Pytorch实现戴口罩人脸检测和戴口罩识别(含训练代码 戴口罩人脸数据集) |
您所在的位置:网站首页 › 佩戴口罩的正确方法图片视频教程 › Pytorch实现戴口罩人脸检测和戴口罩识别(含训练代码 戴口罩人脸数据集) |
Pytorch实现戴口罩人脸检测和戴口罩识别(含训练代码 戴口罩人脸数据集)
|
Pytorch实现戴口罩人脸检测和戴口罩识别(含训练代码 戴口罩人脸数据集)
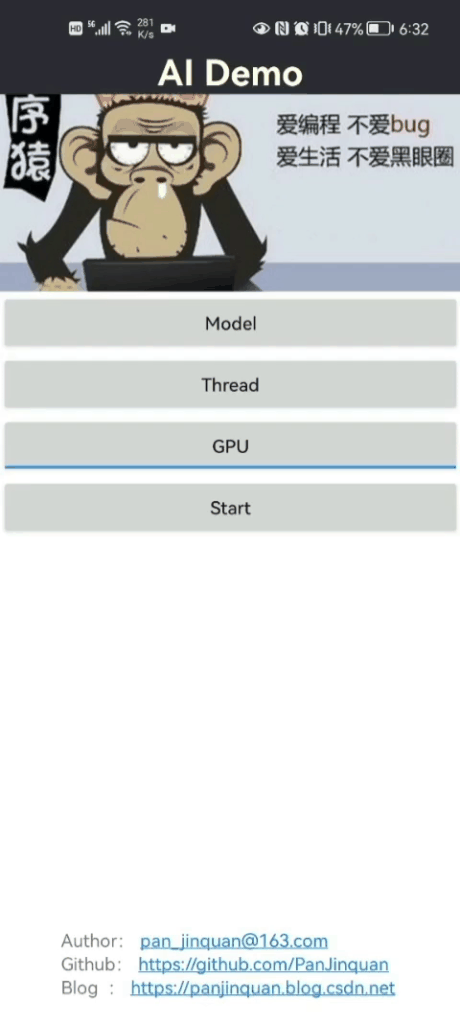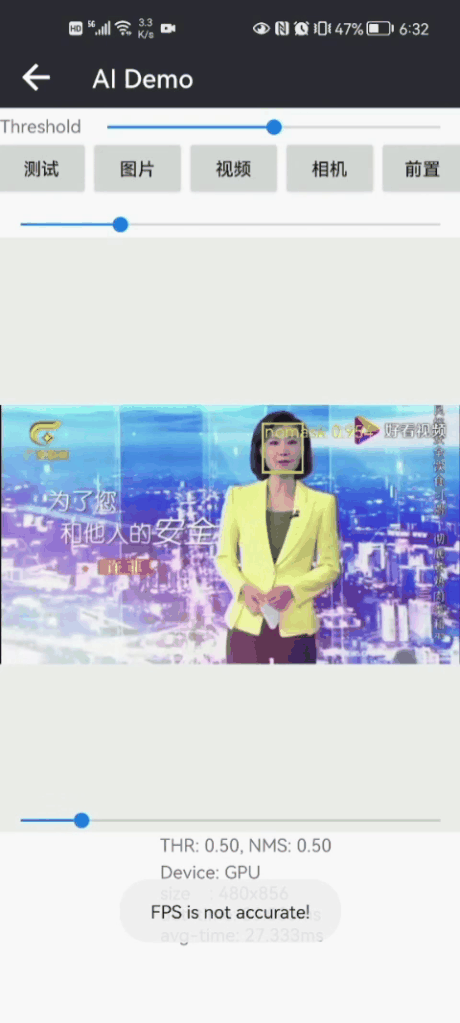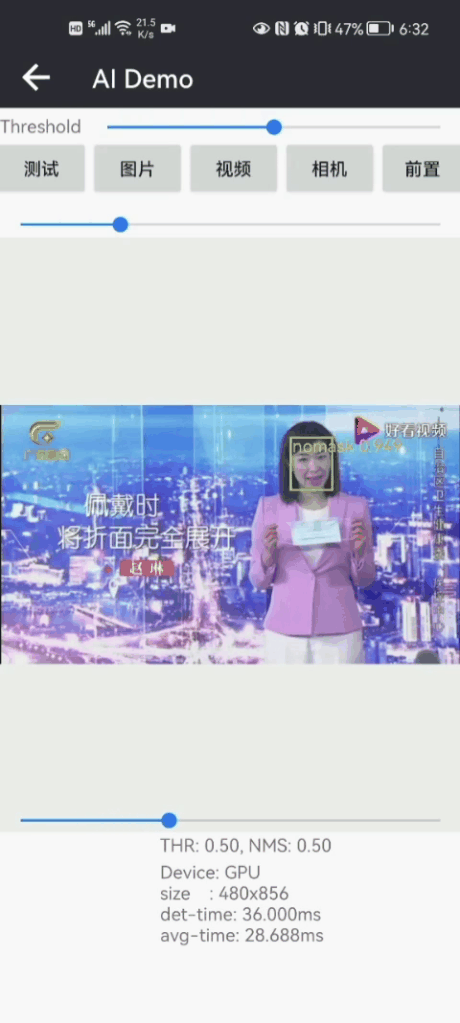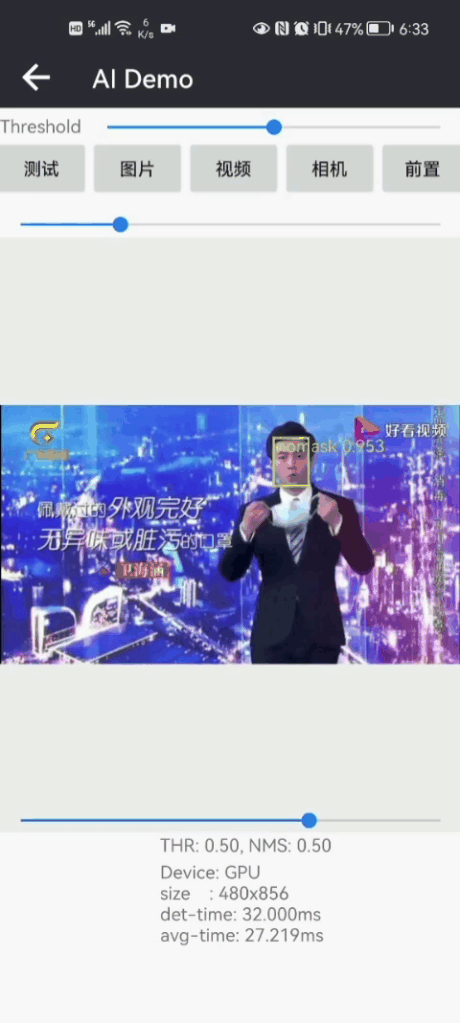
目录 Pytorch实现戴口罩人脸检测和戴口罩识别(含训练代码 戴口罩人脸数据集) 1.戴口罩识别的方法 (1)基于多类别目标检测的戴口罩识别方法 (2)基于人脸检测+戴口罩分类识别方法 2.戴口罩人脸数据集 3.戴口罩人脸检测 4.戴口罩识别模型训练 (0)项目安装 (1)准备数据 (2)戴口罩分类模型训练(Pytorch) (3) 可视化训练过程 (4) 戴口罩识别效果 (5) 一些运行错误处理方法 5.项目源码下载(Python版) 6.项目源码下载(Android版) 当前疫情反反复复,而防控新冠病毒的最有效手段之一就是戴口罩,因此研究戴口罩检测和识别具有重大意义。疫情防控,人人有责,作为一名程序狗,分享一下鄙人开发的戴口罩人脸检测和戴口罩识别方法。项目开发基于深度学习框架Pytorch开发一套的戴口罩识别(face-mask recognition)识别系统,目前准确率还挺高的,在resnet50,可以高达99%的准确率,即使采用轻量化版本MobileNet-v2,准确率也可以高达98.18%左右。 【尊重原创,转载请注明出处】https://blog.csdn.net/guyuealian/article/details/125428609 先展示一下,Python版本的戴口罩人脸检测和戴口罩识别Demo效果:  
戴口罩人脸检测和戴口罩识别整套Python代码下载: Pytorch实现戴口罩人脸检测和戴口罩识别(含训练代码 戴口罩人脸数据集) 整套项目项,支持的主要内容主要有: 提供5个戴口罩人脸数据集: facemask-train1, facemask-train2,facemask-train3, synthetic-train1,synthetic-train2 ,facemask-test ,总共约有50000+的数据:提供生成戴口罩人脸代码: python create_facemask.py提供戴口罩分类识别训练代码:train.py提供戴口罩分类识别测试代码:demo.pydemo支持戴口罩人脸检测,支持戴口罩识别:mask(戴口罩)和nomask(未佩戴口罩)提供戴口罩识别Python Demo源码,在普通电脑CPU/GPU上可以实时检测和识别如果你需要Android版本的戴口罩人脸检测和戴口罩识别,请参考《Android实现戴口罩人脸检测和戴口罩识别(附Android源码)》https://panjinquan.blog.csdn.net/article/details/128404379 1.