SPSS Modeler用K |
您所在的位置:网站首页 › 决策树怎么使用 › SPSS Modeler用K |
SPSS Modeler用K
|
全文链接:http://tecdat.cn/?p=32840
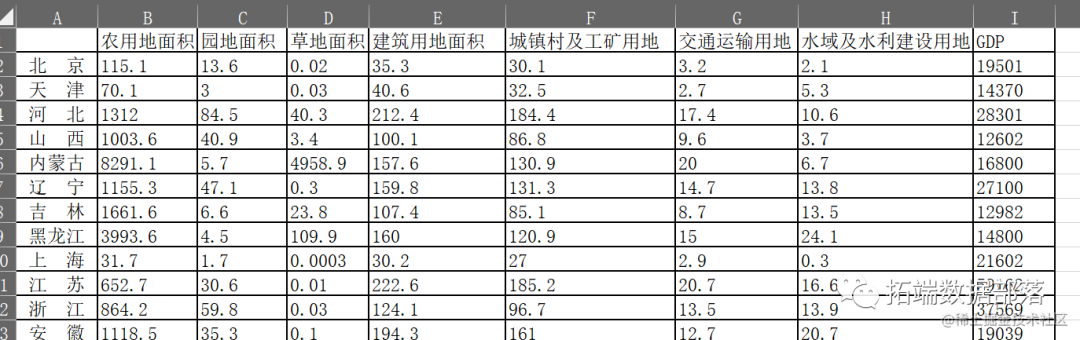
随着经济的快速发展和城市化进程的不断推进,土地资源的利用和管理成为了一项极为重要的任务(点击文末“阅读原文”获取完整代码数据)。 相关视频 而对于全国各省市而言,如何合理利用土地资源以及如何影响GDP,通过科学的方法进行规划和管理,是提高土地利用效率的关键。 本文旨在应用SPSS Modeler,帮助客户采用K-means(K-均值)聚类、CHAID、CART决策树等方法,对31个省市的土地利用情况数据进行分析和建模,以期提供科学有效的土地利用规划和管理策略。 31省市土地利用情况数据
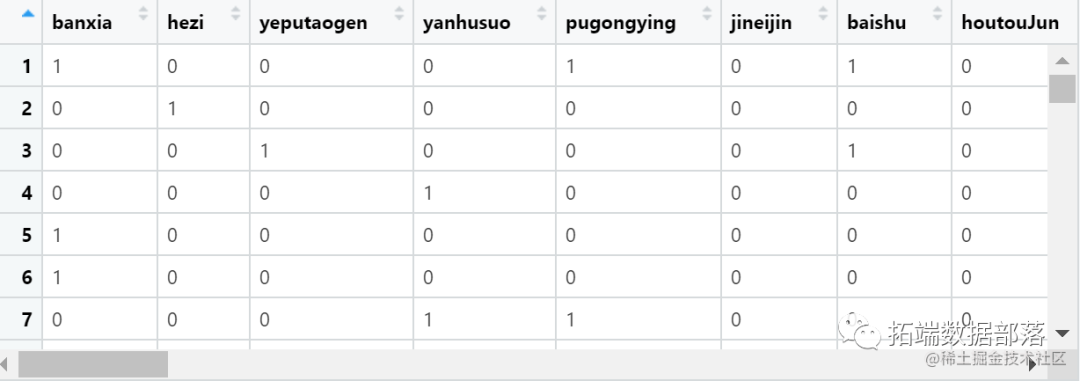
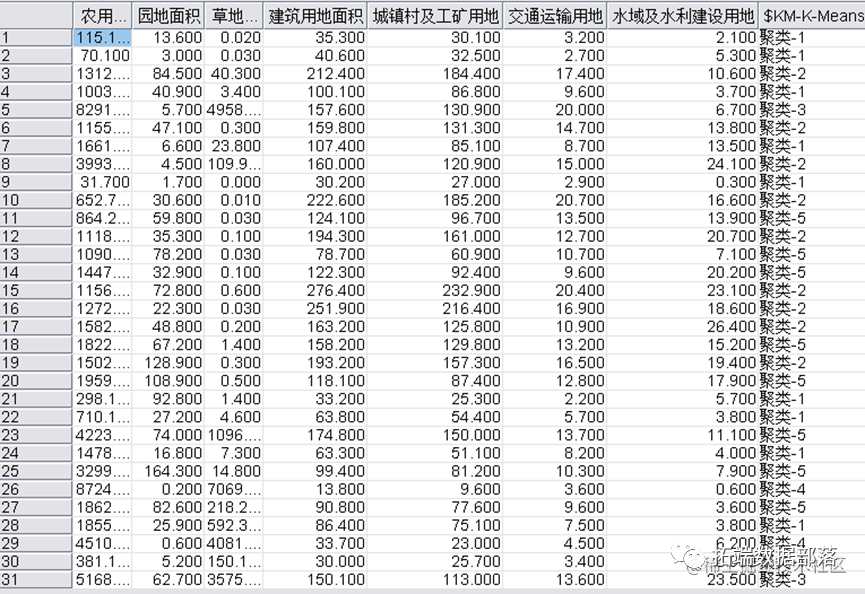
本文使用的数据来自于国家统计局发布的31省市土地利用情况数据,选取31个省市作为研究对象,并选取了包括草地、耕地、园地、林地、水域和建设用地等7种土地类型的利用情况数据。然后,使用SPSS Modeler进行数据清洗、聚类、决策树等步骤,最终得到模型结果。
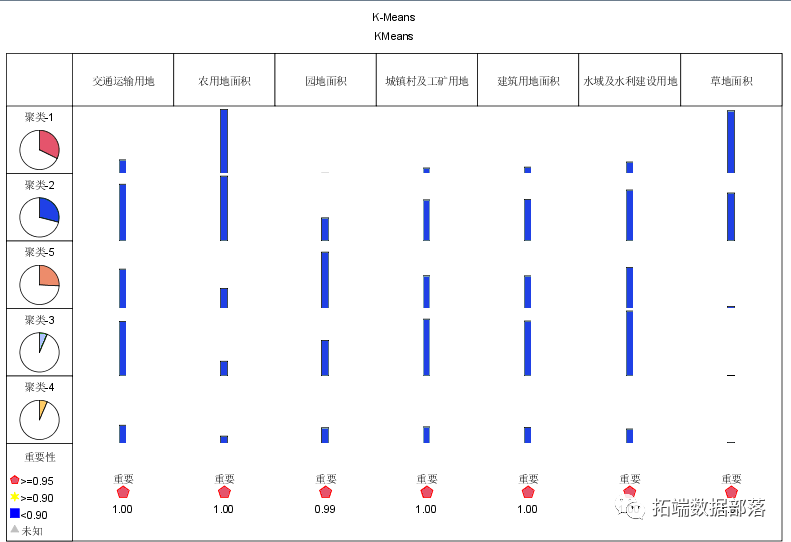
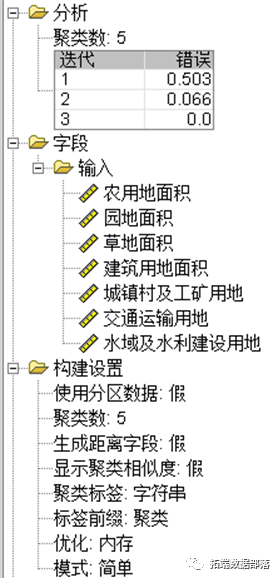
