pandas文件读取和写入 |
您所在的位置:网站首页 › 写入csv文件的函数 › pandas文件读取和写入 |
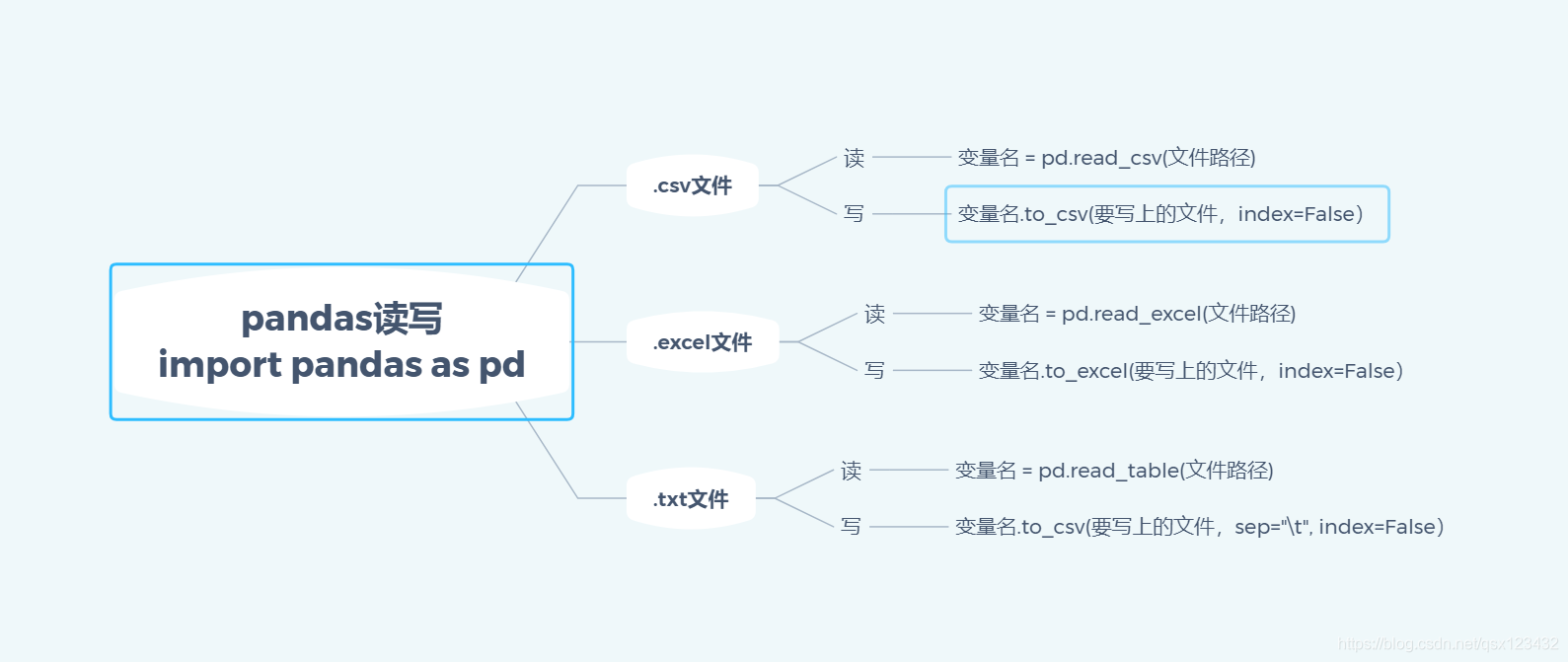
pandas文件读取和写入
pandas对文件的读取和写入
通用流程pandas文件读取读.csv文件读.txt文件读.excel文件
pandas文件写入写.csv文件写.txt文件写.excel文件把表格快速转换为 markdown 和 latex 语言
预览图片:
 下面将从文件的角度来记录文件的读写操作。(个人理解,请指正)
通用流程
导入库 import pandas as pd找到文件所在位置(绝对路径 = 全称)(相对路径 = 和程序在同一个文件夹中的路径的简称)变量名 = pd.读写操作方法(文件路径,具体的筛选条件,……)
pandas文件读取
读.csv文件
import pandas as pd
data_path =r"F:\joyful-pandas-master\data\my_csv.csv"
data = pd.read_csv(data_path)
print(data)
下面将从文件的角度来记录文件的读写操作。(个人理解,请指正)
通用流程
导入库 import pandas as pd找到文件所在位置(绝对路径 = 全称)(相对路径 = 和程序在同一个文件夹中的路径的简称)变量名 = pd.读写操作方法(文件路径,具体的筛选条件,……)
pandas文件读取
读.csv文件
import pandas as pd
data_path =r"F:\joyful-pandas-master\data\my_csv.csv"
data = pd.read_csv(data_path)
print(data)
原文件: 读取结果: col1 col2 col3 col4 col5 0 2 a 1.4 apple 2020/1/1 1 3 b 3.4 banana 2020/1/2 2 6 c 2.5 orange 2020/1/5 3 5 d 3.2 lemon 2020/1/7#解释:这里在确定文件位置时,用到了r" ",这样就不会发生程序上歧义了。 显然直接读取之后,发现文件的第一列作为了表头,如果不希望这样,需要加限定条件:header = None import pandas as pd data_path =r"F:\joyful-pandas-master\data\my_csv.csv" data = pd.read_csv(data_path, header=None) print(data)运行结果: 0 1 2 3 4 0 col1 col2 col3 col4 col5 1 2 a 1.4 apple 2020/1/1 2 3 b 3.4 banana 2020/1/2 3 6 c 2.5 orange 2020/1/5 4 5 d 3.2 lemon 2020/1/7如果我们想把某一列作为索引下标,则使用: index_col = [ 下标_列(作为下标的列) ] import pandas as pd data_path =r"F:\joyful-pandas-master\data\my_csv.csv" data = pd.read_csv(data_path, index_col=["col2", "col4"]) print(data)运行结果: col1 col3 col5 --》作为表头的列 col2 col4 a apple 2 1.4 2020/1/1 b banana 3 3.4 2020/1/2 c orange 6 2.5 2020/1/5 d lemon 5 3.2 2020/1/7 【选出来作为下标的列】如果要单独文件中的某几列(而非全部信息),则使用: usecols = [ 使用(哪几)列 ] import pandas as pd data_path =r"F:\joyful-pandas-master\data\my_csv.csv" data = pd.read_csv(data_path, usecols=["col2", "col4"]) print(data)运行结果: col2 col4 表头元素 0 a apple 1 b banana 2 c orange 3 d lemon 下标 内容如果要把时间字符串变成真正的时间,则需要让时间字符串所在的列,提出来放入 parse_dates中: parse_dates=[时间字符串所在的列名] import pandas as pd data_path =r"F:\joyful-pandas-master\data\my_csv.csv" data = pd.read_csv(data_path, parse_dates=["col5"]) print(data)运行结果: col1 col2 col3 col4 col5 0 2 a 1.4 apple 2020-01-01 1 3 b 3.4 banana 2020-01-02 2 6 c 2.5 orange 2020-01-05 3 5 d 3.2 lemon 2020-01-07 原本col5中时间字符串,通过这种操作,把它变成了时间。如果指定读取几行数据,则用 nrows=要读取的行数 注意:这里指的是文件读取过程,而不是从已读取的文件中选择某几行。 import pandas as pd data_path =r"F:\joyful-pandas-master\data\my_csv.csv" data = pd.read_csv(data_path, nrows=2) print(data)运行结果: col1 col2 col3 col4 col5 0 2 a 1.4 apple 2020/1/1 1 3 b 3.4 banana 2020/1/2 读.txt文件变量名 = pd.read_table(文件路径\文件名) import pandas as pd data_path =r"F:\joyful-pandas-master\data\my_table.txt" data = pd.read_table(data_path) print(data)原文件数据: 如果要用read_csv()读取txt文件,需要进行分割符设置。 # 不设置分割符 data = pd.read_csv(data_path) print(data) 运行结果: col1\tcol2\tcol3\tcol4 0 2\ta\t1.4\tapple 2020/1/1 1 3\tb\t3.4\tbanana 2020/1/2 2 6\tc\t2.5\torange 2020/1/5 3 5\td\t3.2\tlemon 2020/1/7设置分割符:sep = “分割条件”,常见的是空格分割:sep = "\t" sep = separate(分割) # 设置分隔符 data = pd.read_csv(data_path, sep="\t") print(data) 运行结果: col1 col2 col3 col4 0 2 a 1.4 apple 2020/1/1 1 3 b 3.4 banana 2020/1/2 2 6 c 2.5 orange 2020/1/5 3 5 d 3.2 lemon 2020/1/7特殊的分割方式,sep = “正则表达筛选条件”,此时需要设置,引擎方式(engine=“python”) 比如: 如果不设置分割方式: data = pd.read_table(data_path, engine="python") print(data) 运行结果: col1 |||| col2 0 TS |||| This is an apple. 