N卡 支持内存显存融合,AI模型训练不再会炸显存啦 |
您所在的位置:网站首页 › 共享显存设置方法 › N卡 支持内存显存融合,AI模型训练不再会炸显存啦 |
N卡 支持内存显存融合,AI模型训练不再会炸显存啦
|
N卡 支持内存显存融合,AI模型训练不再会炸显存啦
浏览: 2,481 次浏览
作者: 去年夏天
分类: AI,资讯
发布时间: 2023-08-22 15:38
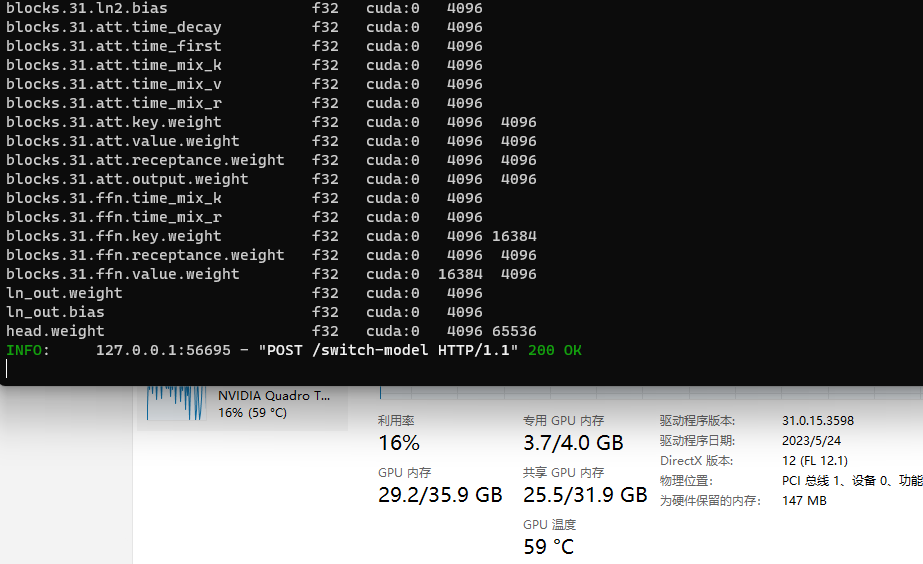
目前AI训练中,相比算力,显存大小的限制才是最头疼的地方,算力低,结果最多是慢,只要显卡够便宜,可以通过堆数量实现,但是显存不够最低线,直接就跑不了,彻底没戏。而N卡在最近的驱动中帮大家解决了CUDA内存与显存的打通。可以直接将内存作为显存,原有代码可以无缝兼容。
驱动会自动划走电脑实际内存的一半作为共享显存,比如我电脑时64G内存,显卡板载显存为4GB 那么对于基于CUDA的框架来说,这是一个拥有4GB高速显存+32GB慢了大约2~3倍显存的显卡。 题图里可以看到,我加载了一个需要30G显存的模型,现在并不会被炸显存。而且全部是以FP32精度以CUDA运行模式载入。 大白话解释一下实际运行的模式,假设模型共24层,每层512MB,一共需要12GB显存。假设其他东西都不需要显存,全给模型载入用,(实际这不可能,总要留运行和其他软件的显存,而且模型具体运行也不这样,咱们只是描述一下大概的原理过程,方便理解) – 方式一: – 将前8层放入显存,占用满4GB显存 – 将其余层放入共享显存(内存)占用满8GB内存。 – 用完前8层后卸载,从内存载入9-16层到显存,占用满4GB显存。 – 用完前9-16层后卸载,从内存载入17-24层到显存,占用满4GB显存。 – 方式二: – 直接将4GB显存和8GB内存统一作为显存,但驱动会将板载的4GB显存优先作为实际显存用。类似物理内存与虚拟内存的感觉。 总结一下 可以看到方式一中,内存to显存了1+2次,虽然内存到显存的速度还算快,不过后面这2次载入每次运算时都需要来一遍,但如果你有12GB显存,从内存to显存只需要最开始的1次。所以实际运行时,板载显存4GB+32GB共享显存,会比直接有12GB显存的显卡慢大约3倍。而方式二的速度就不好说了,我最近跑RWKV的经验来说,大概方式二比方式一在FP16精度下节约了40%用时。之前一些修改版的框架,比如torch(JTorch)也可以自动实现这个显存内存自动合用的功能, PS:其实torch应该从1.3之后的也支持,只不过需要开发者自己去实现模型分层载入显存并卸载。 英伟达算是将这个东西在驱动里实现了。 因为不同显卡FP32,FP16,INT8等精度下的算力差异和显存大小差别,需要测试一下是用INT8减少显存占用,减少从内存搬运到显存的用时,但会降低每层的运算速度。还是使用FP16虽然需要多从内存搬运到显存几次,但是加快每层的运算速度。到底哪一种选择会更省时间。 简单的LLM类模型计算显存占用方式:FP16≈模型文件体积 X 2,in8≈模型文件体积 X 0.7。 简单的真显存和融合下运算速度差距: 模型需要显存<显卡物理显存 : 肯定是纯显存炮最快 显卡物理显存 X 1.5 > 模型需要显存 > 显卡物理显存 X 1: 大部分情况下会比纯内存+CPU要快。 显卡物理显存 X 2 > 模型需要显存>显卡物理显存 X 1.5: 不相上下,具体看你CPU和GPU运算速度的差距。 模型需要显存>显卡物理显存 X 2: 很可能用GPU还不如你用CPU+内存跑的快了。 AI 5 条评论 发表新评论kxk0303 2023-10-13 15:01 回复TA你好,请问这个N卡内存显存融合是怎么实现的?能提供一下使用方法吗?非常感谢 去年夏天 2023-10-13 16:08 回复TA不用管,显卡驱动升级到最新后自动实现的,正常加载大模型,占用超过显存后,驱动会自动给你往内存里塞。 kxk0303 2023-10-16 09:42 回复TAubuntu系统的也可以吗,因为服务器的驱动不敢随意升级,想先问问 ydywyh 2024-03-15 16:21 回复TA不用玩了,我试过了,13B的模型,8G的显存,模型数据大多都是塞到内存里,200W的功耗显卡,实际推理的时候,只有70W,速度慢的一笔,仅次于CPU运算。 只有不爆显存的模型,速度才是最快的,200W 功率占满 去年夏天 2024-03-15 17:16 回复TA比之前的模型切片载入还是要快的, 融合模式下基本等于把独显当集显用。 比之前的切片模式节约了至少三分之一的时间。 (有时候可能还不如CPU+.ccp加速快) 发表回复 取消回复此站点使用Akismet来减少垃圾评论。了解我们如何处理您的评论数据。 |
【本文地址】
今日新闻 |
推荐新闻 |