23、hadoop集群中yarn运行mapreduce的内存、CPU分配调度计算与优化 |
您所在的位置:网站首页 › 内存计算引擎 › 23、hadoop集群中yarn运行mapreduce的内存、CPU分配调度计算与优化 |
23、hadoop集群中yarn运行mapreduce的内存、CPU分配调度计算与优化
|
Hadoop系列文章目录
1、hadoop3.1.4简单介绍及部署、简单验证 2、HDFS操作 - shell客户端 3、HDFS的使用(读写、上传、下载、遍历、查找文件、整个目录拷贝、只拷贝文件、列出文件夹下文件、删除文件及目录、获取文件及文件夹属性等)-java 4、HDFS-java操作类HDFSUtil及junit测试(HDFS的常见操作以及HA环境的配置) 5、HDFS API的RESTful风格–WebHDFS 6、HDFS的HttpFS-代理服务 7、大数据中常见的文件存储格式以及hadoop中支持的压缩算法 8、HDFS内存存储策略支持和“冷热温”存储 9、hadoop高可用HA集群部署及三种方式验证 10、HDFS小文件解决方案–Archive 11、hadoop环境下的Sequence File的读写与合并 12、HDFS Trash垃圾桶回收介绍与示例 13、HDFS Snapshot快照 14、HDFS 透明加密KMS 15、MapReduce介绍及wordcount 16、MapReduce的基本用法示例-自定义序列化、排序、分区、分组和topN 17、MapReduce的分区Partition介绍 18、MapReduce的计数器与通过MapReduce读取/写入数据库示例 19、Join操作map side join 和 reduce side join 20、MapReduce 工作流介绍 21、MapReduce读写SequenceFile、MapFile、ORCFile和ParquetFile文件 22、MapReduce使用Gzip压缩、Snappy压缩和Lzo压缩算法写文件和读取相应的文件 23、hadoop集群中yarn运行mapreduce的内存、CPU分配调度计算与优化 文章目录 Hadoop系列文章目录一、概述二、内存分配计算1、人工计算2、辅助计算3、修改hadoop配置1)、yarn-site.xml2)、mapred-site.xml3)、其他参数配置 三、CPU分配计算四、其他优化1、Map阶段2、Reduce阶段3、IO传输4、整体本文介绍在hadoop集群中,不适用默认的参数情况下,yarn的cpu和内容配置。 本文依赖是hadoop集群正常运行。 本文分为3个部分,即概述、cpu和内存配置。 一、概述 hadoop yarn支持内存与CPU两种资源的调度方式。YARN作为一个资源调度器,应该考虑到集群里面每一台机子的计算资源,然后根据application申请的资源进行分配Container。Container是YARN里面资源分配的基本单位,具有一定的内存以及CPU资源。在YARN集群中,平衡内存、CPU、磁盘的资源的很重要的,根据经验,每两个container使用一块磁盘以及一个CPU核的时候可以使集群的资源得到一个比较好的利用。 主要涉及参数有 yarn.nodemanager.resource.memory-mb yarn.scheduler.minimum-allocation-mb yarn.scheduler.maximum-allocation-mb yarn.app.mapreduce.am.resource.mb yarn.app.mapreduce.am.command-opts mapreduce.map.memory.mb mapreduce.reduce.memory.mb mapreduce.map.java.opts mapreduce.reduce.java.opts 二、内存分配计算本文介绍2种配置方式,即通过已知的硬件资源进行人工计算和由辅助工具进行计算。需要说明的是,该计算仅是方向性的计算,可以确保不出现大资源浪费或因配置不当导致环境不可用情况。即便本文的2种配置方式,结果还是不同的。 此处计算的就是根据已有的硬件配置(即cpu核心数、磁盘个数、内存数)计算该环境中有多少contaiers和每个contaier有多少内存。 