在对完整的数据集进行初步分析后,本文采用K-means聚类算法对数据集进行聚类分析。在聚类过程中,我们首先需要确定聚类的个数k。根据肘部法则和轮廓系数法则,我们得出最终选择k=5为较为合适的聚类数目。通过SPSS Modeler的K-means节点进行计算,得到了以下聚类概况、聚类类别和散点图结果。
点击标题查阅往期内容
R语言APRIORI关联规则、K-MEANS均值聚类分析中药专利复方治疗用药规律网络可视化
左右滑动查看更多
01
02
03
04
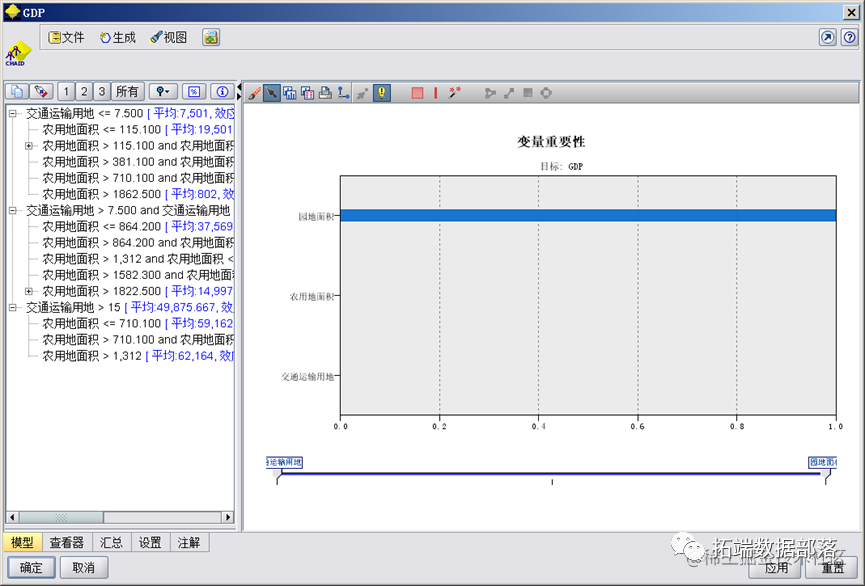
通过分类结果我们不难看出,同类省份基本上是相邻省份,或是区域类型(沿海、内陆)相似的省份,对于同类省份,我们可以采取相似的管理制度,使同等级省份得到更好的发展,也可以利用政策方式让高等级省份带动低等级省份发展。 CHAID决策树在进行完K-means聚类分析后,为了更好地了解各个类别的特征和关系,本文使用CHAID决策树算法对数据集GDP的影响因素进行进一步的分析。首先使用SPSS Modeler的CHAID节点进行计算,得到以下变量重要性和决策树结果。 变量重要性在CHAID决策树算法中,我们使用卡方值(χ2)来表征每个变量的重要性。具体而言,卡方值越大,则该变量在分类中起到的作用越大。在本文的分析中,最具有代表性的变量是园地、农用地和交通用地比重。
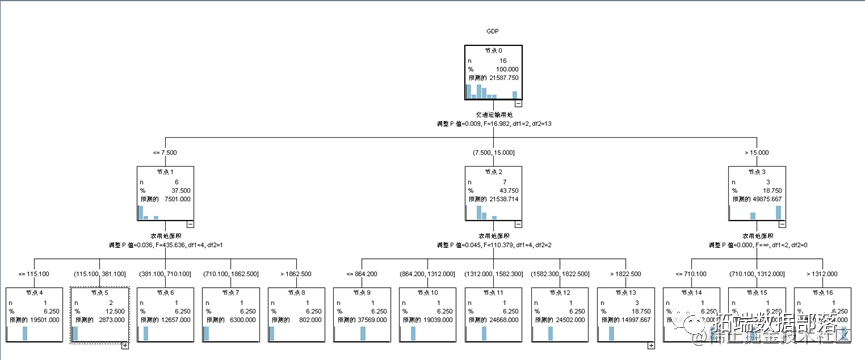
