[KG笔记]八、文档级(Document Level)关系抽取任务 |
您所在的位置:网站首页 › 关系抽取实例有哪些 › [KG笔记]八、文档级(Document Level)关系抽取任务 |
[KG笔记]八、文档级(Document Level)关系抽取任务
|
目前大多数关系抽取方法抽取单个实体对在某个句子内反映的关系,在实践中受到不可避免的限制:在真实场景中,大量的关系事实是以多个句子表达的。文档中的多个实体之间,往往存在复杂的相互关系。根据从维基百科采样的人工标注数据的统计表明,至少40%的实体关系事实只能从多个句子联合获取。因此,有必要将关系抽取从句子级别推进到文档级别[1]。 一、文档级关系抽取的特点 文档级关系抽取任务存在三方面的特点: 第一是作用对象是整个文档,大量的信息分布在不同的句子里。 第二是整个文档中可能有多个Mention指向同一个实体。 第三是部分关系需要经过多重信息的推理才能得到。 二、文档级关系抽取的数据集CDR[2](Chemical Disease Relation):生物医学领域的人类标注数据集,任务是预测化学和疾病概念之间的二元相互作用,包含500篇训练文章。 GDA[3](Gene Disease Association):生物医学领域的一个大规模数据集,,任务是预测基因和疾病概念之间的二元相互作用由29192篇训练文章组成。 DocRED[4](Document-Level Relation Extraction Dataset):是一个大规模的众包数据集,原始语料基于维基百科,包含3053份文章,其中存在大约7%的实体对具有多种关系。该数据集在CodaLab上开放有benchmark[5]。 三、近期文档级关系抽取的方法总结我们从文档级关系抽取的特点出发,从三个方面阐述文档级关系抽取方法都分别使用了什么策略来应对这些特点: 1. 建模层包含Mention层级 在句子级关系抽取任务中,极少会出现同一个句子里出现一个实体的不同表达,因此通常会直接把任务建模在token->entity->entity pair->relation的流程上。而在文档级关系抽取任务中,可能先出现“知识图谱”,在之后的句子中又出现“图谱”,这两个Mention都指代“知识图谱”这一实体。 在具体实现中,由于embedding layer通常是token level的,我们假设一篇文章包含n个tokenD = \{t_1, t_2, \cdots, t_n\} ,其中某一个mention是 m_i = pooling(t_j,\cdots,t_{j+k}) ,pooling的方法可以是mean pooling也可以是max pooling等,而指向同一个实体的不同mention embedding也可以通过pooling的方式得到实体embedding。 2. 抽取全局信息 我们通常可以把句子内部(intra-sentence)的特征信息称之为局部特征,而把跨句子(inter-sentence)的、篇章级的特征信息称之为全局信息。 对于局部信息的抽取基本等同于句子级别关系抽取的encoding model,比如可以使用Word2Vec/ GloVe+Bi-LSTM,BERT等。可以得到与token序列等长的特征序列。 对于全局信息的抽取在实现上我将其分为三类:基于层级网络的方法,基于全局图的方法,基于BERT硬编码的方法。 基于层级网络的方法基于层级网络的方法试图通过不同层级的网络实现token level -> sentence level -> document level的层次化特征抽取,并把不同层次的特征concate起来做实体对之间的关系分类。 典型代表是HIN(Hierarchical Inference Network)[6],其使用不同层级上的BiLSTM抽取各个层级的特征序列,并以注意力机制加权得到整体特征,以此得到局部+全局的特征信息对实体进行表征。  基于全局图的方法 基于全局图的方法基于全局图的方法是近年来最主流的方法,一方面GNN正当红,另一方面GNN在挖掘结构性特征上有得天独厚的优势。 基于全局图的方法的标准流程可以总结为三部分:编码及构图、GNN迭代(Multi-hop inference)、实体对关系分类。如下图为比较典型的基于全局图的方法的流程图[7]。  基于全局图方法的一种标准流程 基于全局图方法的一种标准流程在编码方面,现在的方法基本比较统一:使用GloVe或BERT得到token level embedding,使用可训练权重对token的类别(实体类别,无类别等)进行映射得到type embedding,使用可训练权重对相对位置映射得到relative position embedding。总体上来说token level的信息源就是自身语义、类型及相对位置信息。 在构图方面,本质上只需要确定两部分内容:一个是在图里有哪些类型的点(type of nodes),另一个是在图里有哪些类别的边(type of edges)。一般来说,可以使用的nodes类型有:tokens(words),mentions,entities,sentences;可以使用edges类型有:1. 