1、人工计算关于 内存 相关的配置可以参考hortonwork公司的文档 Determine HDP Memory Configuration Settings 来配置集群。 YARN以及MAPREDUCE所有可用的内存资源应该要除去操作系统运行需要的以及其他的hadoop的一些程序需要的,总共剩余的内存=操作系统内存+HBASE内存。 可以参考下面的表格确定应该保留的内存: 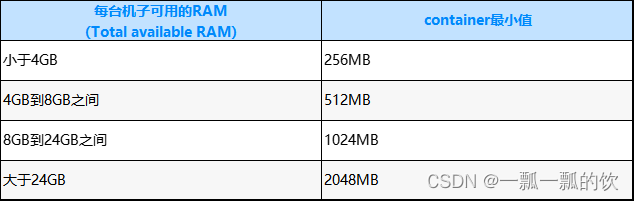 每个container的平均使用内存大小计算方式为: RAM-per-container = max (MIN_CONTAINER_SIZE, Total Available RAM / containers ) 通过上面的计算,YARN以及MAPREDUCE可以这样配置: 每个container的平均使用内存大小计算方式为: RAM-per-container = max (MIN_CONTAINER_SIZE, Total Available RAM / containers ) 通过上面的计算,YARN以及MAPREDUCE可以这样配置:  示例: 每个节点128G内存、32核CPU的机器,挂载了7个磁盘 根据上面的说明,操作系统保留内存为24G,不使用HBase情况下,系统剩余可用内存(Total available RAM)为104G=128G-24G 示例: 每个节点128G内存、32核CPU的机器,挂载了7个磁盘 根据上面的说明,操作系统保留内存为24G,不使用HBase情况下,系统剩余可用内存(Total available RAM)为104G=128G-24G  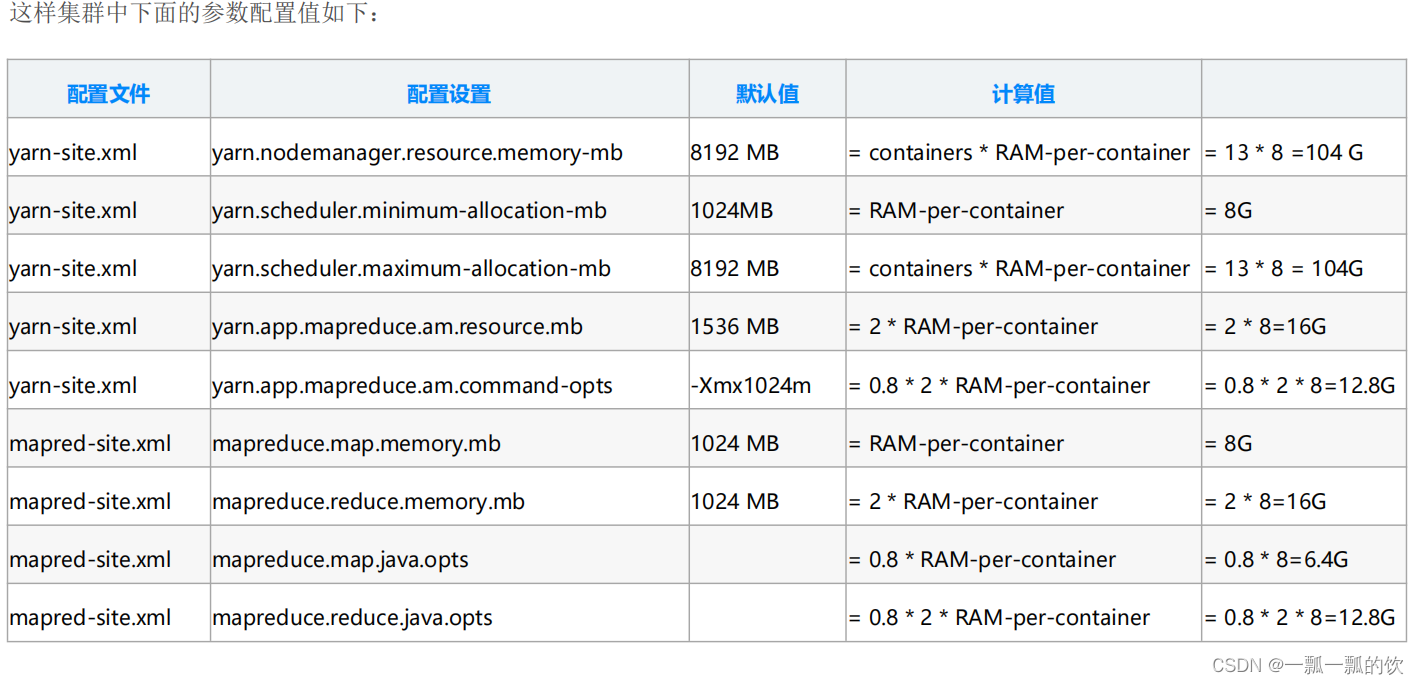 2、辅助计算
2、辅助计算
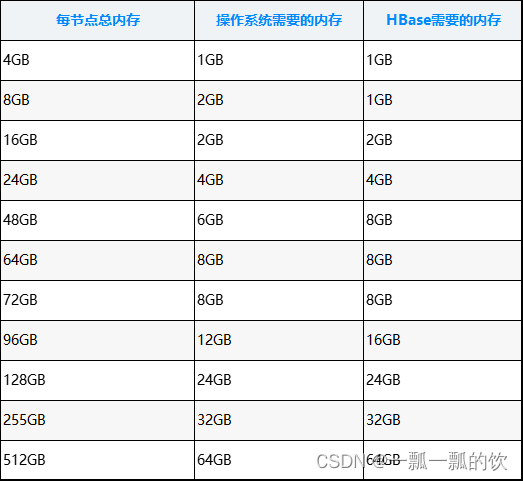
该处的计算结果与上文中的人工计算数据有差异,但总体方向上是一致的。 用法: python hdp-configuration-utils.py -c 16 -m 64 -d 4 -k True 参数说明 -c CORES 节点CPU核心数. -m MEMORY 节点总内存G. -d DISKS 节点磁盘数 -k HBASE 集群内有安装Hbase则参数"True" ,否则"False" hdp-configuration-utils.py 源码如下: #!/usr/bin/env python ''' Licensed to the Apache Software Foundation (ASF) under one or more contributor license agreements. See the NOTICE file distributed with this work for additional information regarding copyright ownership. The ASF licenses this file to you under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. ''' ########################################################################################### # # 用法: python hdp-configuration-utils.py -c 16 -m 64 -d 4 -k True # # -c CORES The number of cores on each host. # -m MEMORY The amount of memory on each host in GB. # -d DISKS The number of disks on each host. # -k HBASE "True" if HBase is installed, "False" if not. # # https://docs.hortonworks.com/HDPDocuments/HDP2/HDP-2.3.4/bk_installing_manually_book/content/determine-hdp-memory-config.html # ########################################################################################### import optparse from pprint import pprint import logging import sys import math import ast ''' Reserved for OS + DN + NM, Map: Memory => Reservation ''' reservedStack = { 4:1, 8:2, 16:2, 24:4, 48:6, 64:8, 72:8, 96:12, 128:24, 256:32, 512:64} ''' Reserved for HBase. Map: Memory => Reservation ''' reservedHBase = {4:1, 8:1, 16:2, 24:4, 48:8, 64:8, 72:8, 96:16, 128:24, 256:32, 512:64} GB = 1024 def getMinContainerSize(memory): if (memory 3)、其他参数配置 yarn.nodemanager.vmem-pmem-ratio 任务每使用1MB物理内存,最多可使用虚拟内存量,默认是2.1。当一个map任务总共分配的物理内存为8G的时候,该任务的container最多内分配的堆内存为6.4G,可以分配的虚拟内存上限为8*2.1=16.8G。另外,照这样算下去,每个节点上YARN可以启动的Map数为104/8=13个,似乎偏少了,这主要是和我们挂载的磁盘数太少了有关,人为的调整 RAM-per-container 的值为4G或者更小的一个值是否更合理呢?当然,这个要监控集群实际运行情况来决定了。yarn.nodemanager.pmem-check-enabled 是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true。yarn.nodemanager.vmem-pmem-ratio 是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true。 Ratio between virtual memory to physical memory when setting memory limits for containers. Container allocations are expressed in terms of physical memory, and virtual memory usage is allowed to exceed this allocation by this ratio. yarn.nodemanager.vmem-pmem-ratio 2.1完成以上配置后,需要将配置文件复制到hadoop集群上所有的机器上,并重启集群。 三、CPU分配计算YARN中目前的CPU被划分成虚拟CPU(CPU virtual Core),这里的虚拟CPU是YARN自己引入的概念,考虑到不同节点的CPU性能可能不同,每个CPU具有的计算能力也是不一样的,比如某个物理CPU的计算能力可能是另外一个物理CPU的2倍,这时候,你可以通过为第一个物理CPU多配置几个虚拟CPU弥补这种差异。用户提交作业时,可以指定每个任务需要的虚拟CPU个数。 在YARN中,CPU相关配置参数如下: yarn.nodemanager.resource.cpu-vcores 表示该节点上YARN可使用的虚拟CPU个数,默认是8,注意,目前推荐将该值设值为与物理CPU核数数目相同。如果你的节点CPU核数不够8个,则需要调减小这个值,而YARN不会智能的探测节点的物理CPU总数。yarn.scheduler.minimum-allocation-vcores 单个任务可申请的最小虚拟CPU个数,默认是1,如果一个任务申请的CPU个数少于该数,则该对应的值改为这个数。yarn.scheduler.maximum-allocation-vcores 单个任务可申请的最多虚拟CPU个数,默认是32。