深度解析openpyxl的filters筛选和排序 |
您所在的位置:网站首页 › 关键字排序excel怎么设置的数据 › 深度解析openpyxl的filters筛选和排序 |
深度解析openpyxl的filters筛选和排序
|
openpyxl可以对EXCEL工作添加自动筛选按钮设置筛选和排序条件,但必须运行操作EXCEL才能最终应用筛选和排序。 openpyxl 3.1.2文档https://openpyxl.readthedocs.io/en/stable/filters.html 英文部分是官网文档,中文部分是自己的理解和翻译。并对文档中所有的实例做了复现。 Using filters and sorts设置筛选和排序 It’s possible to filter single range of values in a worksheet by adding an autofilter. If you need to filter multiple ranges, you can use tables and apply a separate filter for each table. 通过添加自动筛选按钮对工作表的一个数值区域进行筛选设置。如果有多个区域要筛选,你可以在表格中为不同的区域设置筛选。 NoteFilters and sorts can only be configured by openpyxl but will need to be applied in applications like Excel. This is because they actually rearrange, format and hide rows in the range. 注意 通过openpyxl可以对表格设置筛选和排序,但需要在EXCEL中操作才能应用筛选和排序。这是因为排序和筛选后的数值区域会被重新排列和格式化,并隐藏区域中不符合条件的行。 To add a filter you define a range and then add columns. You set the range over which the filter by setting the ref attribute. Filters are then applied to columns in the range using a zero-based index, eg. in a range from A1:H10, colId 1 refers to column B. Openpyxl does not check the validity of such assignments. 对定义的区域设置筛选条件并把筛选按钮添加到列。按一定条件所指定的区域,列的索引从0开始,比如,在 A1:A10区域,列1指的是B列。Openpyxl不能给出有效的结果(只设置筛选条件和排序方式,不显示最终结果,要显示最终结果需要在EXCEL应用程序中操作)。 实例及其解析 from openpyxl import Workbook from openpyxl.worksheet.filters import ( FilterColumn, CustomFilter, #可省略,此例中未用到 CustomFilters, #可省略,此例中未用到 DateGroupItem, #可省略,此例中未用到 Filters, ) wb = Workbook() #创建工作簿 ws = wb.active #当前活动的工作表 data = [ ["Fruit","Quantity"], ["Kiwi", 3], ["Grape", 15], ["Apple", 3], ["Peach", 3], ["Pomegranate", 3], ["Pear", 3], ["Tangerine", 3], ["Blueberry", 3], ["Mango", 3], ["Watermelon", 3], ["Blackberry", 3], ["Orange", 3], ["Raspberry", 3], ["Banana", 3], ] for r in data: #添加实例数据 ws.append(r) filters = ws.auto_filter #工作表设置自动筛选 filters.ref = "A1:B15" #筛选区域 col = FilterColumn(colId = 0) #for column A (对A列进行筛选) col.filters = Filters(filter = ["Kiwi", "Apple", "Mango"]) # add selected values(筛选条件,filter的参数是列表) filters.filterColumn.append(col) #add filter to the worksheet(在工作表中添加筛选) ws.auto_filter.add_sort_condition("B2:B15") #B列排序,默认是升序 wb.save("filtered.xlsx") #保存工作簿代码运行结果: 墙裂推荐看运行结果的视频,以理解filters只设置筛选按钮,结果需要在EXCEL中操作。 