贴吧热议榜的爬取和数据分析 |
您所在的位置:网站首页 › 全球热议榜 › 贴吧热议榜的爬取和数据分析 |
贴吧热议榜的爬取和数据分析
|
一、选题的背景 贴吧即百度贴吧,是百度旗下独立品牌,全球领先的中文社区。贴吧的草根性,娱乐性,主题鲜明使其可以迅速聚集相同爱好的年轻人,基于关键字的搜索引擎是基于话题的贴吧的天然入口,百度的流量可以轻松地把贴吧的人气撑起来,基本无需推广,加上贴吧的低门槛,用户可以自行创建管理,它的整体内容更宽泛几乎涉及所有的领域。通过对贴吧热议榜的爬取与数据可视化分析,能够更好了解当代青年所关注的社会热点。 二、主题式网络爬虫设计方案 1.主题式网络爬虫名称:爬取百度贴吧热议榜数据并数据分析及可视化 2.主题式网络爬虫爬取的内容与数据特征分析 爬取内容:对贴吧热议榜的“排名”,“标题”,“内容量(热度)”三个数据进行爬取 3.主题式网络爬虫设计方案概述 实现思路:登录百度贴吧,进入贴吧热议界面,进入网页开发人员工具,得到网页源代码,查找所需标签的代码,进行数据采集,完成后对数据进行相应的分析整理并存入文档中。读取文件进行数据清洗和数据可视化,绘制图形进行数据分析。接下来分析排行和热度的数据拟合分析,最后进行数据持久化。 技术难点:爬取信息时对标签的寻找,回归方程运用得不够熟练。 三、主题页面的结构特征分析 1.主题页面的结构与特征分析 通过对页面结构的分析,发现元素中,发现所需要的数据。并进行查找,在标签,,分别找到排名,标题,内容(热度)的数据。 2.Htmls 页面解析 通过查找网页源代码,浏览其中元素,并对其中元素进行解析,随后逐级向下查找标签,直到找到所需要的标签为止。
3.节点(标签)查找方法与遍历方法
四、网络爬虫程序设计 1.数据爬取与采集 #网页的爬取 1 #百度贴吧爬取 2 url = 'http://tieba.baidu.com/hottopic/browse/topicList?res_type=1&red_tag=o3177405460' 3 # 爬虫请求头信息 4 headers = { 5 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36 Edg/96.0.1054.62' 6 } 7 #定义函数获取并检测页面信息 8 def Text(url): 9 10 try: 11 respone = requests.get(url,headers=headers,timeout=30) 12 respone.raise_for_status() 13 #解决中文字符编码问题 14 respone.encoding = respone.apparent_encoding 15 return respone.text 16 except: 17 return "" 18 html = Text(url) 19 #使用BeautifulSoup解析页面信息 20 soup = BeautifulSoup(html, "html.parser")
#数据收集 1 #收集标题 2 a=[] 3 for m in soup.find_all(class_='topic-text'): 4 a.append(m.get_text().strip()) 5 print(a)
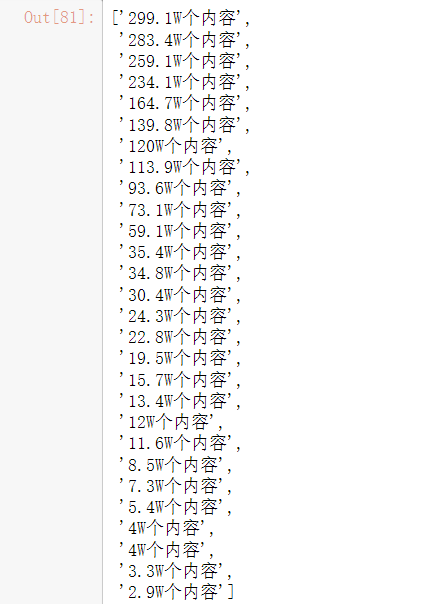
1 #收集内容 2 b=[] 3 for m in soup.find_all(class_='topic-num'): 4 b.append(m.get_text().strip()) 5 print(b)
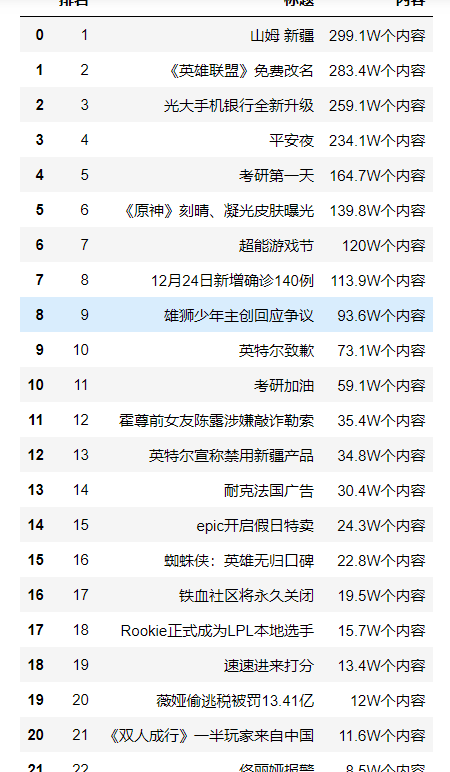
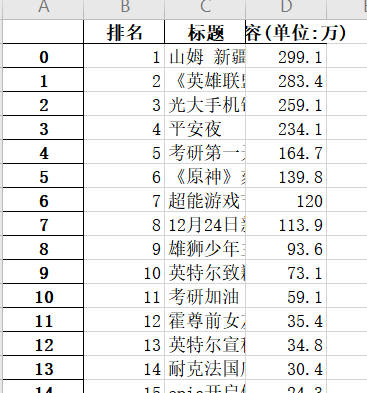
