通过实例理解决策树算法(ID3,C4.5,Cart算法) |
您所在的位置:网站首页 › 决策树例题经典案例图文并茂怎么写 › 通过实例理解决策树算法(ID3,C4.5,Cart算法) |
通过实例理解决策树算法(ID3,C4.5,Cart算法)
|
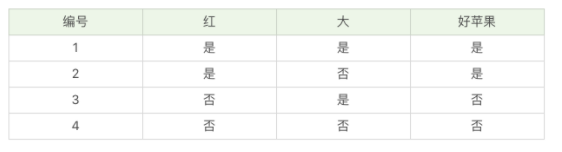
(一)实例:使用ID3算法给出“好苹果”的决策树 构造原理——构造的过程就是选择什么属性作为节点的过程,构造过程中,存在三种节点: 1、根节点:就是树的最顶端,最开始的那个节点; 2、内部节点:就是树中间的那些节点; 3、叶节点:就是树最底部的节点,也就是决策结果。 因此,在构造过程中,我们要解决三个问题: 1、选择哪个属性作为根节点? 2、选择哪些属性作为子节点? 3、什么时候停止并得到目标状态,即叶节点。 剪枝原理——剪枝就是给决策树瘦身,这一步想实现的目标就是,不需要太多的判断,同样可以得到不错的结果。之所以这么做,是为了防止“过拟合”(Overfitting)现象的发生。 “过拟合”是指模型的训练结果“太好了”,以至于在实际应用的过程中,会存在“死板”的情况,导致分类错误。欠拟合,和过拟合就好比是下面这张图中的第一个和第三个情况一样。 预剪枝:是在决策树构造时就进行剪枝。 方法是:在构造的过程中对节点进行评估,如果对某个节点进行划分,在验证集中不能带来准确性的提升,那么对这个节点进行划分就没有意义,这时就会把当前节点作为叶节点,不对其进行划分。 后剪枝就是在生成决策树之后再进行剪枝,通常会从决策树的叶节点开始,逐层向上对每个节点进行评估。如果剪掉这个节点子树,与保留该节点子树在分类准确性上差别不大,或者剪掉该节点子树,能在验证集中带来准确性的提升,那么就可以把该节点子树进行剪枝。 方法是:用这个节点子树的叶子节点来替代该节点,类标记为这个节点子树中最频繁的那个类。 (三)实战 纯度:你可以把决策树的构造过程理解成为寻找纯净划分的过程。数学上,我们可以用纯度来表示,纯度换一种方式来解释就是让目标变量的分歧最小。 信息熵:表示了信息的不确定度,当不确定性越大时,它所包含的信息量也就越大,信息熵也就越高。p(i|t) 代表了节点 t 为分类 i 的概率。 我们在构造决策树的时候,会基于纯度来构建。而经典的 “不纯度”的指标有三种,分别是信息增益(ID3 算法)、信息增益率(C4.5 算法)以及基尼指数(Cart 算法)。 ID3 算法计算的是信息增益,信息增益指的就是划分可以带来纯度的提高,信息熵的下降。它的计算公式,是父亲节点的信息熵减去所有子节点的信息熵。在计算的过程中,我们会计算每个子节点的归一化信息熵,即按照每个子节点在父节点中出现的概率,来计算这些子节点的信息熵。所以信息增益的公式可以表示为: (四)ID3和C4.5算法的优缺点 ID3 优点:方法简单 缺点:对噪声比较敏感,训练集如果有少量错误,可能会导致决策树的分类错误 C4.5 优点:在ID3算法的基础上进行改进,解决了噪声敏感问题,并且可以对决策树进行剪枝,处理连续数值和数值缺失情况 缺点:由于需要对数据集进行多次扫描,效率较低 (五)CART,一棵是回归树,另一棵是分类树 CART 算法,英文全称叫做 Classification And Regression Tree,中文叫做分类回归树。ID3 和 C4.5 算法可以生成二叉树或多叉树,而 CART 只支持二叉树。同时 CART 决策树比较特殊,既可以作分类树,又可以作回归树。 ID3 是基于信息增益做判断,C4.5 在 ID3 的基础上做了改进,提出了信息增益率的概念。实际上 CART 分类树与 C4.5 算法类似,只是属性选择的指标采用的是基尼系数。基尼系数本身反应了样本的不确定度。当基尼系数越小的时候,说明样本之间的差异性小,不确定程度低。分类的过程本身是一个不确定度降低的过程,即纯度的提升过程。所以 CART 算法在构造分类树的时候,会选择基尼系数最小的属性作为属性的划分。 假设 t 为节点,那么该节点的 GINI 系数的计算公式为: 如何使用CART算法创建分类树? 在 Python 的 sklearn 中,如果我们想要创建 CART 分类树,可以直接使用 DecisionTreeClassifier 这个类。创建这个类的时候,默认情况下 criterion 这个参数等于 gini,也就是按照基尼系数来选择属性划分,即默认采用的是 CART 分类树。 # encoding=utf-8 from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score from sklearn.tree import DecisionTreeClassifier from sklearn.datasets import load_iris # 准备数据集 iris=load_iris() # 获取特征集和分类标识 features = iris.data labels = iris.target # 随机抽取33%的数据作为测试集,其余为训练集 train_features, test_features, train_labels, test_labels = train_test_split(features, labels, test_size=0.33, random_state=0) # 创建CART分类树 clf = DecisionTreeClassifier(criterion='gini') # 拟合构造CART分类树 clf = clf.fit(train_features, train_labels) # 用CART分类树做预测 test_predict = clf.predict(test_features) # 预测结果与测试集结果作比对 score = accuracy_score(test_labels, test_predict) print("CART分类树准确率 %.4lf" % score)运行结果: CART分类树准确率 0.9600CART 决策树,它是一棵决策二叉树,既可以做分类树,也可以做回归树。作为分类树,CART 采用基尼系数作为节点划分的依据,得到的是离散的结果,也就是分类结果;作为回归树,CART 可以采用最小绝对偏差(LAD),或者最小二乘偏差(LSD)作为节点划分的依据,得到的是连续值,即回归预测结果。 如何使用CART回归树做预测? # encoding=utf-8 from sklearn.metrics import mean_squared_error from sklearn.model_selection import train_test_split from sklearn.datasets import load_boston from sklearn.metrics import r2_score,mean_absolute_error,mean_squared_error from sklearn.tree import DecisionTreeRegressor # 准备数据集 boston=load_boston() # 探索数据 print(boston.feature_names) # 获取特征集和房价 features = boston.data prices = boston.target # 随机抽取33%的数据作为测试集,其余为训练集 train_features, test_features, train_price, test_price = train_test_split(features, prices, test_size=0.33) # 创建CART回归树 dtr=DecisionTreeRegressor() # 拟合构造CART回归树 dtr.fit(train_features, train_price) # 预测测试集中的房价 predict_price = dtr.predict(test_features) # 测试集的结果评价 print('回归树二乘偏差均值:', mean_squared_error(test_price, predict_price)) print('回归树绝对值偏差均值:', mean_absolute_error(test_price, predict_price))运行结果: ['CRIM' 'ZN' 'INDUS' 'CHAS' 'NOX' 'RM' 'AGE' 'DIS' 'RAD' 'TAX' 'PTRATIO' 'B' 'LSTAT'] 回归树二乘偏差均值: 27.082275449101797 回归树绝对值偏差均值: 3.396407185628743最后我们来整理下三种决策树之间在属性选择标准上的差异: ID3 算法,基于信息增益做判断; C4.5 算法,基于信息增益率做判断; CART 算法,分类树是基于基尼系数做判断。回归树是基于偏差做判断。 |
 (二)决策树的工作原理 我们在做决策树的时候,会经历两个阶段:构造和剪枝。
(二)决策树的工作原理 我们在做决策树的时候,会经历两个阶段:构造和剪枝。 剪枝的具体方法有预剪枝和后剪枝两种。
剪枝的具体方法有预剪枝和后剪枝两种。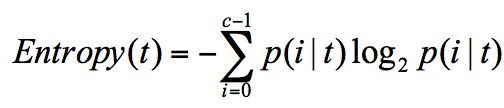 两者之间的关系:信息熵越大,纯度越低。当集合中的所有样本均匀混合时,信息熵最大,纯度最低。
