长文本或文档级别的关系抽取 |
您所在的位置:网站首页 › 关系抽取论文怎么写 › 长文本或文档级别的关系抽取 |
长文本或文档级别的关系抽取
|
之前我们介绍了 关系抽取 的基础知识和一些论文(虹膜小马甲:NLP 关系抽取 — 概念、入门、论文、总结),这篇重点介绍长文本或文档级别中的关系抽取。 这是自己的知识脉络的梳理,也为想了解长文本或文档级别 关系抽取的同志们提供一份参考。新手友好。 本文主要是介绍长文本或文档级别关系抽取相关概念,以及相关论文和方法的总结。包含: 长文本或文档级别关系抽取相关概念长文本或文档级别关系抽取相关论文前言知识学习关系抽取 的基础知识和一些论文介绍: 虹膜小马甲:NLP 关系抽取 — 概念、入门、论文、总结 一、长文本或文档级别关系抽取相关概念1. 与经典关系抽取的区别经典关系抽取往往着眼于单一的句子,只是试图挖掘出每个句子内部的实体关系;文档往往会提到许多体现复杂交叉逻辑关系的实体,而从复杂的多句场景中提取关系需要阅读,记忆,推理才能发现多个句子间的关系事实2. 主要难题在真实场景如医疗、金融文档中,有许多关系事实是蕴含在文档中不同句子的实体对中的,且文档中的多个实体之间,往往存在复杂的相互关系。与句子级相比,文档级关系抽取中的文本要长得多,并且包含更多的实体, 这使得文档级关系抽取更加困难。 (1)如何有效的建模实体的多粒度信息,其主要包括 2 点: 同一个实体可能在多个句子中出现(即实体在多个句子中的提及);在文本写作中,自然出现的实体指代问题;(2)如何建模文档内的复杂语义信息,其主要涉及多个方面的推理,如逻辑推理、指代推理和常识知识推理等。 3. 文档级关系抽取的方法文档级关系抽取总体可以分为两类方法:基于序列的方法和基于文档图的方法。  文档级关系抽取总体可以分为两类方法:基于序列的方法和基于文档图的方法。4. 常用数据集 文档级关系抽取总体可以分为两类方法:基于序列的方法和基于文档图的方法。4. 常用数据集1)CDR: 生物医学领域的人类标注的化学疾病关系抽取数据集,由500份文档组成,该数据集的任务是预测化学和疾病概念之间的二元相互作用关系。2)GDA: 是生物医学领域的一个大规模数据集,它包含29192篇文档以供训练,其任务是预测基因和疾病概念之间的二元相互作用。3)DocRED: 目前规模最大的人工标注的文档级关系抽取数据集,2019年的ACL上清华大学刘知远团队提出,DocRED包含对超过5000篇Wikipedia文章的标注,包括96种关系类型、143,375个实体和56,354个关系事实,这在规模上超越了以往的同类精标注数据集。与传统的基于单句的关系抽取数据集相比,DocRED中超过40%的关系事实只能从多个句子中联合抽取,因此需要模型具备较强的获取和综合文章中信息的能力,尤其是抽取跨句关系的能力。5. 评估方法文档级关系抽取任务定义为一个多标签的分类问题,具体而言,输入一篇文章及文章中包含的实体对,输出每个实体对的关系。具体的评估方法为F1或者AUC。 另外,为了排除验证集/测试集与训练集中出现一模一样的实体关系对对最终评价指标造成的影响,还有另外两个指标Ign F1和Ign AUC,这两个指标就是排除了开发集/测试集与训练集中出现相同的实体关系对的影响后的指标。 6. 现状对于文档级别的抽取,如今 GCN (图卷积网络)已成为主流的方法,在 NLP 相关的会议上,基于 GCN 的文档级别抽取方法的论文应该是最多的。但是,总体而言,这类方法主要是将提及(Mention)、实体、句子级别的信息进行聚合以及传递,但是我们在做关系抽取时,更多的是要关注实体对级别的信息传递,这方面的工作仍然可以做进一步的展开。还有一点,如何有效解决 GNN 可能面临的“过平滑”问题。再者,在基于文档而建立的异构图中,不同节点之间的信息是如何进行传递的,这也是值得研究的一个点。复杂语境下的实体关系抽取-InfoQ 尽管文档级关系抽取取得了一定程度的发展,其性能仍难以满足实际应用的需求。未来可能的方向有:1. 设计文档实体结构相关的预训练。2. 减轻关系标签分布不平衡。3. 引入外部知识。4. 设计更好的实体交互模型。