1 #数据整理 2 num=28 3 lst=[] 4 for i in range(num): 5 print('{:^5}\t{:^40}\t{:^10}'.format(i+1, a[i], b[i])) 6 lst.append([i+1, a[i], b[i]]) 7 df = pd.DataFrame(lst,columns=['排名','标题','内容']) 8 print(df)
#保存数据 1 #保存至excel表 2 cwh = r'cwh.xlsx' 3 df.to_excel(cwh)2.对数据进行清洗和处理 #读取文档 1 #读取表格 2 cwh=pd.DataFrame(pd.read_excel('cwh.xlsx')) 3 print(cwh.head())
1 #删除无效列 2 df.drop('标题', axis = 1, inplace=True) 3 df.head()
1 #检查并显示重复值 2 print(df.duplicated())
1 #删除重复值 2 df = df.drop_duplicates() 3 df.head()
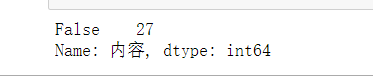
1 #检查是否有空值 2 print(df['内容'].isnull().value_counts())
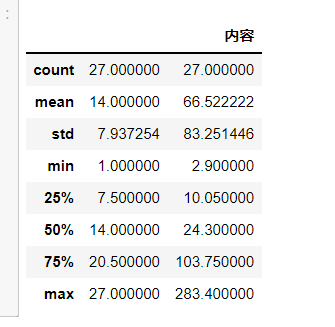
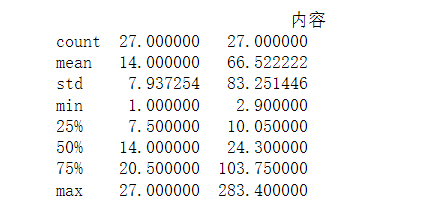
1 #异常值处理 2 df.describe()
1 #查看统计信息 2 print(df.describe())
3.数据分析与可视化(例如:数据柱形图、直方图、散点图、盒图、分布图) #数据可视化 1 #绘制柱状图 2 import pandas as pd 3 import numpy as np 4 import matplotlib.pyplot as plt 5 plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签 6 a = df.排名 7 b = df.内容 8 plt.bar(a,b, color='b') 9 plt.xlabel("排名") 10 plt.ylabel("热度") 11 plt.title('排名与热度数据柱状图') 12 plt.show()
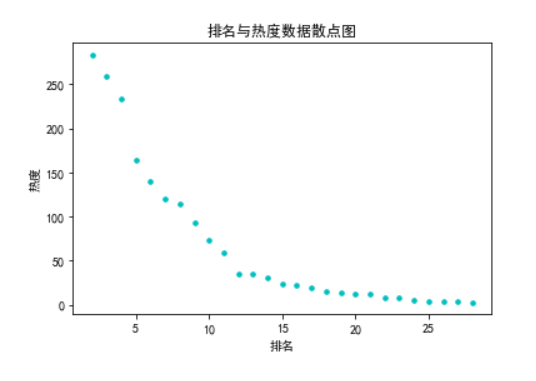
1 #绘制散点图 2 import matplotlib.pyplot as plt 3 plt.rcParams['font.sans-serif']=['SimHei'] #用于正常显示中文标签 4 size=50 5 plt.xlabel("排名") 6 plt.ylabel("热度") 7 plt.title('排名与热度数据散点图') 8 a = df.排名 9 b = df.内容 10 plt.scatter(a,b,size, color="c", marker='.') 11 plt.show
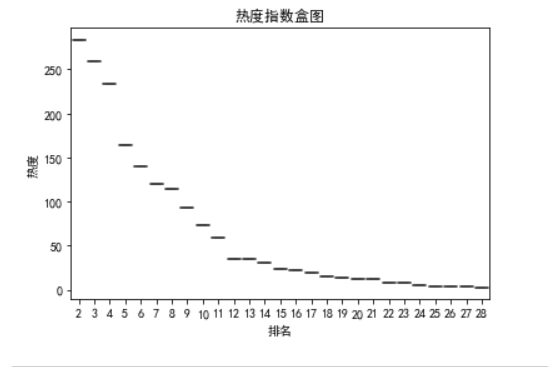
1 #绘制盒图 2 import seaborn as sns 3 def box(): 4 plt.title('热度指数盒图') 5 a = df.排名 6 b = df.内容 7 sns.boxplot(a,b) 8 plt.xlabel("排名") 9 plt.ylabel("热度") 10 box()
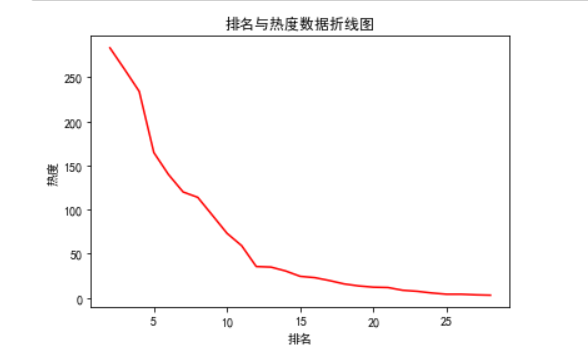
1 #绘制折线图 2 plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签 3 a = df.排名 4 b = df.内容 5 plt.plot(a,b, color='r') 6 plt.xlabel("排名") 7 plt.ylabel("热度") 8 plt.title('排名与热度数据折线图') 9 plt.show()