戴口罩识别的方法 (1)基于多类别目标检测的戴口罩识别方法基于多类别目标检测的戴口罩识别方法,一步到位,把未戴口罩(nomask)和戴口罩(mask)两个类别直接当成两个目标检测的类别进行训练 优点:直接端到端训练,任务简单,速度快缺点:需要人工标注人脸框mask和nomask,时间花费比较大;训练数据不足的情况下,容易出现误检测的情况 (2)基于人脸检测+戴口罩分类识别方法该方法,先采用通用的人脸检测模型,进行人脸检测,然后裁剪人脸区域,再训练一个戴口罩分类器,对人脸进行分类识别(未戴口罩和戴口罩) 优点:不需要标注人脸框数据,可以自己合成戴口罩人脸数据,人工成本低;精度高,可针对分类模型进行轻量化缺点:需要部署两个模型(人脸检测模型和戴口罩分类模型),人脸越多,速度越慢考虑到数据标注成本的问题,本项目采用第二种方法,即采用基于人脸检测+戴口罩分类识别方法 2.戴口罩人脸数据集网上绝大部分人脸数据都是不戴口罩的人脸,不能直接用于戴口罩识别中。鉴于此,我们可以考虑自己合成/生成戴口罩的人脸数据,以下是鄙人收藏和整理的戴口罩人脸数据集和合成的数据集,总共约有50000+的数据: 原始图片生成戴口罩人脸
关于戴口罩人脸数据和生成方法,详细使用说明请参考我的一篇博客《戴口罩人脸数据集和戴口罩人脸生成方法》 数据集说明facemask-train1 从网上收集的戴口罩人脸数据集(如virus-mask-dataset),约7000+张图片,并清洗了部分标注错误的样本每张图片都被标注了mask(戴口罩)和nomask(未佩戴口罩)的检测框标注格式为标准的VOC xml格式,可用于人脸检测训练数据使用已经裁剪了人脸区域,并清洗了部分标注错误的样本;其中mask(戴口罩)人脸有3000+张,nomask(未佩戴口罩)人脸有10000+张,可作为分类训练数据集,facemask-train2 从网上收集的戴口罩人脸数据集,约3500+张图片,每张图片都被标注了mask(戴口罩)和nomask(未佩戴口罩)的检测框标注格式为标准的VOC格式,但标注的人脸框比较大,不建议用于人脸检测训练数据使用已经裁剪了人脸区域图像,并清洗了部分标注错误的样本;其中mask(戴口罩)人脸有2000+张,nomask(未佩戴口罩)人脸有6000+张,可作为分类训练数据集facemask-train3 从网上收集的戴口罩人脸数据集,其中mask(戴口罩)人脸有600+张,nomask(未佩戴口罩)人脸有1700+张,可作为分类训练数据集原始图片都被裁剪为人脸图像了,所以不合适用于人脸检测;可作为分类训练数据集synthetic-train1 这是合成的戴口罩人脸数据其中mask(戴口罩)人脸有7000+张,nomask(未佩戴口罩)人脸有7000+张,可作为分类训练数据集synthetic-train2 这是合成的戴口罩人脸数据其中mask(戴口罩)人脸有6000+张,nomask(未佩戴口罩)人脸有6000+张,可作为分类训练数据集facemask-test 这是戴口罩人脸测试集其中mask(戴口罩)人脸有300+张,nomask(未佩戴口罩)人脸有300+张,用于分类模型测试 3.