https://flashgene.com/archives/188445.html 二、长文本或文档级别关系抽取相关论文1. GCNN —ACL 2019 Inter-sentence Relation Extraction with Document-level Graph Convolutional Neural Network基于句子级别的抽取,再进行聚合操作基于图神经网络数据集:CDR 、 CHR Inter-sentence Relation Extraction with Document-level Graph Convolutional Neural Network Inter-sentence Relation Extraction with Document-level Graph Convolutional Neural Network① 使用图神经网络来建模文档:在构建文档时,将输入文档中的每个词作为图中的一个节点,通过不同类型的边对整个文档的结构进行表示。 作者用句法依赖标签建立句子中单词之间的远距离依赖;用指代消解工具将具有指代关系的词进行连接;将句子中相邻的两个词也连接起来;将句子中当前词的前后节点连接起来;最后将词本身进行连接。连接完成后,便构建出了一个图结构。 ② 在下一步中,基于构建好的文档图,使用 GCNN 来学习节点之间的信息交互/传递,计算得到每个节点的表示。这样,不同句子中的不同提及都会得到表示。 ③ 最后,通过多示例学习的方式聚合目标实体的所有提及并进行关系分类。 论文解读:论文笔记 Inter-sentence Relation Extraction with Document-level Graph Convolutional Neural Network 2. EOG —EMNLP 2019(代表性论文)Connecting the dots: Document-level neural relation extraction with edge-oriented graphs基于文档图的方法 要采用启发式的方法来构建图结构EoG(full)表示的是一种全连接的图,EoG(NoInf)表示不采用在图中游走的策略,EoG(Sent)表示以句子级别来构建的图。数据集:CDR、GDA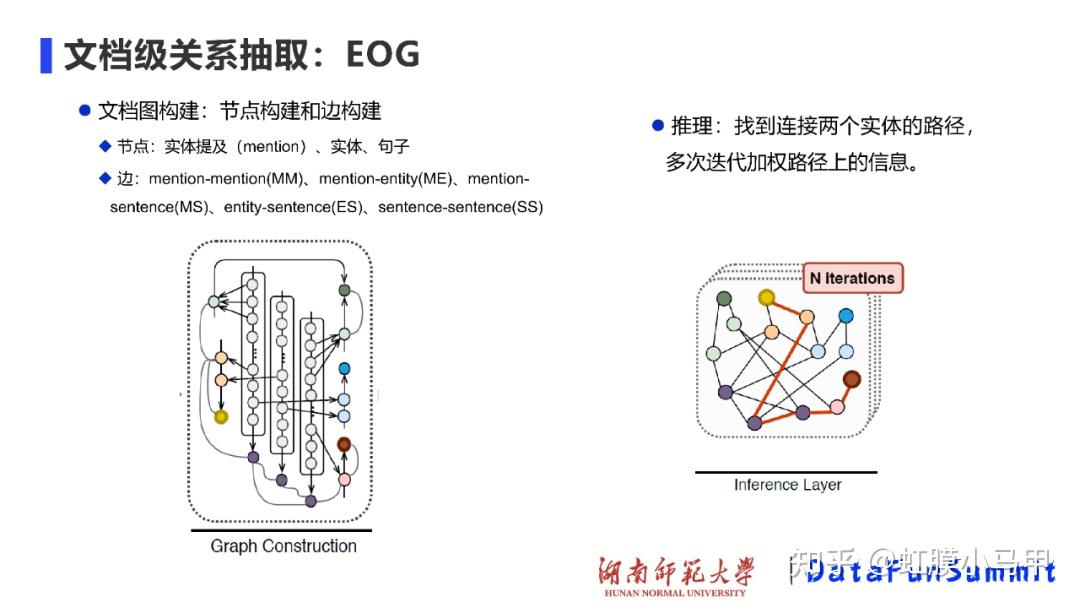 Connecting the dots: Document-level neural relation extraction with edge-oriented graphs Connecting the dots: Document-level neural relation extraction with edge-oriented graphs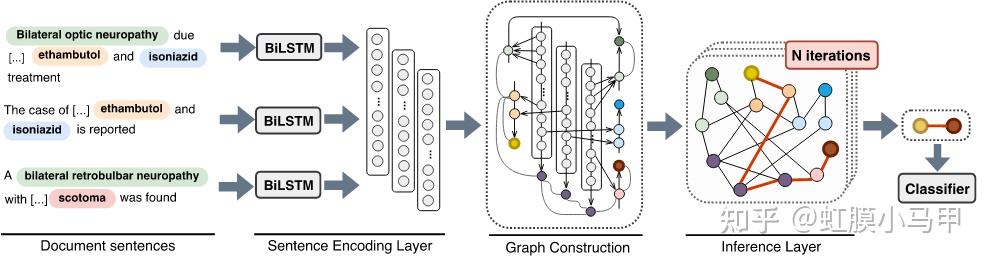 EoG 通过在不同类型的节点之间建立不同类型的边来决定信息流入节点的多少,如此可以更好地拟合文档之间异构的交互关系。 在 EOG 中,作者主要采用启发式的方法来构建图结构,图中的节点有实体提及、实体和句子,边主要包括:提及到提及(mention-mention, MM)、提及到实体(mention-entity, ME)、提及到句子(mention-sentence,MS)、实体到句子(entity-sentence,ES)和句子到句子(sentence-sentence,SS)之间的关系。构建好图之后,下一步就是推理处理。与使用 GCN 来进行推理不同,这里主要是训练连接两个实体之间的路径,多次迭代加权该路径上的信息,如上图(右)所示,从而将路径上的信息进行传递,起到推理的效果。 论文解读:https://flashgene.com/archives/188169.html 论文代码: GitHub - fenchri/edge-oriented-graph: Source code for the EMNLP 2019 paper: "Connecting the Dots: Document-level Relation Extraction with Edge-oriented Graphs" 3. LSR —ACL 2020(代表性论文)《Reasoning with latent structure refinement for document-level relation extraction》将图结构视为一个潜在的变量,并且以端到端的方式对其进行归纳推理。