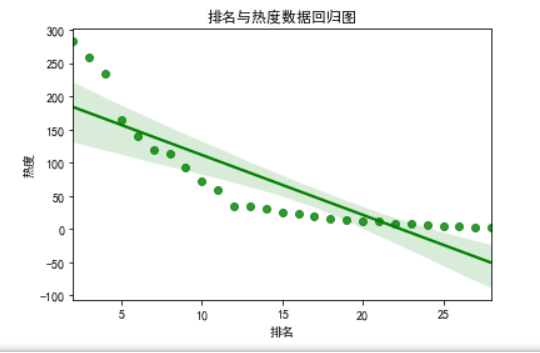
1 #绘制回归图 2 import seaborn as sns 3 plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签 4 a = df.排名 5 b = df.内容 6 sns.regplot(a,b,color='g') 7 plt.xlabel("排名") 8 plt.ylabel("热度") 9 plt.title('排名与热度数据回归图') 10 plt.show()
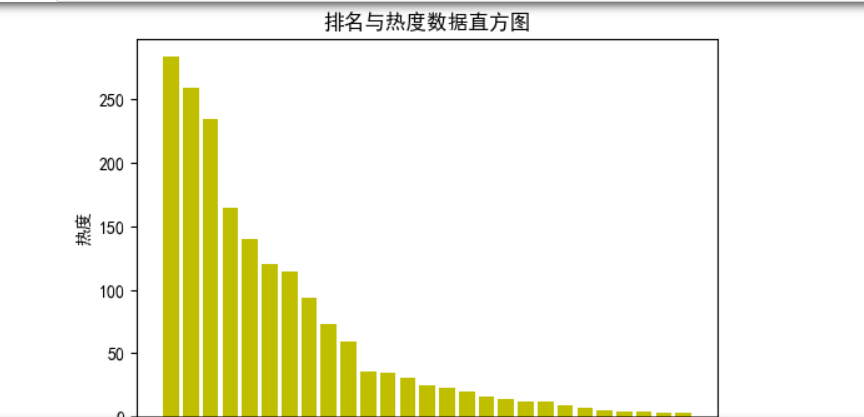
1 #绘制直方图 2 plt.figure(dpi=100) 3 a = df.排名 4 b = df.内容 5 plt.bar(a,b,color='y') 6 plt.title("排名与热度数据直方图") 7 plt.xlabel("排名") 8 plt.ylabel("热度") 9 plt.show()
通过以上图形分析:热度与排名关系呈现负相关。并且最高排名与最低排名之间差距较大。
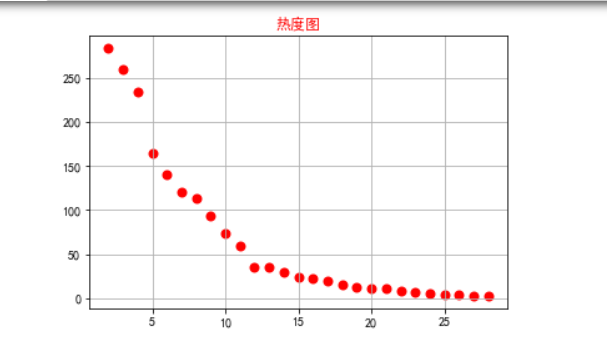
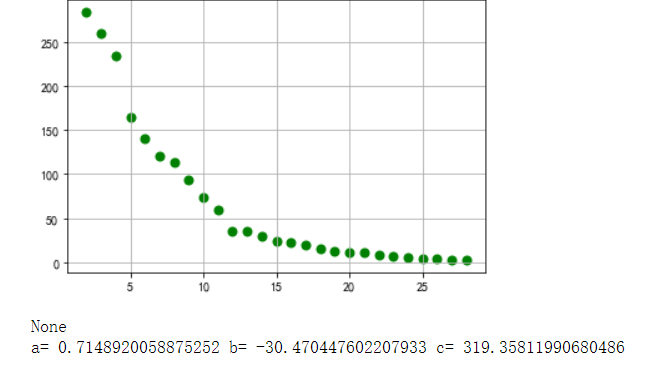
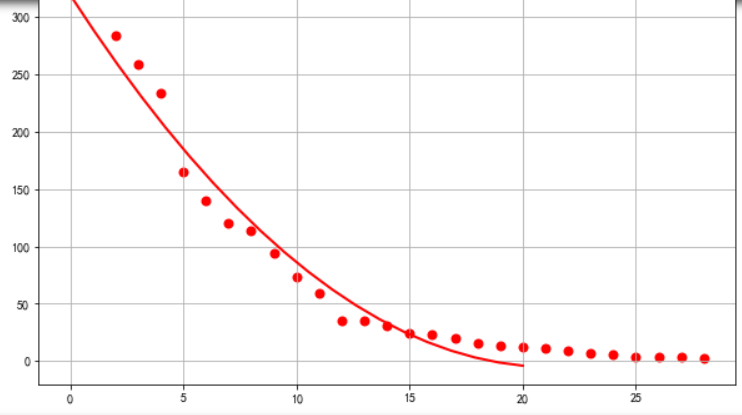
5.根据数据之间的关系,分析两个变量之间的相关系数,画出散点图,并建立变 量之间的回归方程(一元或多元)。 #选择排名以及内容数(热度)两个特征变量,绘制分布图,用最小二乘法分析两个变量间的二次拟合方程和拟合曲线 1 plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签 2 plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号 3 colnames=[" ","排名","标题","内容"] 4 df = pd.read_excel(r'cwh.xlsx',skiprows=1,names=colnames) 5 X = df.排名 6 Y = df.内容 7 Z = df.标题 8 #绘制分布图 9 def A(): 10 plt.scatter(X,Y,color="r",linewidth=2) 11 plt.title("热度图",color="r") 12 plt.grid() 13 plt.show() 14 def B(): 15 plt.scatter(X,Y,color="green",linewidth=2) 16 plt.title("",color="b") 17 plt.grid() 18 plt.show() 19 #建立方程 20 def func(p,x): 21 a,b,c=p 22 return a*x*x+b*x+c 23 def error(p,x,y): 24 return func(p,x)-y 25 #定义主函数 26 def main(): 27 plt.figure(figsize=(10,6)) 28 p0=[0,0,0] 29 Para = leastsq(error,p0,args=(X,Y)) 30 a,b,c=Para[0] 31 print("a=",a,"b=",b,"c=",c) 32 plt.scatter(X,Y,color="r",linewidth=2) 33 x=np.linspace(0,20,20) 34 y=a*x*x+b*x+c 35 plt.plot(x,y,color="r",linewidth=2,) 36 plt.title("内容分布") 37 plt.grid() 38 plt.show() 39 print(A()) 40 print(B()) 41 print(main())
