详解哈希表查找 |
您所在的位置:网站首页 › 关键字序列排序次数怎么算 › 详解哈希表查找 |
详解哈希表查找
|
哈希表查找
定义基本概念实现方法
1、定义
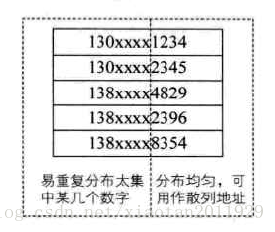
哈希表查找又叫散列表查找,通过查找关键字不需要比较就可以获得需要记录的存储位置,它是通过在记录的存储位置和它的关键字之间建立一个确定的对应关系f,使得每个关键字key对应一个存储位置f(key)。即: —存储位置=f(关键字),其中f为哈希函数。 1、哈希表最适合的求解问题是查找与给定值相等的记录。 2、哈希查找不适合同样的关键字对应多条记录的情况,如使用关键字“男”去查找某个同学。 3、不适合范围查找,比如查找班级18~22岁的同学。 2、基本概念 1、哈希函数的构造方法怎么样的才算是好的哈希函数? 1、计算简单。哈希函数的计算时间(指的是产生地址的时间),不应该超过其他查找技术与关键字比较的时间。 2、 地址分布均匀。尽量让哈希地址均匀分布在存储空间中,这样可以使空间有效的利用。 (1)直接定址法 我们可以去关键字的某个线性函数的值作为哈希地址,如下所示: f(key)= a*key + b (其中a,b均为常数) 这种哈希函数优点是比较简单、均匀,也不会产生冲突,但是需要事先知道关键字的分布情况,适合查找表比较小且连续的情况。在实际中并不常用。(2)数字分析法 可以使用关键字的一部分来计算哈希存储的位置,比如手机号码的后几位(或者反转、左移右移等变换)。 (3)除留余数法 这是最为常用的构造哈希函数的方法,对于哈希表长度为m的哈希函数为: f(key)=key mod p (pelem = (int *)malloc(m*sizeof(int)); for (i = 0; i < m; i++) H->elem[i] = NULLKEY; return OK; } 3、定义哈希函数(为插入时计算地址),这里可以根据不同的情况更换算法 int Hash(int key) { return key % m; //这里使用的是除留余数法 } 4、对哈希表进行插入操作 void InsertHash(HashTable *H, int key) { int addr = Hash(key); //根据关键字求取地址 while (H->elem[addr] != NULLKEY) //如果不为空,有冲突出现 addr = (addr + 1) % m; //这里使用开放定址法的线性探测 H->elem[addr] = key; //直到有空位后插入 } 5、通过哈希表进行关键字的查找过程,如下所示 Status SearchHash(HashTable H, int key, int *addr) { *addr = Hash(key); //求取哈希地址 while (H.elem[*addr] != key) //如果不为空,则存在冲突 { *addr = (*addr + 1) % m; //开发定址法的线性探测 if (H.elem[*addr] == NULLKEY || *addr == Hash(key)) return UNSUCCESS; //关键字不存在 } return SUCCESS; //查找成功返回 } |
【本文地址】
今日新闻 |
推荐新闻 |