即在初始建图时,可以采用随机初始化或其它方式来完成;后续每一步迭代都将该图进行修正,进而得到最终的结果。LSR模型分为三部分:Node Constructor、Dynamic Reasoner、Classifer数据集:DocRED、CDR、GDA  《Reasoning with latent structure refinement for document-level relation extraction》 《Reasoning with latent structure refinement for document-level relation extraction》LSR[15]模型是EoG模型的改良,针对的问题就是:在EoG模型的消融实验中,发现EoG(full)在句子间距离长度大于4时的效果要比原始的EoG模型要好,那幺基于这样一个发现自然会想到在full的情况下,是否可以让模型自动选择哪些边重要,那些不重要呢? 论文解读:https://flashgene.com/archives/188169.html 文档级关系抽取方法总结_CycloneKid的博客-CSDN博客_文档级关系抽取 论文代码:GitHub - nanguoshun/LSR: Pytorch Implementation of our ACL 2020 Paper "Reasoning with Latent Structure Refinement for Document-Level Relation Extraction" 4. GAIN—EMNLP 2020(代表性论文)《Double Graph Based Reasoning for Document-level Relation Extraction》提出了一种具有双图特征的图聚合推理网络(GAIN)GAIN模型分为四部分: encoding module、ention-level graph aggregation module、entity-level graph aggregation module、classification module如何对文档进行建模以及如何进行关系推理:在 Double Graph 中,作者将以上两个部分分隔开,第一个部分是在提及级别的图(mention-level graph)上进行 GCN 或随机游走,进而完成图中的信息传递与推理。如图(左),不同的颜色区域代表不同的句子,由于圆圈 2 表示的实体在多个句子中出现,故我们可将它们连接起来;一个句子中出现的所有实体也被连接起来。第二部分是比较创新的一个部分,即实体级别的图(entity-level graph),它是将所有提及级别的节点进行加权。在考虑两个实体之间的关系时,将它们的连接路径也考虑在内,并且进行压缩。最终在识别两个实体之间的关系时,将上述压缩后的向量送入 MLP 网络进行关系分类。数据集:DocRED 《Double Graph Based Reasoning for Document-level Relation Extraction》 《Double Graph Based Reasoning for Document-level Relation Extraction》这篇paper也是继承EoG模型,主要应对文档级别的关系抽取提出的三个主要挑战:1. 一个relation的subject与object可能位于不同的sentence,需要考虑多个sentence才能判断一对实体的relation;2. 同一个entity可能会出现在不同的sentence当中,因此需要利用更多的上下文信息,从而更好的表示entity;3. 很多relation需要logical reasoning才能得到。