出现一个问题,就是我们的这个分类对特征值会变得敏感, 为什么这么说,我们来讲一个很简答的例子:我们平时考试规定了60分及格,这个控制对于大多数学生很好把控,因为就一个条件,相当于一个二分类。 但是如果我们把条件控制严格一些,比如超过60分,不超过80分为优秀学生(当然有点扯蛋了)。这个控制很多学霸就不好控制了,对于多分类问题也是这个道理, 如果我们一下子从父节点直接分了多个子节点,那么我们的数据肯定会对这个控制很敏感,敏感就会导致出错。 出错不是我们希望看到的,所以我们建议对多分类问题找最优候选值来转化为二分类问题,同样多个二分类问题其实也是一个多分类问题,只是多了几个递归过程而已。
3.什么时候停止? 停止条件是什么?稍微详细说一下:我们从问题的根源出发去想一下,我们构造一颗决策树的目的是什么?当然是为了能在数据集上取得最好的分类效果,很好这就是一个停止标准呀! 当我们检测到数据的分类效果已经够好了,我们其实就可以停止了。 当然我们常用的是控制叶节点,比如控制叶节点的样本数目,比如当某个子节点内样本数目小于某一个指定值,我们就决定不再分了。 还有叶节点的纯度,我们规定叶节点样本必须属于同一类才停止,这也是一个停止条件。 还有最大树的深度,比如我们规定树的最大深度为某一个值,当树深度到达这个值我们也要停止。 还有比如:分裂次数,最大特征数等等。总之停止条件不是死的,我们可以更具自己的问题来随意控制,开心就好!
讲完上面几个问题,基本分类决策树的思想应该差不多了。这里为了阅读方便我还是帖几个公式仅供参考:熵:
其中D为数据集,i为数据集D的可能分类标签, Pi为该标签的概率条件熵:
其中A表示约束特征,k表示A特征的种类信息增益: gain(D,A) = entropy(D) - entropy(D,A)信息增益率:gain_rate(D,A) = gain(D,A)/entropy(D,A)
当然很多人觉得决策树学的差不多了。确实,决策树的思想就是这么简单,但是接下来的内容才是决策树的核心内容。 首先介绍两个决策树的核心算法ID3和C4.5 ID3算法其实就是我们一般所理解的决策树算法,其基本步骤就是我们上面所讲的步骤,这个算法的核心思想就是用信息增益来选择最优分类特征, 信息增益的公式上面也给出了,这个公式我们仔细分析一下会发现一个问题:我们需要找到gain(D,A)最大的特征,对于一个数据集entropy(D)是给定的,也就是说我们需要entropy(D,A)最小, 意思就是我们所选的特征是那些分完后子节点的纯度最高的特征,什么样的特征分完后子节点的特征纯度比较高(熵比较小),该特征的子类别很多,即可取值很多的这一类特征。 总结一下就是信息增益偏向于去那些拥有很多子类的特征。这也是这个算法的一大致命缺点,任何带有主观偏向性的算法都不是一个好的算法, 当然ID3算法的另一个缺点也显而易见,它只能处理那些分类的特征,对于连续值特征毫无办法(其实我们可以人为的把连续属性给离散化,但是人为必然会导致可能不准确)。 因此就有了下面的这个算法 C4.5是对ID3算法的一个改进,主要改进点就是解决了ID3的几个缺点。 首先C4.5算法用的是信息增益率来代替ID3中的信息增益。从表达式可以看出来,这么做其实就是弱化那些偏向,让选择最优特征时更加公平。另外C4.5的改进就是可以处理连续值(这个方法其实和上面我提到的连续值离散化很类似,可以理解为单点逐一离散化), 具体步骤如下: 1.首先对于连续值属性的值进行排序(A1,A2......An); 2.我们可以在每两个值之间取一个点,用这个点就可以把该组连续值分为两部分,比如我们去一个点a1($A1 |
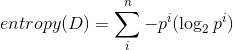
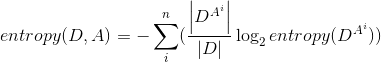
【本文地址】
今日新闻 |
推荐新闻 |