【Python爬虫+pyecharts可视化】爬取全国各地房价并在echarts的geo地图上展示 |
您所在的位置:网站首页 › 全国各地省会名称 › 【Python爬虫+pyecharts可视化】爬取全国各地房价并在echarts的geo地图上展示 |
【Python爬虫+pyecharts可视化】爬取全国各地房价并在echarts的geo地图上展示
|
导言 最近回归了可视化,写个文章总结一下经验教训,嘿嘿。不想看分析过程的可以点击目录,直接跳转到代码实现部分。(代码所用模块都是可以用 pip install 模块名 下载的哟) 先看看最终效果:
目录 项目需求 总体分析 详细分析 代码实现 代码测试 维护更新 项目需求获取全国各地的房价,计算出平均值,并用echarts中的geo图表进行展示。 总体分析 爬取数据过程 利用爬虫获取全国房价。将获取的房产信息存储在csv文件中。处理csv文件中的数据,筛选出所需字段,并计算出各地房价平均值,最后保存在另一个csv文件中。 可视化过程 制作echarts中的geo地理图表。将数据导入geo图表。修饰geo图表。 详细分析 爬取的是链家网的房价。所使用的是Python中的requests模块进行爬取。Python中有很多适用于爬虫的模块,例如urllib.request 。本次我们仅介绍requests模块。requests模块集成了大量适用于请求相关的函数,感兴趣的可以先自行搜索requests相关文档,后续有空我会上传。本次使用requests中的get()函数获取HTML页面代码。利用Python中的BeautifulSoup模块解析爬取的html代码。Python中也有很多解析网页的模块,例如DOM。本次我们仅介绍bs4模块。(bs4是BeautifulSoup4的缩写,代表着它已经发展到了第四代版本。) 补充:为什么需要解析页面? 页面原本是纯粹的HTML代码,Python中如果想要操作这些HTML代码(准确说应该是页面中的标记,如div,span),需要将这些HTML代码转换为Python能处理的东西——对象。所以一般会通过某种解析器将获取到的HTML代码转换为HTML对象,便于我们使用Python代码对这些对象进行增删改查的操作。具体内容可以百度搜索一下HTML解析器。(目前主要掌握使用解析器的目的即可)。利用CSS选择器选择页面中的需要的标记。获取标记中的内容,写入保存在csv文件中。利用pandas模块读取数据。利用pandas处理数据,主要操作是根据自行需求进行数据处理。例如本案例中的需求就是,筛选出所有数据的【省会名称】、【价格】两项,并且对价格进行分组、求平均操作。将处理后的数据重新保存在另一个csv文件中备用。利用pyecharts模块显示备用csv文件中的数据。 代码实现一共三个代码文件。会产出两个csv文件和一个html文件。 第一个文件,爬虫文件。下方代码中大部分内容已经添加注释,主要思路是爬取全部页面中的数据,并且保存在csv文件中。如果有需要了解或者可以优化的部分欢迎大家留言(づ ̄3 ̄)づ╭❤~。 # 自动获取全国房价 from bs4 import BeautifulSoup import requests import random import time import csv import math # 链家【新房】链接的入口地址 url = 'https://bj.fang.lianjia.com/' Agent = [ 'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0', 'Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10', 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36', 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11', 'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)', 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36' ] SumCount = 0 # 所有页面总共的房产数量 flag = True # 控制值写入一次csv文件头 filename = '全国房产信息.csv' title = ['省会名称', '楼盘名称', '所在区域', '详细地址', '室厅数量', '建筑面积', '价格'] # 生成response对象 def getResponse(u): user_agent = random.choice(Agent) headers = {'User-Agent': user_agent} r = requests.get(u, headers=headers) r.encoding = r.apparent_encoding return r # 获取所有城市链接 存储在 标签中 所有后代元素 保定 # 返回 包含所有{'城市名称':'链接'}的字典 def getHref(u): city_name_href_dict = {} r = getResponse(u) if r.status_code == 200: html = r.text tagList = getTag(html, 'li.clear a') city_href_list = getAttributeFromTag(tagList, 'href') city_name_list = getAttributeFromTag(tagList, 'title') # 利用遍历,将城市名称和链接,添加至字典中 for i in range(0, len(city_name_list)): key = city_name_list[i] href = city_href_list[i] value = "http:" + href + '/loupan/' city_name_href_dict[key] = value return city_name_href_dict else: print('获取所有城市链接时失败') return str(r.status_code) # 获取最大页码 参数 :地址 def getMaxPageNum(u): r = getResponse(u) tag = getTag(r.text, 'div.page-box') # tag[0]['data-total-count'] tag[0]获取包含总房产数量的div对象, ['data-total-count']获取其身上的总房产数量属性值 allPage = int(tag[0]['data-total-count']) maxPageNum = math.ceil(allPage / 10) return maxPageNum # 获取页面标记组 def getTag(html, element): soup = BeautifulSoup(html, 'html.parser') tagList = soup.select(element) return tagList # 获取一页内城市信息 def getCityInfo(city_TagList, p): global SumCount AllList = [] # 存储所有的list pageInsideCount = 0 # 一个页面内几条数据 for tag in city_TagList: city_tag_list = [] # 信息可能不存在 try: # 获取信息 provinceName = p cityName = tag.select('div.resblock-name a') cityLocation = tag.select('div.resblock-location span') cityAddress = tag.select('div.resblock-location a') cityRoom = tag.select('a.resblock-room span') # 几室几厅 cityArea = tag.select('div.resblock-area span') # 建筑面积 cityPrice = tag.select('div.resblock-price span.number') # 向列表中添加房产信息 city_tag_list.append(provinceName) # 省会名称 city_tag_list.append(cityName[0].text) # 依次添加每一个内容到list中 city_tag_list.append(cityLocation[0].text) city_tag_list.append(cityAddress[0].text) city_tag_list.append(cityRoom[0].text) city_tag_list.append(cityArea[0].text) city_tag_list.append(cityPrice[0].text) except AttributeError as e: # 没有text属性 print('没有获取到房产信息对象') except IndexError as e1: # 没有获取到某个标记,而导致[0]操作时,下标越界 # 信息可能不存在,判断不存在则添加空串避免出错。 