搞定,爬取公众号文章转换成PDF,自动邮件发送给自己! |
您所在的位置:网站首页 › 公众号文章变pdf › 搞定,爬取公众号文章转换成PDF,自动邮件发送给自己! |
搞定,爬取公众号文章转换成PDF,自动邮件发送给自己!
|
一、写在前面
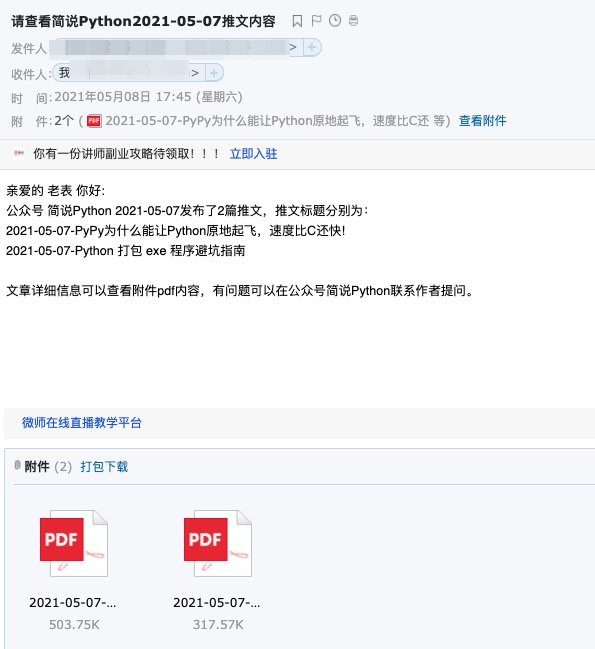
这也是一个读者的需求,之前也有读者提到过,趁五一还在假期中(调休几天),给大家一并解决了,拿到需求,先简单分析下,然后百度下,基本解决方法就有了,哈哈哈哈! 最后呈现效果:
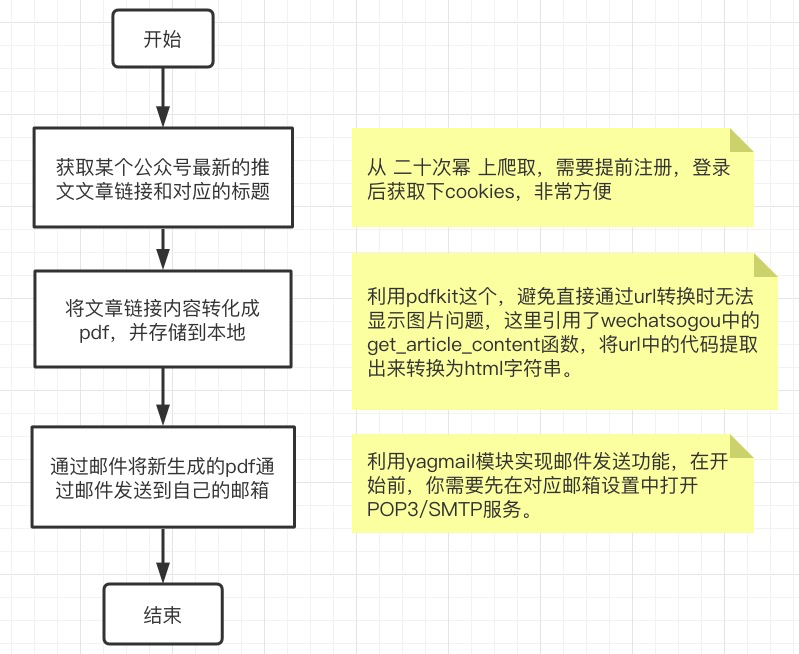
本需求主要分为三个部分: 爬取到公众号发布文章的链接和标题这块,目前网络上有的一些方法有:从搜狗微信上爬取(有个现成的框架wechatsogou[1],不过好像已经好久没人维护了,链接获取功能测试失败)、从微信公众号后台爬取(需要大家注册微信公众号,麻烦),这里我用的方法是直接从第三方数据平台爬取(简单)。 我选择了志军大佬开发的二十次幂平台[2],这里也给大家安利下这个网站,除了一些公众号主可以用,读者朋友也可以在上面查看全网热文以及喜欢的公众号的历史文章等。 将公众号链接内容转换为pdf这里利用pdfkit这个库,避免直接通过url转换成pdf时出现的无法显示图片问题,我们本次引用了wechatsogou[1]中的get_article_content函数,将url中的代码提取出来转换为html字符串,具体源码我简单看了下,有兴趣的也可以私聊我一起研究下(空闲的时候)。 通过邮件将pdf以附件形式发送这一步蛮简单的,利用yagmail模块实现邮件发送功能,在开始前,我们需要先在对应邮箱的设置中打开POP3/SMTP服务,这样才能使用,不然会提示没有权限。
等。。。 三、开始动手动脑 3.1 本次项目需要导入的库 import requests # 发送get/post请求,获取网站内容 import wechatsogou # 微信公众号文章爬虫框架 import json # json数据处理模块 import datetime # 日期数据处理模块 import pdfkit # 可以将文本字符串/链接/文本文件转换成为pdf import os # 系统文件管理 import re # 正则匹配模块 import yagmail # 邮件发送模块 import sys # 项目进程管理 3.2 爬取到公众号发布文章的链接和标题 ''' 1、从二十次幂获取公众号最新的推文链接和标题 ''' def get_data(publish_date): # 添加Cookie 记录登录状态 header = { 'Cookie': "获取方法见下文" } # 可以自定义设置获取文章的发布时间区间,日期越多,获取到的文章越多,本项目默认获取前一天的数据 start_at = publish_date end_at = publish_date # 每次只爬去前一天的数据 url1 = 'https://www.ershicimi.com/api/stats/articles?' # bid=EOdxnBO4 表示公众号 简说Python,每个公众号都有对应的bid,可以直接搜索查看 url2 = 'page=1&page_size=50&bid=EOdxnBO4&start_at={0}&end_at={1}&position=all'.format(start_at,end_at) url3 = url1+url2 r = requests.get(url3, headers=header) json_data = json.loads(r.text) html_data = json_data['data']['articles'] # print(html_data) return html_data如何获取你自己登录二十次幂后的Cookie:首先我们需要知道为什么需要这个玩意。我们如果直接访问我上面提供的链接会发现print(html_data)出来的是登录页面的源码,这也是一个比较基本的反爬手段–需要登录后才可以访问网站内的数据。 针对这个反爬手段,最简单的反反爬虫手段就是手动登录后获取Cookie,这里会记录我们的登录信息,让我们再访问这类页面的时候让系统以为我们是已经登录过了的人,不过Cookie是有时效的,所以这种方法还蛮麻烦的。 还有种简单方法,直接通过代码传参,然后登录二十次幂,保持Session,然后再去访问我们想访问的数据页面就可以了,这个我简单的利用requests.session()试了下,没成功,有兴趣的同学可以试试,这样就不用每天运行代码前还需要手动到页面登录获取Cookie,欢迎试成功的同学在评论区或者微信和我分享下,我也会第一时间和大家分享。 手动获取Cookie方法:1)注册好二十次幂后(网站地址见文末参考链接注释),在登录页面填写账号相关信息,点击登录按钮登录。 |
 2)按住F12调出浏览器的开发者工具,选择Network,然后刷新页面,在Network会出现网页加载过程中的一些内容,找到下图中打红框的login?next=%2Fsearch%2Faccount,点击一下,右侧就会出现请求相关信息,找到Request Headers中的Cookie后对应的一长串字符串就是我们需要的Cookie值。
2)按住F12调出浏览器的开发者工具,选择Network,然后刷新页面,在Network会出现网页加载过程中的一些内容,找到下图中打红框的login?next=%2Fsearch%2Faccount,点击一下,右侧就会出现请求相关信息,找到Request Headers中的Cookie后对应的一长串字符串就是我们需要的Cookie值。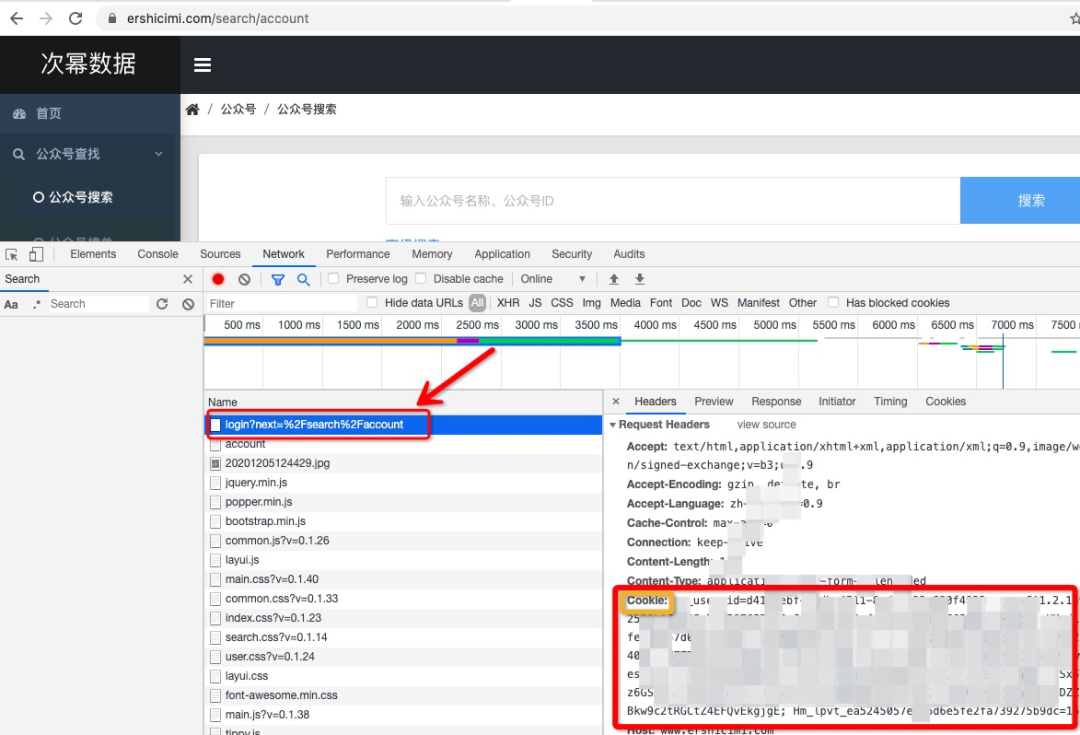
【本文地址】
今日新闻 |
推荐新闻 |