为此提出了GAIN模型。 论文解读:论文小综 | 文档级关系抽取方法(上) 论文代码:https://github.com/DreamInvoker/GAIN 5. X-MedRELA—ACL 2020Rationalizing Medical Relation Prediction from Corpus-level Statistics数据集:Corpus-level Statistics,Labeled Relation Data,Relation List,Relation Triples. 论文解读:https://posts.careerengine.us/p/5f50fcf21f10f27ca29c0644?from=mostSharedPostSidePanel 代码:https://github.com/zhenwang9102/X-MedRELA#x-medrela 6. SCIREX —ACL2020SCIREX: A Challenge Dataset for Document-Level Information Extraction我们开发了一个神经模型作为强基线,将以前最先进的IE模型扩展到文档级IE数据集:SciREX 论文解读:长文本或者文档级别的关系提取任务 SCIREX: A Challenge Dataset for Document-Level Information Extraction (ACL2020) https://posts.careerengine.us/p/5f50fcf21f10f27ca29c0644?from=mostSharedPostSidePanel 代码:https://github.com/allenai/SciREX 7. RERE — ACL 2021 Revisiting the Negative Data of Distantly Supervised Relation Extraction这篇论文对于远程监督关系抽取中因知识库不完整而导致的缺失关系 (false negative) 进行了分析,把关系抽取问题转化成了一个正面的无标记学习任务,来缓解 false negative 问题,并且提出了一种叫 RERE 的两阶段流水线方法。实验结果表明,即使在学习的负错误率很高的情况下,RERE 的表现也始终比现有的先进水平明显要好。数据集:NYT21 and SKE21 论文解读:论文分享 | ACL 2021 文档级的关系抽取 论文代码:https://github.com/redreamality/RERE-relation-extraction 8. SENT — ACL 2021 SENT: Sentence-level Distant Relation Extraction via Negative Training在本文中,作者提出了一种基于负训练的句子级框架 SENT,用于远程关系抽取数据的句子级训练。负训练不仅可以防止模型过拟合噪声数据,而且可以将噪声数据从训练数据中分离出来。通过迭代执行基于负训练的噪声过滤和重标记,SENT 帮助改善了有噪声的远程数据,取得了显著的性能。实验结果验证了该方法在句子级关系提取和噪声过滤效果上较以往方法有所改善。数据集:https://github.com/PaddlePaddle/Research/tree/master/NLP/ACL2019-ARNOR 论文解读:论文分享 | ACL 2021 文档级的关系抽取 论文代码:https://github.com/rtmaww/SENT 9. Three-Sentences-Are-All-You-Need — ACL 2021 Three Sentences Are All You Need: Local Path Enhanced Document Relation Extraction数据集:DocRED这篇论文对于远程监督关系抽取中因知识库不完整而导致的缺失关系 (false negative) 进行了分析,把关系抽取问题转化成了一个正面的无标记学习任务,来缓解 false negative 问题,并且提出了一种叫 RERE 的两阶段流水线方法。