if 0 == len(cityName): cityName = ['null'] if 0 == len(cityLocation): cityLocation = ['null'] if 0 == len(cityAddress): cityAddress = ['null'] if 0 == len(cityRoom): cityRoom = ['null'] if 0 == len(cityArea): cityArea = ['null'] if 0 == len(cityPrice): cityPrice = ['null'] AllList.append(city_tag_list) # 将list放入AllList中 形成二维数组,一会便于写入csv pageInsideCount = pageInsideCount + 1 SumCount = SumCount + pageInsideCount print("本页共" + str(pageInsideCount) + "条数据") return AllList # 从标记组中获取某标签某属性包含的连接 存储到字典中返回 def getAttributeFromTag(tagList, attr): attr_list = [] for tag in tagList: value = tag[attr] # value = "http:" + href + '/loupan/' # 需要/loupan资源才能访问到房产信息首页页面 attr_list.append(value) return attr_list # 获取各个城市房产信息 def getBuildingInfo(c_dict): # 文件名 global filename key_list, value_list = [], [] # 获取所有城市名 for key in c_dict: key_list.append(key) value_list.append(c_dict[key]) # c_list全部城市首页链接 for city_url in value_list: # 获取当前城市最大页面数字 maxPageNum = getMaxPageNum(city_url) # 遍历当前城市所有页面 for pageNum in range(1, maxPageNum + 1): # 拼接所有页面地址 r_city_url = city_url + '/pg' + str(pageNum) # city_response 每个城市对应的响应对象 city_response = getResponse(r_city_url) if 200 == city_response.status_code: html = city_response.text #这里去掉了选择其中的.has-results 部分,因为有的页面中li的类名仅为下方内容,并不包含.has-results 部分 building_tagList = getTag(html, 'ul.resblock-list-wrapper li.resblock-list.post_ulog_exposure_scroll') # 每一个城市房产列表 所有的li # value_list.index() 获取指定元素下标 这里是获取下标之后,再获取key_list中对应下标的城市名称 province = key_list[value_list.index(city_url)].split('房')[ 0] # key_list[value_list.index(city_url)] 内容为 xx房产网 # 获取到所有li后获取其中的房屋信息 building_info_list是二维列表 building_info_list = getCityInfo(building_tagList, province) # 当前页面所有房屋信息的二维列表 saveData(filename, building_info_list) print("获取【" + province + "】的第【" + str(pageNum) + "】页已经完成...") print('睡一秒...') time.sleep(1) print('继续!') print("【" + province + "】所有页已经完成...") print('睡一秒...') time.sleep(1) print('下一座城市!') print("全国共【" + str(SumCount) + "】条数据") # return building_info_list # 保存数据 def saveData(fname, b_info_list): global title, flag with open(fname, 'a',newline='',encoding='utf-8') as f: csvFile = csv.writer(f) if flag: csvFile.writerow(title) flag = False csvFile.writerows(b_info_list) # 写多行 也就是二维数组的时候用writerows() 一维数组用writerow() print('数据写入完成!') # 获取所有城市链接 cityLinkList = getHref(url) # 获取各个城市房产信息 二维列表 getBuildingInfo(cityLinkList)第二个文件,处理csv中数据的文件。