依据node类别,如mention-mention,mention-entity,entity-sentence等[7][8],2.依据近邻、依存、包含关系的细分,如word-word adjacency, word-word dependency, word-sentence affiliation等[9]。 完成构图之后,通常基于token level embeddings使用各种pooling方法得到各种node的embeddings,对于边的权重则可以使用头尾的token、mention、entity或sentence的embedding concat起来使用。使用GCN[10][11]或GAT[12]等完成多次迭代得到经过平滑后各个节点的结构化特征(structural feature)。部分文章考虑到单一全局图可能无法得到完整的全局信息,使用多个层级的图神经网络抽取不同层级的结构化特征,如GAIN[13]构建了Mention-Level和Entity-Level两个图,通过Mention-Level GCN得到更好的Mention Embeddings,并以此得到更好的Entity Embeddings,而DHG[9]将word和sentence构建成第一个图以挖掘entity的结构特征,并构建mention和entity的relation reasoning子图,以得到推理层级上的信息。  GAIN:Graph Aggregation-and-Inference Network GAIN:Graph Aggregation-and-Inference Network DHG:Dual-tier Heterogeneous Graph DHG:Dual-tier Heterogeneous Graph通常在GNN得到节点结构化特征后,模型会使用skip connection的方式将节点的语义和上下文特征与结构化特征concate起来使用,通过bilinear的方式对实体对进行关系分类,由于同一个实体对之间可能存在多种关系,所以通常使用multi-label sigmoid的方式输出全部类别下的概率,使用Binary Cross Entropy Loss进行训练。由于sigmoid输出存在一个阈值选择的问题,文献[14]使用了一种特殊的任务构建方式实现了sigmoid输出层的自适应阈值。  Adaptive thresholding基于BERT硬编码的方法 Adaptive thresholding基于BERT硬编码的方法基于BERT硬编码的方法试图通过原始Transformer或引入外部信息的改造Transformer来对全局信心进行建模。 如文章[15]仅在原始BERT基础上在实体Mention前后引入了实体类别和全局实体的标签,使用BiLinear输出实体对之间的关系类别信息,实现了One pass的模型,而文章[16]则将在BiLinear输出关系前添加了entity filtering的过程以降低计算量。 文章《Denoising RE from Document-Level》[17]则设计了Mention-Entity Matching、Relation Detection和Relation Fact Alignment三种子任务以预训练基于BERT的document-level RE模型。 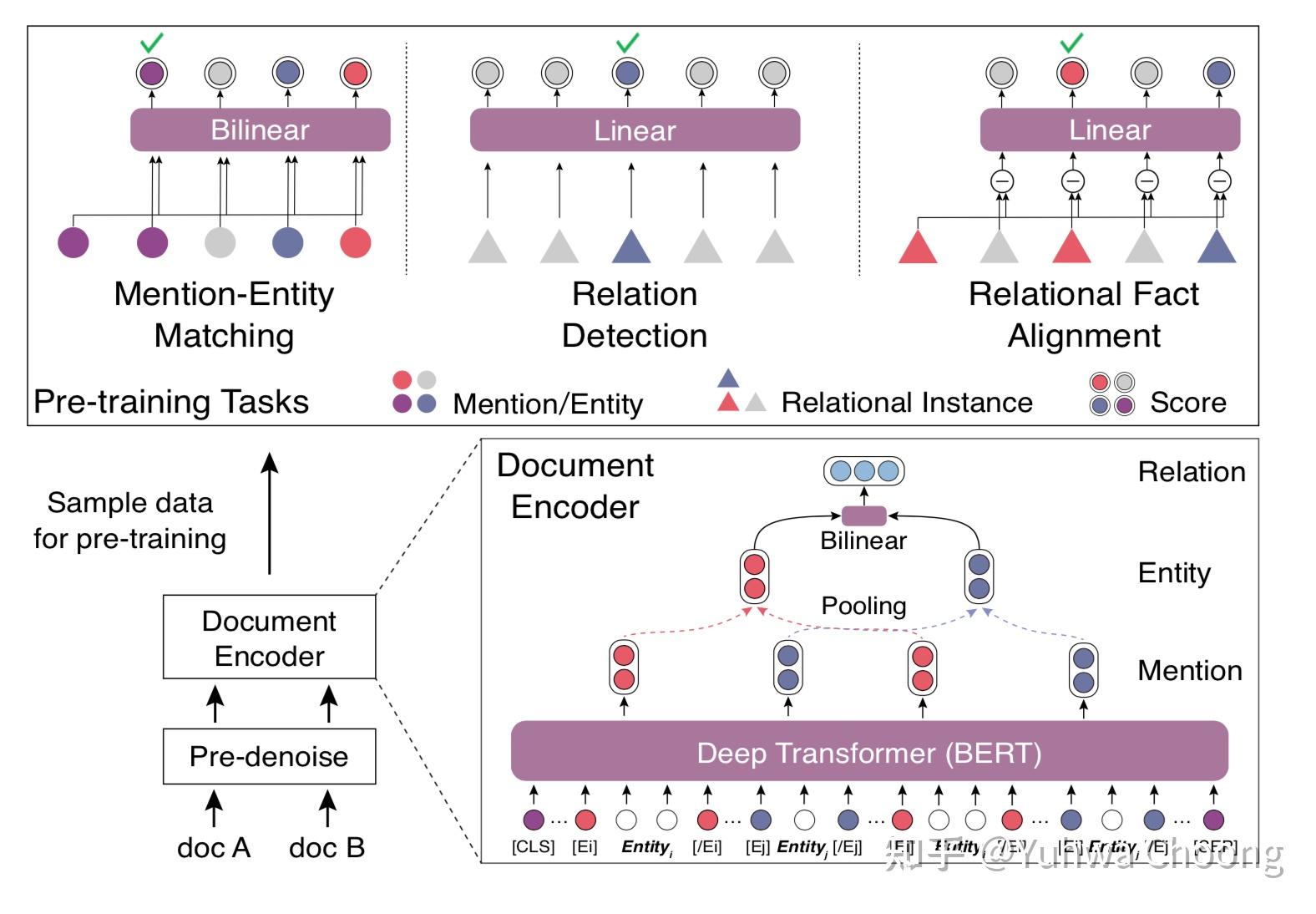 Denoising RE from document level Denoising RE from document levelSSAN[18]则将Mention是否在同一个句子中、是否指向同一个实体硬编码为Entity Structure信息,文章认为这是mention level的dependency信息(实现上是token level的),并将其使用BiAffine的方式引入到Transformer Encoder的Score计算部分,将其作为bias添加到token embedding的self attention score中,最后依旧使用bilinear+multi-label sigmoid的方式输出实体对之间的关系。  SSAN SSAN3. 完成多步推理 完成多步推理的任务在大部分论文中写作Relational Reasoning: 在使用Hierarchical Model的文章中通常认定层级性的Attention可以实现一定程度上的推理。在使用GNN的文章中通常认定多次Message Passing的过程就等价于多步推理的过程。简单地来说,消息传播(Message Passing)就是每个节点的邻居所携带的信息通过一定的规则传播的该节点上。 