6.数据持久化 1 #数据持久化 2 df = pd.DataFrame(lst, columns=['排名','标题','内容(单位:万)']) 3 df.to_excel('cwh.xlsx')
7.将以上各部分的代码汇总,附上完整程序代码 1 from bs4 import BeautifulSoup 2 import requests 3 import pandas as pd 4 import time 5 import random 6 7 from matplotlib import pyplot as plt 8 import numpy as np 9 10 from numpy import genfromtxt 11 import matplotlib.pyplot as plt 12 import matplotlib 13 from scipy.optimize import leastsq 14 15 #百度贴吧爬取 16 url = 'http://tieba.baidu.com/hottopic/browse/topicList?res_type=1&red_tag=o3177405460' 17 # 爬虫请求头信息 18 headers = { 19 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36 Edg/96.0.1054.62' 20 } 21 #定义函数获取并检测页面信息 22 def Text(url): 23 24 try: 25 respone = requests.get(url,headers=headers,timeout=30) 26 respone.raise_for_status() 27 #解决中文字符编码问题 28 respone.encoding = respone.apparent_encoding 29 return respone.text 30 except: 31 return "" 32 html = Text(url) 33 #使用BeautifulSoup解析页面信息 34 soup = BeautifulSoup(html, "html.parser") 35 36 #数据收集 37 #收集标题 38 a=[] 39 for m in soup.find_all(class_='topic-text'): 40 a.append(m.get_text().strip()) 41 print(a) 42 43 #收集内容 44 b=[] 45 for m in soup.find_all(class_='topic-num'): 46 b.append(m.get_text().strip()) 47 print(b) 48 49 #数据整理 50 num=28 51 lst=[] 52 for i in range(num): 53 print('{:^5}\t{:^40}\t{:^10}'.format(i+1, a[i], b[i])) 54 lst.append([i+1, a[i], b[i]]) 55 df = pd.DataFrame(lst,columns=['排名','标题','内容']) 56 print(df) 57 58 #保存至excel表 59 cwh = r'cwh.xlsx' 60 df.to_excel(cwh) 61 62 #数据清洗 63 #读取表格 64 cwh=pd.DataFrame(pd.read_excel('cwh.xlsx')) 65 print(cwh.head()) 66 67 #删除无效列 68 df.drop('标题', axis = 1, inplace=True) 69 df.head() 70 71 #检查并显示重复值 72 print(df.duplicated()) 73 74 #删除重复值 75 df = df.drop_duplicates() 76 df.head() 77 78 #检查是否有空值 79 print(df['内容'].isnull().value_counts()) 80 81 #异常值处理 82 df.describe() 83 84 #查看统计信息 85 print(df.describe()) 86 87 #数据可视化 88 #绘制柱状图 89 import pandas as pd 90 import numpy as np 91 import matplotlib.pyplot as plt 92 plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签 93 a = df.排名 94 b = df.内容 95 plt.bar(a,b, color='b') 96 plt.xlabel("排名") 97 plt.ylabel("热度") 98 plt.title('排名与热度数据柱状图') 99 plt.show() 100 101 #绘制散点图 102 import matplotlib.pyplot as plt 103 plt.rcParams['font.sans-serif']=['SimHei'] #用于正常显示中文标签 104 size=50 105 plt.xlabel("排名") 106 plt.ylabel("热度") 107 plt.title('排名与热度数据散点图') 108 a = df.排名 109 b = df.内容 110 plt.scatter(a,b,size, color="c", marker='.') 111 plt.show 112 113 #绘制盒图 114 import seaborn as sns 115 def box(): 116 plt.title('热度指数盒图') 117 a = df.排名 118 b = df.内容 119 sns.boxplot(a,b) 120 plt.xlabel("排名") 121 plt.ylabel("热度") 122 box() 123 124 #绘制折线图 125 plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签 126 a = df.排名 127 b = df.内容 128 plt.plot(a,b, color='r') 129 plt.xlabel("排名") 130 plt.ylabel("热度") 131 plt.title('排名与热度数据折线图') 132 plt.show() 133 134 #绘制回归图 135 import seaborn as sns 136 plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签 137 a = df.排名 138 b = df.内容 139 sns.regplot(a,b,color='g') 140 plt.xlabel("排名") 141 plt.ylabel("热度") 142 plt.title('排名与热度数据回归图') 143 plt.show() 144 145 #绘制直方图 146 plt.figure(dpi=100) 147 a = df.排名 148 b = df.内容 149 plt.bar(a,b,color='y') 150 plt.title("排名与热度数据直方图") 151 plt.xlabel("排名") 152 plt.ylabel("热度") 153 plt.show() 154 155 #选择排名以及内容数(热度)两个特征变量,绘制分布图,用最小二乘法分析两个变量间的二次拟合方程和拟合曲线 156 plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签 157 plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号 158 colnames=[" ","排名","标题","内容"] 159 df = pd.read_excel(r'cwh.xlsx',skiprows=1,names=colnames) 160 X = df.