这是还是强调一下,处理数据使用的是pandas模块,这个模块比较“沉重”,可以选择使用csv模块处理数据。pandas模块有些函数也不是很好用。(我才不会说是我不会用。) 另外,这个文件没有固定的内容,需要根据自己的需求去修改。比如,可能会对数据【去重】【排序】【分组】【求和】【求平均】等等,所以在处理数据这一块儿需要自己花点时间学习。 # 将全国房价清洗为各省市平均值 import csv import pandas as pd import numpy # 读取csv文件 def getCsvFile(csvName): dataFrame = pd.read_csv(csvName + '.csv') return dataFrame # 处理数据 def processData(df): df_list = [] df = df.drop_duplicates("楼盘名称") row_indexs = df[df['价格'] == '价格待定'].index.tolist() df = df.drop(axis=0, labels=row_indexs) # 分组 # 是个生成器 group = df['价格'].groupby(df['省会名称']) for g in group: result_list = [] # g[1].tolist() -- ['22000', nan, nan, nan, nan, nan, nan, '17000'] 每个省会对应的房价列表 l = g[1].tolist() # 高效去除nan while numpy.nan in l: l.remove(numpy.nan) # 把所有str转换为int l = [int(x) for x in l] # 求平均 avg_l = float('%.2f' % numpy.mean(l)) # 制作列表作为返回值使用 # g[0] -- 省会名称 result_list.append(g[0]) result_list.append(avg_l) df_list.append(result_list) return df_list # 存储处理后的csv文件 def saveCsvFile(csvData, csvName): title = ['省会名称', '价格'] r_csvName = csvName + 'v1.csv' with open(r_csvName, 'w', newline='') as f: csvFile = csv.writer(f) csvFile.writerow(title) for i in csvData: csvFile.writerow(i) csvFilename = '全国房产信息' csv_df = getCsvFile(csvFilename) result_df = processData(csv_df) saveCsvFile(result_df, csvFilename)第三个文件,将数据可视化处理的文件。啊最喜欢的文件来了,有了它我们的数据就会变得很直观、漂亮了。但是之前玩的是js的echarts,此文件使用的是pyecharts。它是python为了便捷学习、操作echarts专门制作的模块,可以实现部分主要的echarts功能。但是说句实在话,习惯了前端后端分开,把原本前端的东西放在后端,有点整的不会了。。api很多,每一个都可以自己试着玩一玩,下方代码中我自己试着玩了一些,剩下的欢迎大家自己测试。 还有,在这里顺便向各路大神请教个问题,如何利用pyecharts中实现 legend(图例)的单击事件。我想实现点击各个城市名称跳转到对应城市地图的操作。🙏 from pyecharts import options as opts from pyecharts.charts import Geo import pandas as pd from pyecharts.options import TextStyleOpts csvFilename = '全国房产信息v1.csv' province_list = [] price_list = [] df = pd.read_csv(csvFilename) province_list = df['省会名称'].tolist() price_list = df['价格'].tolist() # 生成全国各省市平均房价显示图 c = ( Geo( # 设置生成的div及页面属性 