如基于Walk机制的模型[19][7]中,使用双线性函数表示两个节点之间多跳路径的聚合结果: f(\overrightarrow{v_{ik}}^{(\lambda)}, \overrightarrow{v_{kj}}^{(\lambda)}) =\sigma ( \overrightarrow{v_{ik}}^{(\lambda)} \odot (\bold{W}_b \overrightarrow{v_{kj}}^{(\lambda)} ) ) \\ 其表示节点i->节点k和节点k->节点j的两条路径信息聚合的结果,并以此更新: v_{ij}^{(2\lambda)}=\beta v_{ij}^{(2\lambda)}+(1-\beta)\sum_{k \neq i,j} f(v_{ik}^{(\lambda)}, v_{kj}^{(\lambda)}) \\ 其认定 \lambda 表示了路径的长度,即经过多次消息传播的迭代后,每条边的embedding都包含了预期长度路径内的信息。 而使用GCN的模型中,直接使用一个线性映射来拟合邻居节点聚合的规则: x_i^{k+1} = f(\sum_{u \in V_i} (\bold{W}_{l(i,u)}^{k} x_u^k + \bold{b}^k_{l(i,u)} ) ) \\ 其认定经过k次聚合后,每个节点的embedding都包含了其k跳的边和节点信息。 而R-GCN则在此基础上加入了自环的部分: h_i^{(l+1)}=\sigma( \sum_{t \in T}^{} \sum_{j \in N_{i}^{t}}^{} \frac{1}{|N_{i}^{t}|} W_{t}^{l}h_{j}^{l}+W_{s}^{l}h_{l}^{l} ) \\ GAT则是使用注意力机制来完成相邻节点的聚合: \alpha_{ij}^{}=\frac {exp(LeakyReLU(\tilde{a}^T[W\overrightarrow{h_i}||W\overrightarrow{h_j}]))} {\sum_{k \in N_i}exp(LeakyReLU(\tilde{a}^T[W\overrightarrow{h_i}||W\overrightarrow{h_k}]))}\\ \overrightarrow{h_i}^{(l+1)} = ||_{k=1}^K \sigma(\sum_{j \in N_i} \alpha_{i,j}^{k(l)} W^{k(l)} \overrightarrow{h_j}^{(l)}) \\ 其中的K表示使用了K个注意力头,||表示将多头注意力得到的结果concat起来。 由于GNN过深时可能造成过度平滑问题,因此部分文章引入了门控机制(gating mechanism): u_i^l=aggregating(h_k^l) for \space k \in N_i\\ g_i^l=Sigmoid(F_g([u_i^l||h_i^l]))\\ \hat{h_i}^{(l+1)}=g_i^l \odot tanh(u_i^l) + (1-g_i^l) \odot h_i^l\\ 通过控制聚合信息的比重来抑制过度平滑。 此外还有使用reconstrctor来拟合meta-path以提供下一跳node概率的方法[12],其使用Bi-LSTM来预测当前节点可能的下一跳节点,在inference时提供一个参考概率。 Document-level RE with reconstructor Document-level RE with reconstructor总的来说,当前使用GNN的方法占据上风,但使用何种类型的节点和边需要精巧的人工设计,这一点并不算优雅,这也是GNN当前在非图数据上应用普遍存在的一个问题。基于预训练模型(BERT等)的方法使用设计的子任务提升性能的思路可以在更大量数据上测试,同时将更多的全局依存信息,尤其是与位置相关的信息编码进使用transformer的模型中可能也会有更好的效果。 参考^https://zhuanlan.zhihu.com/p/93318977^Li, J.; Sun, Y.; Johnson, R. J.; Sciaky, D.; Wei, C.-H.; Leaman, R.; Davis, A. P.; Mattingly, C. J.; Wiegers, T. C.; and Lu, Z. 2016. BioCreative V CDR task corpus: a resource for chemical disease relation extraction. In Database.^Wu, Y.; Luo, R.; Leung, H. C.; Ting, H.-F.; and Lam, T.-W. 2019b. RENET: A Deep Learning Approach for Extracting Gene-Disease Associations from Literature. In RECOMB.^Yao, Y.; Ye, D.; Li, P.; Han, X.; Lin, Y.; Liu, Z.; Liu, Z.; Huang, L.; Zhou, J.; and Sun, M. 2019. DocRED: A Large- Scale Document-Level Relation Extraction Dataset. In ACL.