使用决策树模型,来构建客户违约预测模型 |
您所在的位置:网站首页 › 债券分析模型 › 使用决策树模型,来构建客户违约预测模型 |
使用决策树模型,来构建客户违约预测模型
|
实验:使用决策树模型,来构建客户违约预测模型
决策树(Decision Tree)分类技术是一种比较直观的用来分析不确定性事件的概率模型,属于数据挖掘技术中比较常见的一种方法。主要是用在分析和评价项目预期的风险和可行性的问题。决策树作为预测模型,从直观可以看作类似于一棵树,从树根到各个分支都可以看作一个如何分类的问题。枝干上的每一片树叶代表了具有分类功能的样本数据的分割。本次的实验将构建决策树模型来对客户是否违约进行预测分析。 此次实验的步骤如下: 1、导入实验相关的库: #基础数据准备 import pandas as pd import numpy as np ##可视化 import matplotlib.pyplot as plt %matplotlib inline import seaborn as sns from pylab import mpl mpl.rcParams['font.sans-serif'] = ['SimHei'] mpl.rcParams['axes.unicode_minus'] =False ## 根据卡方检验选取关联特征 from sklearn.feature_selection import SelectKBest from sklearn.feature_selection import chi2 from sklearn.metrics import * # 导入决策树分类模型 from sklearn.tree import DecisionTreeClassifier2、数据导入 data = pd.read_excel(r'客户信息及违约表现.xlsx')展示数据的前五条数据 data.head(5)output:
从上面的数据查看中我们可以发现收入最小是1.0*exp(5) ,最大是6.602542exp(6),我的想法是可以将其分成10个收入范围,每个范围分别用0,1,2,3,。。。。9来表示(也可以分为更多的类) income_max = max(data["收入"]) income_min = min(data["收入"]) a = round((income_max-income_min)*0.1,2) #定义一个给收入编码的函数getcode(x) def getcode(x): if x>=income_min and x=income_min+a*1 and x=income_min+a*2 and x=income_min+a*3 and x=income_min+a*4 and x=income_min+a*5 and x=income_min+a*6 and x=income_min+a*7 and x=income_min+a*8 and x=income_min+a*9 and xcredit_min and xcredit_min+credit_one*1 and xcredit_min+credit_one*2 and xcredit_min+credit_one*3 and xcredit_min+credit_one*4 and xcredit_min+credit_one*5 and xcredit_min+credit_one*6 and xcredit_min+credit_one*7 and xcredit_min+credit_one*8 and xcredit_min+credit_one*9 and x |
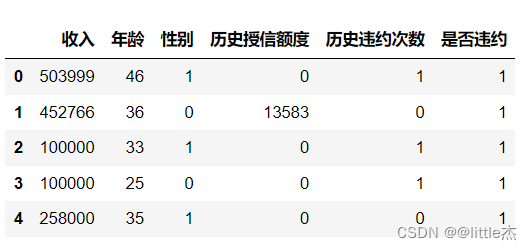 3、数据导入之后查看数据的情况(看是否是有缺失值,异常值)
3、数据导入之后查看数据的情况(看是否是有缺失值,异常值)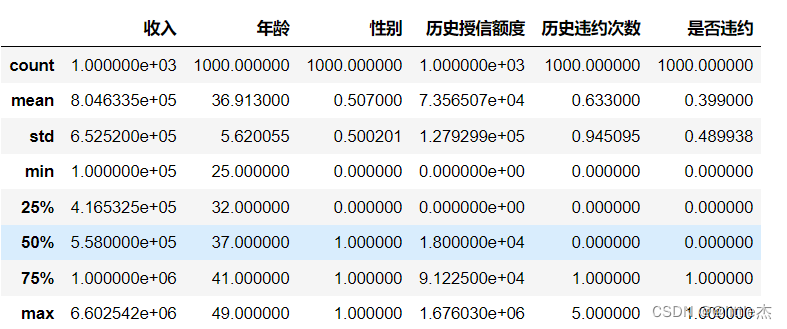
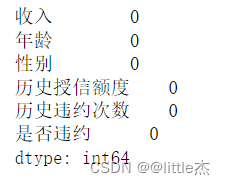 可以发现数据是没有缺失值的 4、特征工程:对收入数据和历史授信额度进行处理以及编码 首先对收入那一列的数据进行整理编码
可以发现数据是没有缺失值的 4、特征工程:对收入数据和历史授信额度进行处理以及编码 首先对收入那一列的数据进行整理编码
【本文地址】
今日新闻 |
推荐新闻 |