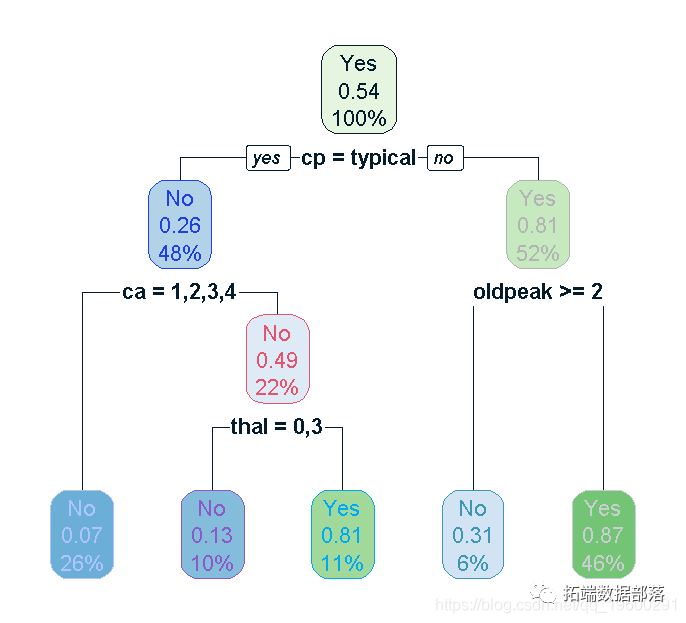
通过CHAID决策树算法,我们得到了以下的决策树模型。其中每个叶子节点代表一类,而每个内部节点包含了一个决策规则,用于判断不同属性值的记录应该属于哪一个分支。在决策树中房地产用地比重、建设用地比重和城市扩张程度等变量对分类结果有较大的影响。
点击标题查阅往期内容
数据分享|R语言逻辑回归、Naive Bayes贝叶斯、决策树、随机森林算法预测心脏病
左右滑动查看更多
01
02
03
04
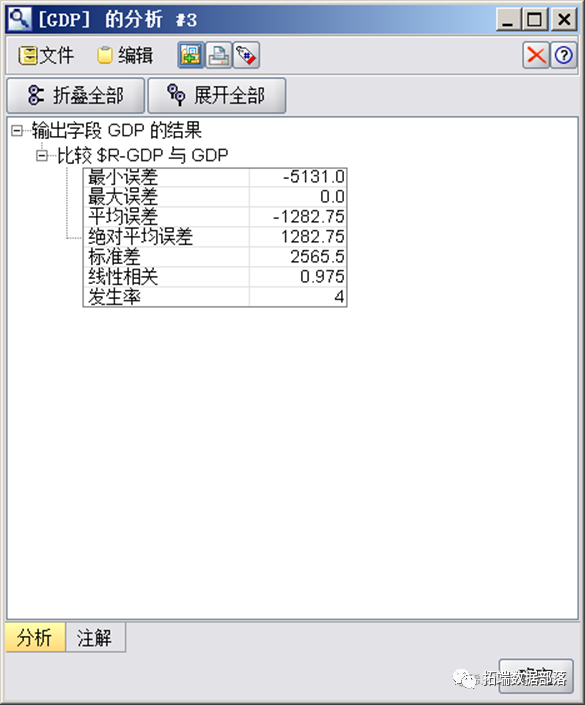
为了检验CHAID决策树模型的性能,我们采用随机抽样的方法将数据集分为训练集和测试集,然后利用训练集来训练模型,并使用测试集来验证模型的预测精度。
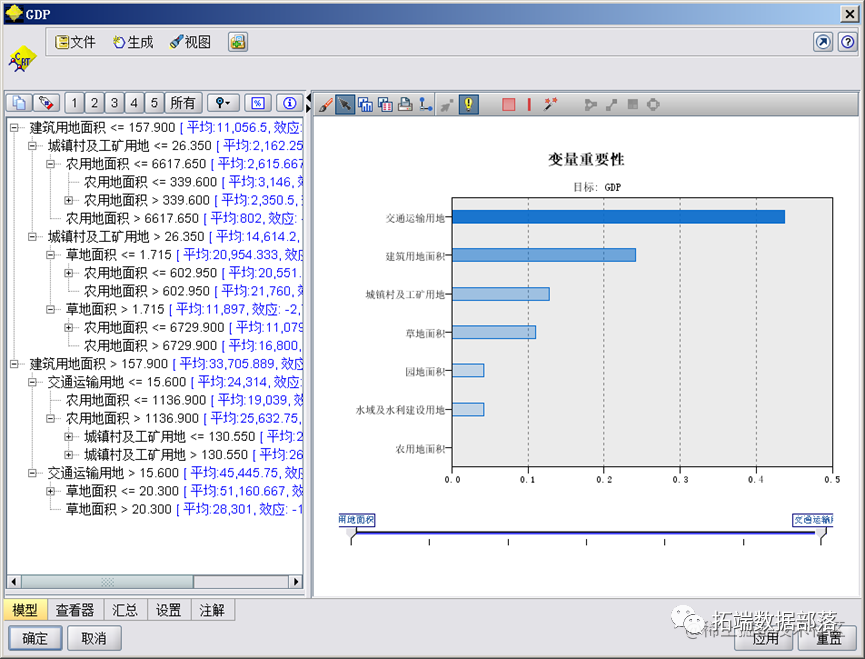
除了使用CHAID决策树算法外,本文还采用了CART决策树算法对数据进行建模。通过SPSS Modeler的C&RT节点进行计算,得到以下变量重要性和决策树结构。 变量重要性在CART决策树算法中,我们使用基尼指数(Gini Index)来衡量每个变量的重要性。具体而言,基尼指数越小,则该变量在分类中起到的作用越大。在本文的分析中,最具有代表性的变量是交通、建筑和工矿用地面积。
通过CART决策树算法,我们得到了以下的决策树模型。在该模型中,每个内部节点代表一个判断规则,而每个叶子节点代表一个分类。最终的分类结果与CHAID决策树模型比较相似,也可提供对土地利用管理的一些启示。