戴口罩人脸检测通常我们理解的人脸检测是指没有遮挡或者只有少许遮挡情况下的人脸检测,当人脸戴有口罩,其检测效果势必会变得比较差,而大量标注带有人脸口罩的人脸数据集还是比较耗时费力的。所以我的方法是: 先在WiderFace人脸数据集上,训练人脸检测;然后在facemask-train1数据集finetune人脸检测模型,经过这个方法训练后,其戴口罩检测效果会好很多。 当然,即使使用开源的人脸检测算法,在带有口罩人脸检测,其实效果也不会太差,比如使用FaceBox,MTCNN检测带有口罩的图片,效果也可以的,只不过会经常出现人脸检测框不完整,存在缺少等问题,对后续的戴口罩的识别有一定的影响。 关于人脸检测的方法,可以参考我的另一篇博客:《行人检测和人脸检测和人脸关键点检测(C++/Android源码)》
有了戴口罩人脸检测,接下来就可以开始训练戴口罩分类识别模型;考虑到后续我们需要将戴口罩识别模型部署到Android平台中,因此项目选择计算量比较小的轻量化模型(mobilenet_v2) (0)项目安装整套工程项目基本结构如下: . ├── classifier # 训练模型相关工具 ├── configs # 训练配置文件 ├── data # 训练数据 ├── libs │ ├── convert # 将模型转换为ONNX工具 │ ├── facemask # 戴口罩人脸数据生成工具 │ ├── light_detector # 人脸检测 │ ├── create_facemask.py # 戴口罩人脸数据生成demo │ ├── detector.py # 人脸检测demo │ └── README.md ├── demo.py # 戴口罩人脸识别demo ├── README.md # 项目工程说明文档 ├── requirements.txt # 项目相关依赖包 └── train.py # 训练文件项目依赖python包请参考requirements.txt,使用pip安装即可: numpy==1.16.3 matplotlib==3.1.0 Pillow==6.0.0 easydict==1.9 opencv-contrib-python==4.5.2.52 opencv-python==4.5.1.48 pandas==1.1.5 PyYAML==5.3.1 scikit-image==0.17.2 scikit-learn==0.24.0 scipy==1.5.4 seaborn==0.11.2 tensorboard==2.5.0 tensorboardX==2.1 torch==1.7.1+cu110 torchvision==0.8.2+cu110 tqdm==4.55.1 xmltodict==0.12.0 basetrainer pybaseutils==0.6.5项目安装教程请参考(初学者入门,麻烦先看完下面教程,配置好开发环境): 项目开发使用教程和常见问题和解决方法视频教程:1 手把手教你安装CUDA和cuDNN(1)视频教程:2 手把手教你安装CUDA和cuDNN(2)视频教程:3 如何用Anaconda创建pycharm环境视频教程:4 如何在pycharm中使用Anaconda创建的python环境 (1)准备数据总共有5个数据集,包括 facemask-train1, facemask-train2,facemask-train3,synthetic-train1,synthetic-train2 ,facemask-test ,总共约有50000+的数据。