对于一个CPU核数较多的集群来说,上面的默认配置显然是不合适的,在测试集群中,4个节点每个机器CPU核数为4,可以配置为 # yarn-site.xml yarn.nodemanager.resource.cpu-vcores 4 yarn.scheduler.maximum-allocation-vcores 128 四、其他优化 1、Map阶段 增大环形缓冲区大小。由100m扩大到200m增大环形缓冲区溢写的比例。由80%扩大到90%减少对溢写文件的merge次数。(10个文件,一次20个merge)不影响实际业务的前提下,采用Combiner提前合并,减少 I/O 2、Reduce阶段 合理设置Map和Reduce数:两个都不能设置太少,也不能设置太多。太少,会导致Task等待,延长处理时间;太多,会导致 Map、Reduce任务间竞争资源,造成处理超时等错误设置Map、Reduce共存:调整slowstart.completedmaps参数,使Map运行到一定程度后,Reduce也开始运行,减少Reduce的等待时间规避使用Reduce,因为Reduce在用于连接数据集的时候将会产生大量的网络消耗增加每个Reduce去Map中拿数据的并行数集群性能可以的前提下,增大Reduce端存储数据内存的大小 3、IO传输采用数据压缩的方式,减少网络IO的的时间。 安装Snappy和LZOP压缩编码器。 map输入端主要考虑数据量大小和切片,支持切片的有Bzip2、LZO。注意:LZO要想支持切片必须创建索引;map输出端主要考虑速度,速度快的snappy、LZO;reduce输出端主要看具体需求,例如作为下一个mr输入需要考虑切片,永久保存考虑压缩率比较大的gzip。 4、整体 yarn.nodemanager.resource.memory-mb NodeManager默认内存8G,需要根据服务器实际配置灵活调整,例如128G内存,配置为100G内存左右yarn.scheduler.maximum-allocation-mb 单任务默认内存8G,需要根据该任务的数据量灵活调整,例如128m数据,配置1G内存mapreduce.map.memory.mb 控制分配给MapTask内存上限,如果超过会kill掉进程(报:Container is running beyond physical memory limits. Current usage:565MB of512MB physical memory used;Killing Container)。默认内存大小为1G,如果数据量是128m,正常不需要调整内存;如果数据量大于128m,可以增加MapTask内存,最大可以增加到4-5g。mapreduce.reduce.memory.mb 控制分配给ReduceTask内存上限。默认内存大小为1G,如果数据量是128m,正常不需要调整内存;如果数据量大于128m,可以增加ReduceTask内存大小为4-5g。mapreduce.map.java.opts 控制MapTask堆内存大小。(如果内存不够,报:java.lang.OutOfMemoryError)mapreduce.reduce.java.opts 控制ReduceTask堆内存大小。(如果内存不够,报:java.lang.OutOfMemoryError)可以增加MapTask的CPU核数,增加ReduceTask的CPU核数增加每个Container的CPU核数和内存大小在hdfs-site.xml文件中配置多目录(多磁盘)NameNode有一个工作线程池,用来处理不同DataNode的并发心跳以及客户端并发的元数据操作。dfs.namenode.handler.count=20 * log2 (Cluster Size),比如集群规模为10台时,此参数设置为60。至此,已经简要介绍了内存和cpu的分配计算方式,和其他的方面的调整方向。 |
 计算每台机子最多可以拥有多少个container,可以使用下面的公式: containers = min ( 2CORES, 1.8DISKS, Total available RAM / MIN_CONTAINER_SIZE) 说明:
计算每台机子最多可以拥有多少个container,可以使用下面的公式: containers = min ( 2CORES, 1.8DISKS, Total available RAM / MIN_CONTAINER_SIZE) 说明:【本文地址】
今日新闻 |
推荐新闻 |