同样采用随机抽样的方法将数据集分为训练集和测试集,使用训练集训练模型,并使用测试集验证模型预测的准确性。
最终我们得到了以下结果文件:
本文旨在应用SPSS Modeler,采用K-means(K-均值)聚类、CHAID、CART决策树等方法,对31个省市的土地利用情况数据进行分析和建模,并为科学有效的土地利用规划和管理策略提供参考。通过聚类和决策树分析,我们得出以下结论: 1.不同省市的土地利用存在显著差异,按主要利用类型可分为5类; 2.交通、建筑用地面积比重是主要影响土地利用的因素; 3.通过CHAID和CART决策树算法,我们可以较精确地对不同地区的土地利用进行分类,并提出相应的管理建议。 本文的研究结论对于全国土地资源的利用和管理具有一定的参考价值,其方法也可以在其他领域中得到应用和推广。
点击文末“阅读原文” 获取全文完整代码数据资料。 本文选自《SPSS Modeler用K-means(K-均值)聚类、CHAID、CART决策树分析31省市土地利用情况数据》。 点击标题查阅往期内容 K-means和层次聚类分析癌细胞系微阵列数据和树状图可视化比较 KMEANS均值聚类和层次聚类:亚洲国家地区生活幸福质量异同可视化分析和选择最佳聚类数 PYTHON实现谱聚类算法和改变聚类簇数结果可视化比较 有限混合模型聚类FMM、广义线性回归模型GLM混合应用分析威士忌市场和研究专利申请数据 R语言多维数据层次聚类散点图矩阵、配对图、平行坐标图、树状图可视化城市宏观经济指标数据 r语言有限正态混合模型EM算法的分层聚类、分类和密度估计及可视化 