实验结果表明,即使在学习的负错误率很高的情况下,RERE 的表现也始终比现有的先进水平明显要好。数据集:DocRED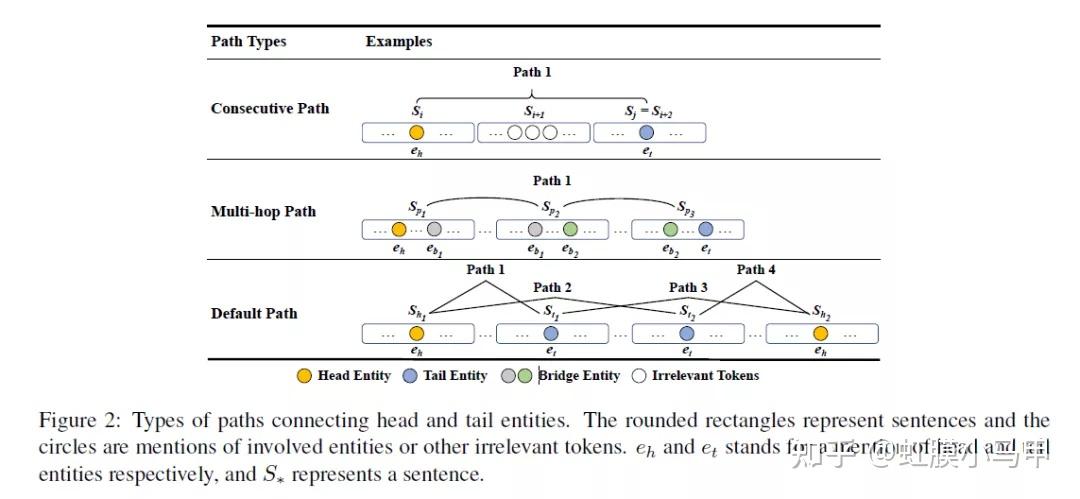 论文解读:论文分享 | ACL 2021 文档级的关系抽取 论文代码:https://github.com/redreamality/RERE-relation-extraction 10. DocuNet— IJCAI 2021Document-level Relation Extraction as Semantic Segmentation长文本知识抽取:基于语义分割的文档级三元组关系抽取数据集:DocRED, CDR, GDA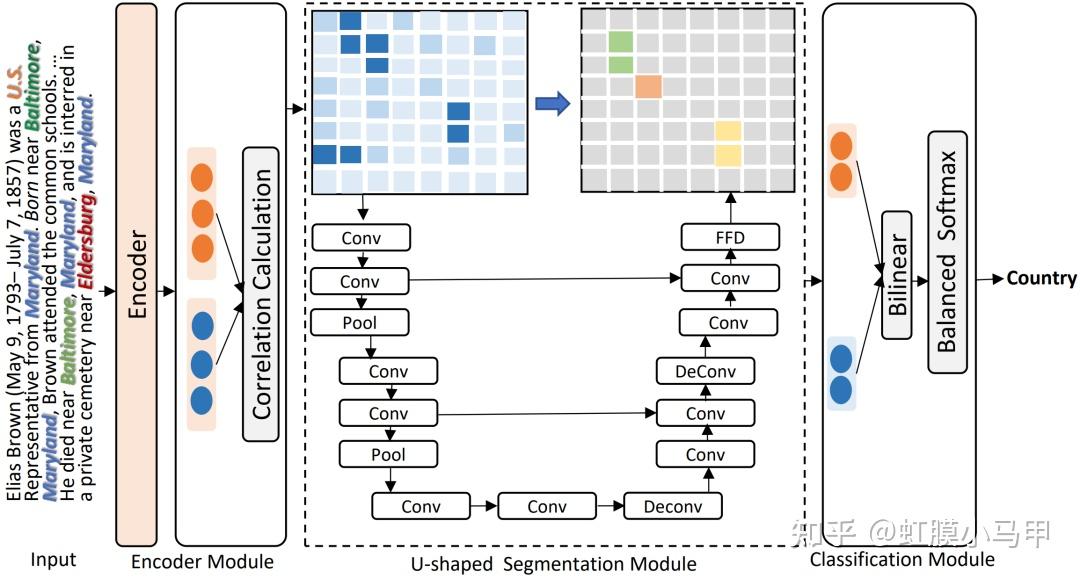 Document-level Relation Extraction as Semantic Segmentation Document-level Relation Extraction as Semantic Segmentation论文解读:IJCAI2021 | 长文本知识抽取:基于语义分割的文档级三元组关系抽取 代码:GitHub - zjunlp/DocuNet: Source code and dataset for the IJCAI 2021 paper "Document-level Relation Extraction as Semantic Segmentation". 11. ATLOP— AAAI 2021(代表性)Document-Level Relation Extraction with Adaptive Thresholding and Localized Context Pooling数据集:DocRED、CDR、GDAATLOP模型的核心主要为两部分:Localized Context Pooling和Adaptive Thresholding。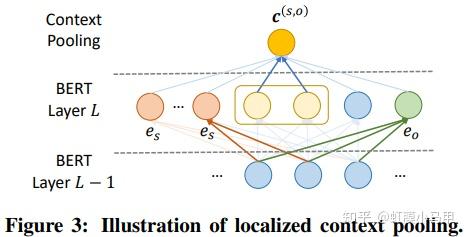  实验结果显示,在DocRED、CDR和GDA三种数据集上,作者提出的ATLOP均达到了SOTA,ATLOP未构建任何图结构,简单的应用bert自身的attention信息以及动态阈值方法便取得了显着的效果。 论文解读:https://flashgene.com/archives/188445.html 代码:https://github.com/wzhouad/ATLOP 12. SSAN— AAAI 2021(代表性)Entity Structure Within and Throughout: Modeling Mention Dependencies for Document-Level Relation Extraction作者认为,structural dependencies应纳入编码网络内以及整个系统中,由此提出SSAN (Structured\ Self-Attention Network),可以有效地在其构造块内以及从下至上的所有网络层中对这些依赖性进行建模。数据集:DocRED、CDR、GDA SSAN将structural dependencies纳入encoder网络内以及整个系统中,能够同时地进行context reasoning and structure reasoning,这种方法很有启发意义,作者也提到SSAN方法很容易适用于其他各种基于Transformer的预训练语言模型以融合任何结构上的依赖性。 论文解读:https://flashgene.com/archives/188445.html 代码:Research/KG/AAAI2021_SSAN at master · PaddlePaddle/Research 参考【关于 关系抽取】那些你不知道的事 Yuhwa Choong:[KG笔记]八、文档级(Document Level)关系抽取任务 |
【本文地址】
今日新闻 |
推荐新闻 |