当然,你也可以使用自己的数据集,数据结构如下,其中mask目录存放戴口罩的人脸图片,而nomask目录存放未戴口罩的人脸图像。
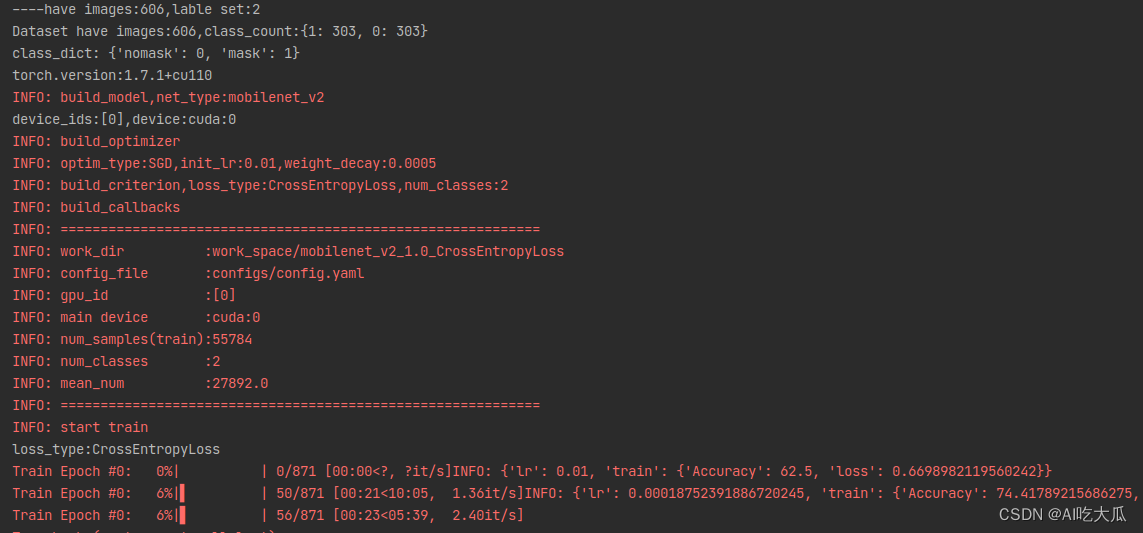
鄙人在《Pytorch基础训练库Pytorch-Base-Trainer(支持模型剪枝 分布式训练)》基础上实现了戴口罩和未佩戴口罩二分类识别训练和测试,整套训练代码非常简单操作,用户只需要将相同类别的数据放在同一个目录下,并填写好对应的数据路径,即可开始训练了。 训练框架采用Pytorch,整套训练代码支持的内容主要有: 目前支持的backbone有:googlenet,resnet[18,34,50], ,mobilenet_v2等, 其他backbone可以自定义添加训练参数可以通过(configs/config.yaml)配置文件进行设置训练参数说明如下: 注意数据路径分隔符使用【/】,不是【\】项目不要出现含有中文字符的目录文件或路径,否则会出现很多异常! # 设置训练数据集,支持多个训练数据集 train_data: - 'dataset/face_mask/facemask-train1/crops' - 'dataset/face_mask/facemask-train2/crops' - 'dataset/face_mask/facemask-train3/crops' - 'dataset/face_mask/synthetic-train1/crops' - 'dataset/face_mask/synthetic-train1/crops' # 设置测试数据集 test_data: 'dataset/face_mask/facemask-test/crops' class_name: 'dataset/face_mask/class_name.txt' # 类别标签 train_transform: "train" # 训练使用的数据增强方法 test_transform: "val" # 测试使用的数据增强方法 work_dir: "work_space/" # 保存输出模型的目录 net_type: "mobilenet_v2" # 骨干网络,支持:resnet18,mobilenet_v2,googlenet resample: True # 进行样本均衡 width_mult: 1.0 input_size: [ 128,128 ] rgb_mean: [ 0.5, 0.5, 0.5 ] # for normalize inputs to [-1, 1],Sequence of means for each channel. rgb_std: [ 0.5, 0.5, 