filtered Advanced filters高级别筛选设置 The following predefined filters can be used: CustomFilter, DateGroupItem, DynamicFilter, ColorFilter, IconFilter and Top10 ColorFilter, IconFilter and Top10 all interact with conditional formats. The signature and structure of the different kinds of filter varies significantly. As such it makes sense to familiarise yourself with either the openpyxl source code or the OOXML specification. 筛选的类,有CustomFilter, DateGroupItem, DynamicFiltr, ColorFilter, IconFilter and Top 10。 其中,ColorFilter, IconFilter and Top 10 ,所有的条件格式相互作用。 不同类型的筛选,名称和结构有着显著的差别。它们都是用户易于理解的,要么是openpyxl源代码,要么是OOXML参数。 CustomFilterCustomFilters can have one or two conditions which will operate either independently (the default), or combined by setting the and_ attribute. Filter can use the following operators: 'equal', 'lessThan', 'lessThanOrEqual', 'notEqual', 'greaterThanOrEqual', 'greaterThan'. CustomFilter可以有一个或者两个条件,每个筛选运算默认是独立的,也可以用“and_”组合。CustomFilter的筛选运算符有qual'(等于), 'lessThan'(小于), 'lessThanOrEqual'(小于等于。),'notEqual'(不等于), 'greaterThanOrEqual'(大于等于), 'greaterThan'(大于)。 实例代码:Filter values < 10 and > 90:(这是官方文档自带的实例,没有创建工作表,没有添加数据,无法运行。完整可运行的实例可参见后面的图书销售统计表筛选,CustomFilter实例。) from openpyxl.worksheet.filters import CustomFilter, CustomFilters flt1 = CustomFilter(operator="lessThan", val=10) flt2 = CustomFilter(operator=greaterThan, val=90) cfs = CustomFilters(customFilter=[flt1, flt2]) col = FilterColumn(colId=2, customFilters=cfs) # apply to **third** column in the range filters.filter.append(col) #To combine the filters: #cfs.and_ = TrueIn addition, Excel has non-standardised functionality for pattern matching with strings. The options in Excel: begins with, ends with, contains and their negatives are all implemented using the equal (or for negatives notEqual) operator and wildcard in the value. 一般情况下,EXCEL没有标准的字符串匹配功能。EXCEL的字符串条件选项有:开始于……,结束于……,包含,不包含。在文本筛选中用equal(或notEEqual)运算符和通配符 For example: for “begins with a”, use a*; for “ends with a”, use *a; and for “contains a””, use *a*. 例如: “begins with a”, use a*; for “ends with a”, use *a; and for “contains a””, use *a*. DateGroupItemDate filters can be set to allow filtering by different datetime criteria such as year, month or hour. As they are similar to lists of values you can have multiple items. 数据筛选可以用不同的日期序列设置,像年,月,日,或者小时。相似的数值序列可以使用组合。 To filter by the month of March: from openpyxl.worksheet.filters import DateGroupItem df1 = DateGroupItem(month=3, dateTimeGrouping="month") col = FilterColumn(colId=1) # second column col.filters.dateGroupItem.append(df1) df2 = DateGroupItem(year=1984, dateTimeGrouping="year") # add another element col.filters.dateGroupItem.append(df2) filters.filter.append(col)在Python 3.8(64-bit),openpyxl-3.1.2,Excel 2016环境下,可以单独设置year筛选,month筛选必须和year一起,不能单独应用month。单独应用month会出现以下提示信息。