init_opts=opts.InitOpts( width='1700px', height='750px', page_title='全国各省市平均房价', )) .add_schema(maptype="china") .add_coordinate('保亭',109.70259,18.63905) .add_coordinate('乐东',109.17361,18.74986) .add_coordinate('陵水',110.0372,18.50596) .add("城市名", [list(z) for z in zip(province_list, price_list)]) .set_series_opts( label_opts=opts.LabelOpts( is_show=True, formatter='{b}', ) ) .set_global_opts( visualmap_opts=opts.VisualMapOpts( is_piecewise=True, min_=0, max_=40000, range_size=10000 ), title_opts=opts.TitleOpts( title="全国各省市平均房价", # title_link='http://www.baidu.com', # 点击标题跳转链接 # title_target=, #链接对应新窗口的打开方式 _blank _self # subtitle=, # subtitle_link=, # subtitle_target=, # item_gap=10, #主副标题之间的间距。 # title_textstyle_opts={ # 'color':'#dd23fb', # # }, #标题样式 是个字典 # subtitle_textstyle_opts={ # # }, #副标题样式 是个字典 ), legend_opts=opts.LegendOpts( legend_icon='circle', ), tooltip_opts=opts.TooltipOpts( is_show=True, trigger='item', axis_pointer_type='cross', is_always_show_content=False, # position=['10%','10%'], # formatter='{b0}: {c0}{b1}: {c1}' textstyle_opts= TextStyleOpts() ), ) .render("全国各省市平均房价.html") ) 代码测试首先,第一个文件中,在获取城市信息的时候可能会出现问题。 tag.select(element) element是我们获取目标数据的各项选择器,但是这个选择器有时会获取不到数据,比如,有的房产信息没有书写几室几厅,有的没有书写房价,这样就会导致数据获取不到而报错,所以,才有了如下的try except代码。
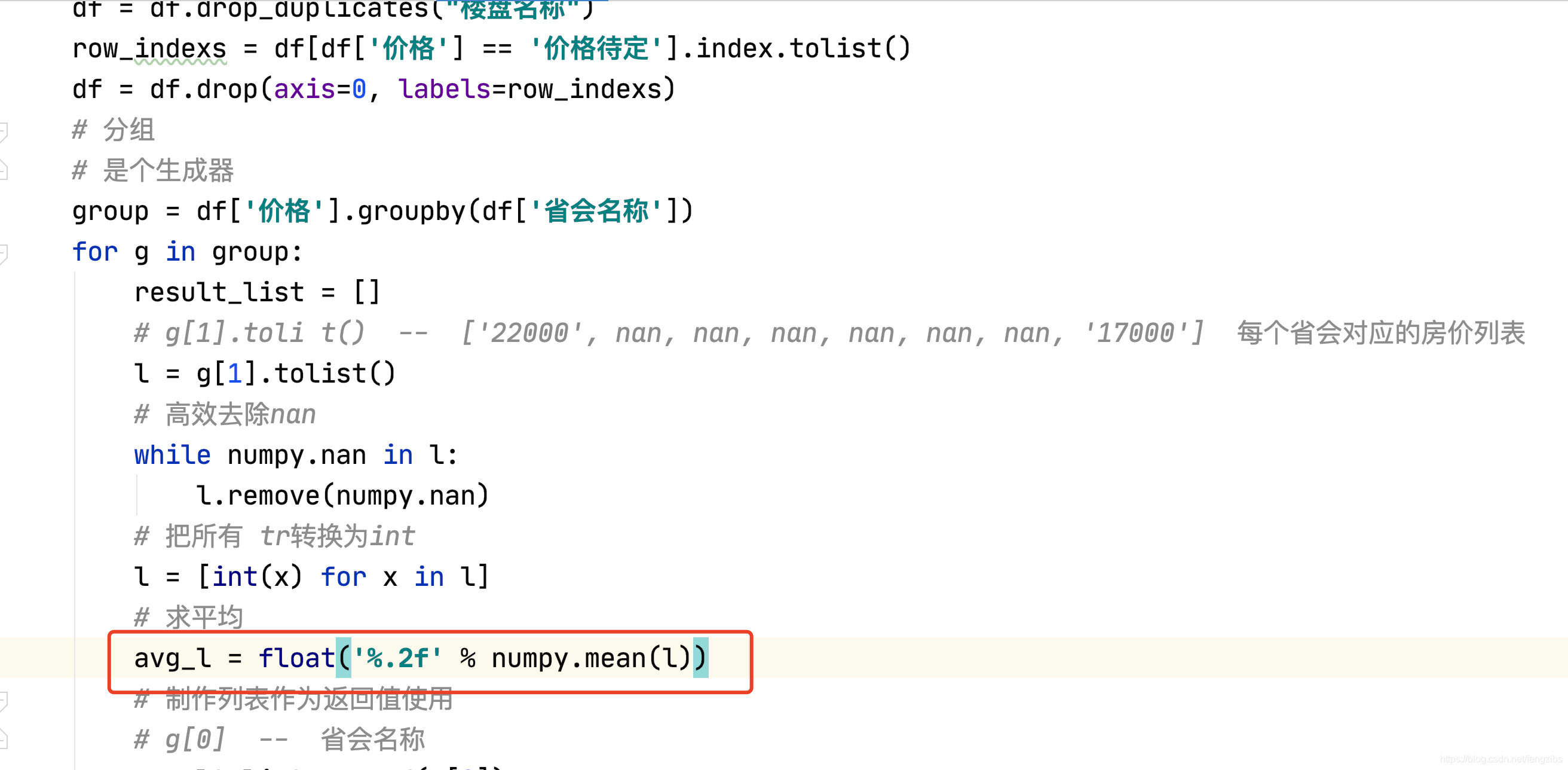
其次,第二个文件中,pandas处理数据过程中涉及到了分组、求平均的操作。(pandas分组方式比较简单,形式很多,可以百度自行学习。)根据以往数据库的经验,数据都是先分组,再聚合,所以这里也先将数据进行group()分组操作,然后求平均mean()。这个mean()函数有很多坑。我搜索了很多资料,他们的求平均代码是没有问题的,不过只适用于他们的数据,不适用于我的数据。查看之后发现csv文件中获取到的【房价】信息有的值是‘价格待定’,由于‘价格待定’是string类型的数据,且无法转换为int或float类型,这导致了'价格待定'这样的数据无法参与mean()函数的运算。,所以专门使用drop()函数将这些数据删除。重要的来了,就算删除了这些数据,仍然无法使用mean()函数。这一点困惑了我好久。最后无奈放弃了,使用了下图所示的方式。(谁会用pandas分组后的mean()求平均务必赐教,要哭了😢。) 图片中的主要思路是:删除价格待定的行,然后将数据分组,按照图中df['价格'].groupby(['省会名称'])来分组的话,它的含义是:根据【省会名称】分组,显示【价格】。这样产生的结果对象group将数据存储在了list中。因为list中的索引0对应着【省会名称】,索引1对应着【价格】。所以最后对索引1的数据进行处理。 下图中还用到了numpy.mean()函数,这个函数也是用于求平均的,但是并不适用与group对象,适用于list。
最后,第三个文件中,add()函数的第二个参数,需要的是二维数组的数据结构,也就是[['北京',50000],['上海',40000]]这样的数据。