两者之间的关系:信息熵越大,纯度越低。当集合中的所有样本均匀混合时,信息熵最大,纯度最低。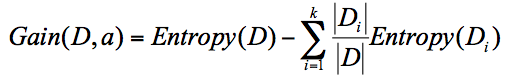 公式中 D 是父亲节点,Di 是子节点,Gain(D,a) 中的 a 作为 D 节点的属性选择。 分析步骤: (1)将苹果红不红作为属性划分,即表示为Gain(D,是否红),会有两个叶子节点D1,D2,分别对应的是红和不红。我们用+代表是个好苹果,-代表不是个好苹果,那么 D1(红)={1+,2+} D2(不红) ={3-,4-} 计算根节点的信息熵及这两个叶子节点的信息熵:
公式中 D 是父亲节点,Di 是子节点,Gain(D,a) 中的 a 作为 D 节点的属性选择。 分析步骤: (1)将苹果红不红作为属性划分,即表示为Gain(D,是否红),会有两个叶子节点D1,D2,分别对应的是红和不红。我们用+代表是个好苹果,-代表不是个好苹果,那么 D1(红)={1+,2+} D2(不红) ={3-,4-} 计算根节点的信息熵及这两个叶子节点的信息熵:  因为 D1 有 2 个记录,D2 有 2 个记录,所以 D 中的记录一共是 2+2=4,即总数为 4。所以 D1 在 D(父节点)中的概率是 1/2,D2 在父节点的概率是 1/2。那么作为子节点的归一化信息熵 = 1/2x0+1/2x0=0。 因为我们用 ID3 中的信息增益来构造决策树,所以要计算每个节点的信息增益。 是否红作为属性节点的信息增益为,Gain(D , 是否红)=1-0=1。 (2)同理,将苹果大不大作为属性划分,即表示为Gain(D,是否大),会有两个叶子节点D1,D2,分别对应的是大和不大。我们用+代表是个好苹果,-代表不是个好苹果,那么 D1(大)={1+,3-} D2(不大) ={2+,4-} 计算根节点的信息熵及这两个叶子节点的信息熵:
因为 D1 有 2 个记录,D2 有 2 个记录,所以 D 中的记录一共是 2+2=4,即总数为 4。所以 D1 在 D(父节点)中的概率是 1/2,D2 在父节点的概率是 1/2。那么作为子节点的归一化信息熵 = 1/2x0+1/2x0=0。 因为我们用 ID3 中的信息增益来构造决策树,所以要计算每个节点的信息增益。 是否红作为属性节点的信息增益为,Gain(D , 是否红)=1-0=1。 (2)同理,将苹果大不大作为属性划分,即表示为Gain(D,是否大),会有两个叶子节点D1,D2,分别对应的是大和不大。我们用+代表是个好苹果,-代表不是个好苹果,那么 D1(大)={1+,3-} D2(不大) ={2+,4-} 计算根节点的信息熵及这两个叶子节点的信息熵:  因为 D1 有 2 个记录,D2 有 2 个记录,所以 D 中的记录一共是 2+2=4,即总数为 4。所以 D1 在 D(父节点)中的概率是 1/2,D2 在父节点的概率是 1/2。那么作为子节点的归一化信息熵 = 1/2x1+1/2x1=1。 是否大作为属性节点的信息增益为,Gain(D , 是否大)=1-1=0。 我们能看出来是否红作为属性的信息增益最大。因为 ID3 就是要将信息增益最大的节点作为父节点,这样可以得到纯度高的决策树,所以我们将是否红作为根节点。接着,我们将是否大作为节点的属性划分,其决策树状图分裂为下图所示:
因为 D1 有 2 个记录,D2 有 2 个记录,所以 D 中的记录一共是 2+2=4,即总数为 4。所以 D1 在 D(父节点)中的概率是 1/2,D2 在父节点的概率是 1/2。那么作为子节点的归一化信息熵 = 1/2x1+1/2x1=1。 是否大作为属性节点的信息增益为,Gain(D , 是否大)=1-1=0。 我们能看出来是否红作为属性的信息增益最大。因为 ID3 就是要将信息增益最大的节点作为父节点,这样可以得到纯度高的决策树,所以我们将是否红作为根节点。接着,我们将是否大作为节点的属性划分,其决策树状图分裂为下图所示:  综上所述,我们可以得到结论,是否红作为最优属性,红的就是好苹果,不红就不是好苹果。
综上所述,我们可以得到结论,是否红作为最优属性,红的就是好苹果,不红就不是好苹果。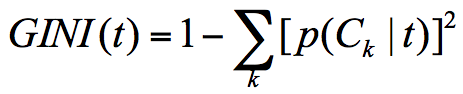 这里 p(Ck|t) 表示节点 t 属于类别 Ck 的概率,节点 t 的基尼系数为 1 减去各类别 Ck 概率平方和。
这里 p(Ck|t) 表示节点 t 属于类别 Ck 的概率,节点 t 的基尼系数为 1 减去各类别 Ck 概率平方和。【本文地址】
今日新闻 |
推荐新闻 |