1 GQ |||| My name is Bob. 2 WT |||| Well done! 3 PT |||| May I help you?如果不设置引擎方式(保留分割方式) data = pd.read_table(data_path, sep="\|"*4) print(data) 运行结果: ParserWarning:会有警告提示 Falling back to the 'python' engine because the 'c' engine does not support regex separators (separators > 1 char and different from '\s+' are interpreted as regex); you can avoid this warning by specifying engine='python'.return read_csv(**locals()) col1 col2 0 TS This is an apple. 1 GQ My name is Bob. 2 WT Well done! 3 PT May I help you?如果以上两个都没有: data = pd.read_table(data_path) print(data) 运行结果: col1 |||| col2 0 TS |||| This is an apple. 1 GQ |||| My name is Bob. 2 WT |||| Well done! 3 PT |||| May I help you?需要加入某些限定条件进行筛选,类似于read_csv()方法限定条件设置。 读.excel文件变量名 = pd.read_excel(文件路径\文件名) import pandas as pd data_path =r"F:\joyful-pandas-master\data\my_excel.xlsx" data = pd.read_excel(data_path) print(data)
文件读取限定条件,同上 pandas文件写入 写.csv文件变量名.to_csv(文件路径+文件名, index = 通常设置成False) import pandas as pd data_read_path =r"F:\joyful-pandas-master\data\my_csv.csv" data_write_path = r"F:\joyful-pandas-master\data\my_csv_saved.csv" data = pd.read_csv(data_read_path) data.to_csv(data_write_path, index=False) # 此时不能打开被写的文件data.to_csv(data_write_path, index=False) 把data中的数据 ,写入到data_write_path 中,且设置去除索引操作。 写.txt文件写txt文件使用的是: .to_csv()方法 记得设置分割方式:sep data.to_csv('data/my_txt_saved.txt', sep='\t', index=False) 写.excel文件 data.to_excel('data/my_excel_saved.xlsx', index=False) 把表格快速转换为 markdown 和 latex 语言 先安装tabulate库表格文件名.to_markdown() 或者 表格文件名…to_latex() |

 运行结果:
运行结果:
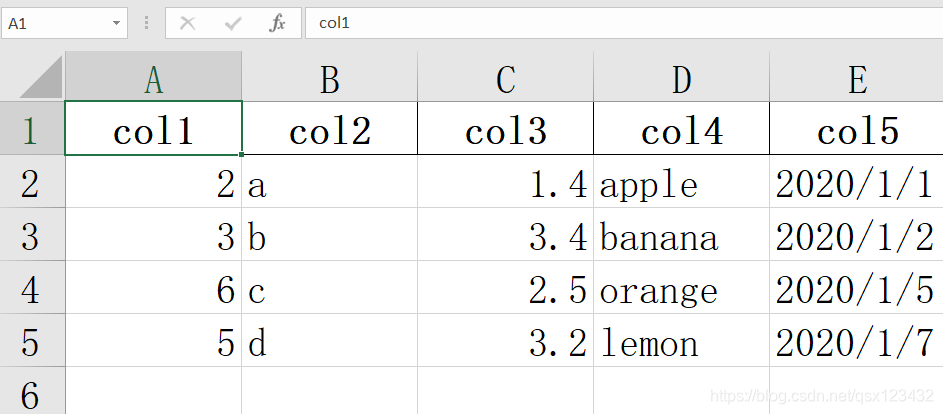 运行结果:
运行结果:【本文地址】
今日新闻 |
推荐新闻 |