我们可以通过for z in zip()来制作二位数组。 例如:for z in zip(list_1,list_2) 可以将list_1 和list_2的数据搅拌在一起。for 一个赞破: list_1 = [1, 2, 3, 4] list_2 = ['a', 'b', 'c'] for z in zip(list_1, list_2): print(z) print([list(z) for z in zip(['裕华', '长安', '桥西', '新华'], [17723, 19428, 18575, 15245])])输出: (1, 'a') (2, 'b') (3, 'c') [['裕华', 17723], ['长安', 19428], ['桥西', 18575], ['新华', 15245]]可以看到for z in zip() 本身是将两个list中的数据,按照顺序,一个一个将对应索引的数据,重新存储了一个tuple中。 然后我们可以再通过list()函数,将这个tuple快速转换为list。 补充测试: 在运行第三个文件生成HTML页面时,可能会报错: 显示某某地点不在。这是因为echarts中的geo图表内并未包含所有的城市坐标数据,没有的需要我们手动添加。 Traceback (most recent call last): pyecharts.exceptions.NonexistentCoordinatesException: 当前地点: ('保亭', 12388.89) 坐标不存在, 错误原因: cannot unpack non-iterable NoneType object Process finished with exit code 1添加这个城市的坐标即可。通过add_coordinate('城市名称',x地理坐标,y地理坐标) 。查看某城市坐标:https://jingweidu.bmcx.com/ c = ( Geo( # 设置生成的div及页面属性 init_opts=opts.InitOpts( width='1700px', height='750px', page_title='全国各省市平均房价', )) .add_schema(maptype="china") .add_coordinate('保亭', 109.70259, 18.63905) .add_coordinate('乐东', 109.17361, 18.74986) .add_coordinate('陵水', 110.0372, 18.50596) 维护更新 尝试利用pyecharts实现legend的点击事件,实现页面跳转。还有,就是上传部分api文档了吧,大家也可以自行收集。好了,这次先更新到这了,如果你看到了这里那你一定很优秀,(づ ̄ 3 ̄)づ 4月24日更新: requests模块api文档已经上传。第一个文件中添加了睡眠时间,使爬虫不易被检测到,更稳定,但是爬取时间更长。第一个文件中修改了每个页面总的li类选择器。 如下所示,原本爬取的是ul.resblock-list-wrapper li.resblock-list.post_ulog_exposure_scroll.has_result 但是部分页面,例如北京的18,19,20这些页面,他们的li是没有.has_result这部分的,所以将.has_result部分去掉,达到了获取全部北京页面房产信息的目的。 # 每一个城市房产列表 所有的li 修改前 building_tagList = getTag(html,'ul.resblock-list-wrapper li.resblock-list.post_ulog_exposure_scroll.has_result') # 每一个城市房产列表 所有的li 修改后 building_tagList = getTag(html,'ul.resblock-list-wrapper li.resblock-list.post_ulog_exposure_scroll') 第一个文件中修改了向csv文件中写入内容的指定字符集。 不同系统中写入csv的数据,会产生字符集问题。 with open() as f: 以这种方式向csv文件中写入数据时,会采用系统默认的字符集。我们可以通过open()函数的encoding属性来指定字符集。 with open(fname, 'a',newline='',encoding='utf-8') as f: csvFile = csv.writer(f) if flag: csvFile.writerow(title) flag = False csvFile.writerows(b_info_list) # 写多行 也就是二维数组的时候用writerows() 一维数组用writerow() print('数据写入完成!') MAC OS系统默认字符集为utf-8。Windows 系统默认字符集为GBK。(由于我们使用的都是中文版的Windows,所以才使用了GBK字符集。)
|





【本文地址】
今日新闻 |
推荐新闻 |