排名 161 Y = df.内容 162 Z = df.标题 163 #绘制分布图 164 def A(): 165 plt.scatter(X,Y,color="r",linewidth=2) 166 plt.title("热度图",color="r") 167 plt.grid() 168 plt.show() 169 def B(): 170 plt.scatter(X,Y,color="green",linewidth=2) 171 plt.title("",color="b") 172 plt.grid() 173 plt.show() 174 #建立方程 175 def func(p,x): 176 a,b,c=p 177 return a*x*x+b*x+c 178 def error(p,x,y): 179 return func(p,x)-y 180 #定义主函数 181 def main(): 182 plt.figure(figsize=(10,6)) 183 p0=[0,0,0] 184 Para = leastsq(error,p0,args=(X,Y)) 185 a,b,c=Para[0] 186 print("a=",a,"b=",b,"c=",c) 187 plt.scatter(X,Y,color="r",linewidth=2) 188 x=np.linspace(0,20,20) 189 y=a*x*x+b*x+c 190 plt.plot(x,y,color="r",linewidth=2,) 191 plt.title("内容分布") 192 plt.grid() 193 plt.show() 194 print(A()) 195 print(B()) 196 print(main()) 197 198 #数据持久化 199 df = pd.DataFrame(lst, columns=['排名','标题','内容(单位:万)']) 200 df.to_excel('cwh.xlsx')五、总结 1.经过对主题数据的分析与可视化,可以得到哪些结论?是否达到预期的目标? 根据数据分析可以发现,热度会随排名的降低而下降,图表可以更为直观的表现出排名与热度的关系和变化和反映出各个话题之间热度的差距。同时,经过结合标签“标题”进行分析,可以发现当代青年的关注点大致分布在“消费”“社会新闻”“游戏”这些领域。 2.在完成此设计过程中,得到哪些收获?以及要改进的建议? 在完成此次设计的途中可谓是九九八十一难,无论是网站爬取,图表制作还是数据分析,都出现过大大小小的问题。例如在寻找要爬取的网站时,曾因为无法找到相关信息,出现乱码等,不得不反反复复更换十来个网站进行爬取。在绘制图表的过程中,也因为饼状图,堆叠图,3d散点图等图表制作的不熟练导致频频失误,最后只好放弃,改用其他图表。但在此次设计的重重“劫难”中也让我学到了许多知识。首先,为了这次设计,我不得不求学于我的课本以及之前上的网课,回忆重温之前的教学内容,除了令我对老师深厚的教学水准深感敬佩外,还巩固了我的课内知识。其次,在遇到课本也解决不了的问题的时候,我学会了去利用同学 与网络渠道去解决疑惑。这既锻炼了我的交流能力,同时也让我学习了颇多的课外知识,真是令我受益匪浅啊。此次作业,或许有很多不足,但是,这也令我意识到了自己的水平是多么的有限,对python这一门课程的理解是多么的有限。但是,这些不足也激起了我对python这门课程研究的动力。最后,我希望通过此次经历,会使我在以后的学习中,更加努力的提高自己的能力,掌握更深的知识。 |







【本文地址】