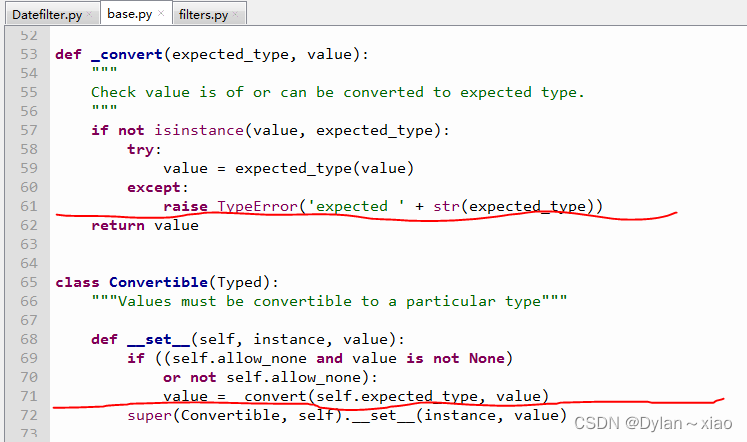
从后向前回溯,base.py异常处理。
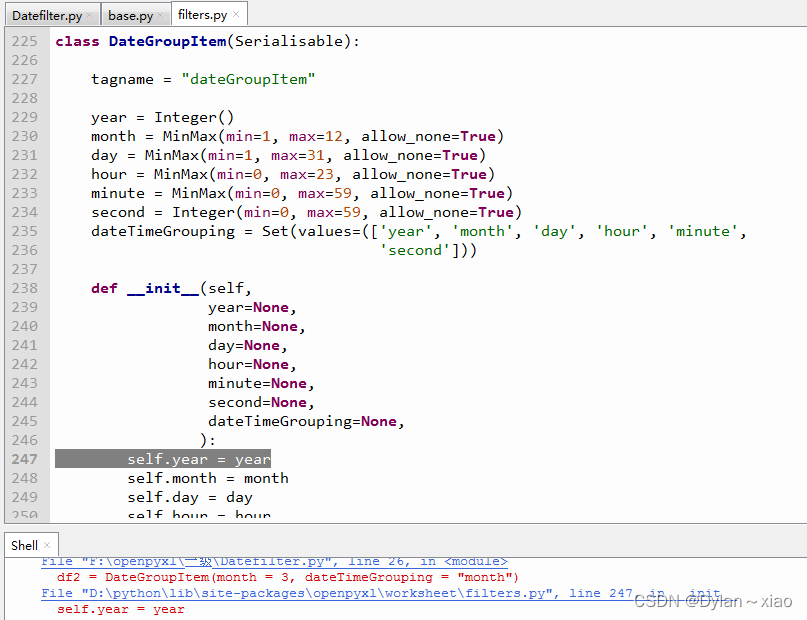
filters.py的DateGroupItem类,曾尝试着将第229行修改为 year = Integer(min = 1, max = 9999, allow_none = True) XML数据不能正常加载。 e 最后得出结论:DateGroupItem在month, day, 筛选时,year不能缺省(位置参数?)。 有关year的筛选实例复现: import datetime from openpyxl import Workbook from openpyxl.worksheet.filters import DateGroupItem, FilterColumn, Filters wb = Workbook() ws = wb.active wb.iso_dates = True data = [ ['product', 'date'], ['A', datetime.datetime(2019,3,3)], ['W', datetime.datetime(1984,6,6)], ['R', datetime.datetime(1984,3,2)], ['M', datetime.datetime(1997,9,5)] ] for row in data: ws.append(row) ws.auto_filter.ref = "A1:B5" col = FilterColumn(colId = 1) #second colum df = DateGroupItem(year = 1984, dateTimeGrouping = "year") col.filters = Filters(dateGroupItem = [df]) ws.auto_filter.filterColumn.append(col) wb.save("year.xlsx")有关month筛选的复现: import datetime from openpyxl import Workbook from openpyxl.worksheet.filters import DateGroupItem, FilterColumn, Filters wb = Workbook() ws = wb.active wb.iso_dates = True data = [ ['product', 'date'], ['A', datetime.datetime(2019,3,3)], ['W', datetime.datetime(1984,6,6)], ['R', datetime.datetime(1984,3,2)], ['M', datetime.datetime(1997,9,5)] ] for row in data: ws.append(row) ws.auto_filter.ref = "A1:B5" col = FilterColumn(colId = 1) #second colum df = DateGroupItem(year = 1984, month = 3, dateTimeGrouping = "month") col.filters = Filters(dateGroupItem = [df]) ws.auto_filter.filterColumn.append(col) wb.save("month.xlsx") 实例:图书销售统计表筛选打开EXC.XlSX工作簿的“图书销售统计表”,按经销部门的降序排列。对数据进行筛选,条件为生物科学和交通科学,销售数量排名高于45,工作表名不变,保存EXC.XlSX工作簿。 表格数据,可以复制在excel工作表,利于对代码的理解。 经销部门图书类别季度销售数量(册)销售额(元)销售数量排名销售额排名第1分部生物科学2412288401410第1分部生物科学1345241502015第1分部生物科学3323226102822第1分部生物科学4187130905438第1分部农业科学176522950120第1分部农业科学265419620226第1分部农业科学3365109501744第1分部农业科学4342102602250第1分部交通科学26544532121第1分部交通科学14363564873第1分部交通科学436529879177第1分部交通科学3231232174018第1分部工业技术156928450411第1分部工业技术243521750823第1分部工业技术3324162002631第1分部工业技术4287143503435第2分部生物科学2256179203628第2分部生物科学3234163803729第2分部生物科学1206144205034第2分部生物科学4196137205237第2分部农业科学354316290530第2分部农业科学4421126301240第2分部农业科学231293603156第2分部农业科学122166304164