Python Monte Carlo K-Means聚类实战研究 R语言k-Shape时间序列聚类方法对股票价格时间序列聚类 R语言对用电负荷时间序列数据进行K-medoids聚类建模和GAM回归 R语言谱聚类、K-MEANS聚类分析非线性环状数据比较 R语言实现k-means聚类优化的分层抽样(Stratified Sampling)分析各市镇的人口 R语言聚类有效性:确定最优聚类数分析IRIS鸢尾花数据和可视化 Python、R对小说进行文本挖掘和层次聚类可视化分析案例 R语言k-means聚类、层次聚类、主成分(PCA)降维及可视化分析鸢尾花iris数据集 R语言有限混合模型(FMM,finite mixture model)EM算法聚类分析间歇泉喷发时间 R语言用温度对城市层次聚类、kmean聚类、主成分分析和Voronoi图可视化 R语言k-Shape时间序列聚类方法对股票价格时间序列聚类 R语言中的SOM(自组织映射神经网络)对NBA球员聚类分析 R语言复杂网络分析:聚类(社区检测)和可视化 R语言中的划分聚类模型 基于模型的聚类和R语言中的高斯混合模型 r语言聚类分析:k-means和层次聚类 SAS用K-Means 聚类最优k值的选取和分析 用R语言进行网站评论文本挖掘聚类 基于LDA主题模型聚类的商品评论文本挖掘 R语言鸢尾花iris数据集的层次聚类分析 R语言对用电负荷时间序列数据进行K-medoids聚类建模和GAM回归 R语言聚类算法的应用实例
|




















【本文地址】