^https://competitions.codalab.org/competitions/20717#results^Tang H, Cao Y, Zhang Z, et al. Hin: Hierarchical inference network for document-level relation extraction[C]//Pacific-Asia Conference on Knowledge Discovery and Data Mining. Springer, Cham, 2020: 197-209.^abcChristopoulou F, Miwa M, Ananiadou S. Connecting the dots: Document-level neural relation extraction with edge-oriented graphs[J]. arXiv preprint arXiv:1909.00228, 2019.^Wang D, Hu W, Cao E, et al. Global-to-Local Neural Networks for Document-Level Relation Extraction[J]. arXiv preprint arXiv:2009.10359, 2020.^abZhang Z, Yu B, Shu X, et al. Document-level Relation Extraction with Dual-tier Heterogeneous Graph[C]//Proceedings of the 28th International Conference on Computational Linguistics. 2020: 1630-1641.^Quirk C, Poon H. Distant supervision for relation extraction beyond the sentence boundary[J]. arXiv preprint arXiv:1609.04873, 2016.^引用 Sahu S K, Christopoulou F, Miwa M, et al. Inter-sentence relation extraction with document-level graph convolutional neural network[J]. arXiv preprint arXiv:1906.04684, 2019.^abXu W, Chen K, Zhao T. Document-Level Relation Extraction with Reconstruction[J]. arXiv preprint arXiv:2012.11384, 2020.^Zeng S, Xu R, Chang B, et al. Double Graph Based Reasoning for Document-level Relation Extraction[J]. arXiv preprint arXiv:2009.13752, 2020.^ Zhou W, Huang K, Ma T, et al. Document-Level Relation Extraction with Adaptive Thresholding and Localized Context Pooling[J]. arXiv preprint arXiv:2010.11304, 2020.^Han X, Wang L. A Novel Document-Level Relation Extraction Method Based on BERT and Entity Information[J]. IEEE Access, 2020, 8: 96912-96919.^Wang, H., Focke, C., Sylvester, R., Mishra, N., Wang, W.: Fine-tune Bert for Docred with two-step process. arXiv preprint arXiv:1909.11898 (2019)^Xiao C, Yao Y, Xie R, et al. Denoising Relation Extraction from Document-level Distant Supervision[J]. arXiv preprint arXiv:2011.03888, 2020.^Xu B, Wang Q, Lyu Y, et al. Entity Structure Within and Throughout: Modeling Mention Dependencies for Document-Level Relation Extraction[J]. arXiv preprint arXiv:2102.10249, 2021.^Christopoulou F , Miwa M , Ananiadou S . A Walk-based Model on Entity Graphs for Relation Extraction[C]// The 56th Annual Meeting of the Association for Computational Linguistics. 2018. |
【本文地址】