第2分部交通科学35424123462第2分部交通科学2342237182217第2分部交通科学4341267852413第2分部交通科学112376856263第2分部工业技术4219109504244第2分部工业技术3218109004446第2分部工业技术2211105504949第2分部工业技术116783505561第3分部生物科学2345241502015第3分部生物科学1212148404833第3分部生物科学4157109905743第3分部生物科学312486806160第3分部农业科学44323296094第3分部农业科学130629180329第3分部农业科学3219129904239第3分部农业科学214890785957第3分部交通科学443220563924第3分部交通科学3216102384651第3分部交通科学219996755152第3分部交通科学116687655659第3分部工业技术232196302954第3分部工业技术1301150503332第3分部工业技术4213106504748第3分部工业技术318994505355第4分部生物科学4398278601512第4分部生物科学3378264601614第4分部生物科学2329230302519第4分部生物科学1324226802621第4分部农业科学442132534125第4分部农业科学335629342198第4分部农业科学2217204534525第4分部农业科学1156107865847第4分部交通科学1321189762927第4分部交通科学4261116753541第4分部交通科学3232112983942第4分部交通科学211287986358第4分部工业技术24323125696第4分部工业技术1234143213736第4分部工业技术312996376053第4分部工业技术411281786362 from openpyxl import load_workbook from openpyxl.worksheet.filters import ( FilterColumn, CustomFilter, CustomFilters, ) wb = load_workbook("exc.xlsx") ws = wb["图书销售统计表"] ws.auto_filter.ref = "A1:G65" ws.auto_filter.add_sort_condition("A2:A65", True) ws.auto_filter.add_filter_column(1, ["生物科学", "交通科学"]) flt = CustomFilter(operator = "greaterThan", val = 45) cfs = CustomFilters(customFilter = [flt]) col2 = FilterColumn(colId = 5, customFilters = cfs) ws.auto_filter.filterColumn.append(col2) wb.save("exc.xlsx")这个实例,没有用filters,用到了类auto_filter。 auto_filte类 方法:add_filter_column(col_id, vals, blank=False) 参数col_id:要对哪个列进行筛选,填入int,从0开始 vals:要筛选的选项,放在列表里。 blank:是否显示空行,bool值 方法:add_sort_condition(ref, descending=False) 参数ref:排序的数据区域,不包含标题。 descending:是否按降序排序,默认False, 就是升序。 注意:排序时,只能对一个列排序,没有主关键字,次关键字之分。 CustomFilter实例 代码: from openpyxl.worksheet.filters import ( CustomFilter, CustomFilters, FilterColumn ) from openpyxl import Workbook wb = Workbook() ws = wb.active data = [ ["Fruit","Quantity"], ["Kiwi", 30], ["Grape", 15], ["Apple", 13], ["Peach", 23], ["Pomegranate", 3], ["Pear", 3], ["Tangerine", 39], ["Blueberry", 3], ["Mango", 3], ["Watermelon", 3], ["Blackberry", 3], ["Orange", 3], ["Raspberry", 3], ["Banana", 3], ] for r in data: ws.append(r) filters = ws.auto_filter filters.ref = "A1:B15" flt1 = CustomFilter(operator="lessThan", val=10) flt2 = CustomFilter(operator="greaterThan", val=30) cfs = CustomFilters(customFilter=[flt1, flt2]) col = FilterColumn(colId = 1, customFilters = cfs) filters.filterColumn.append(col) wb.save("CustomFilters.xlsx") 运行结果:CustomFilter |

【本文地址】