0.5 ] # for normalize,Sequence of standard deviations for each channel. batch_size: 64 lr: 0.01 # 初始学习率 optim_type: "SGD" # 选择优化器,SGD,Adam loss_type: "LabelSmoothing" # 选择损失函数:支持CrossEntropyLoss,LabelSmoothing momentum: 0.9 # SGD momentum num_epochs: 100 # 训练循环次数 num_warn_up: 3 # warn-up次数 num_workers: 8 # 加载数据工作进程数 weight_decay: 0.0005 # weight_decay,默认5e-4 scheduler: "multi-step" # 学习率调整策略 milestones: [ 20,50,80 ] # 下调学习率方式 gpu_id: [ 0 ] # GPU ID log_freq: 50 # LOG打印频率 progress: True # 是否显示进度条 pretrained: False # 是否使用pretrained模型 finetune: False # 是否进行finetune开始训练: python train.py -c configs/config.yaml
训练完成后,训练集的Accuracy在99%以上,测试集的Accuracy在98%左右 (3) 可视化训练过程 训练过程可视化工具是使用Tensorboard,使用方法,在终端输入: # 基本方法 tensorboard --logdir=path/to/log/ # 例如 tensorboard --logdir=work_space/mobilenet_v2_1.0_CrossEntropyLoss/log可视化效果  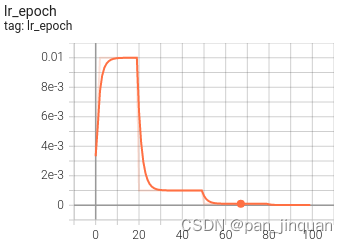  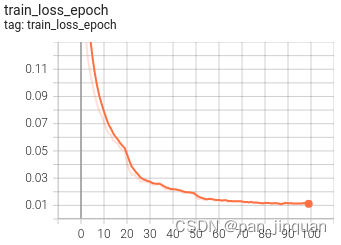  
(4) 戴口罩识别效果
测试图片文件
# 测试图片(Linux系统)
image_dir='data/test_image' # 测试图片的目录
model_file="data/pretrained/mobilenet_v2_1.0_CrossEntropyLoss/model/best_model_078_98.3498.pth" # 模型文件
out_dir="output/" # 保存检测结果
python demo.py --image_dir $image_dir --model_file $model_file --out_dir $out_dir
(4) 戴口罩识别效果
测试图片文件
# 测试图片(Linux系统)
image_dir='data/test_image' # 测试图片的目录
model_file="data/pretrained/mobilenet_v2_1.0_CrossEntropyLoss/model/best_model_078_98.3498.pth" # 模型文件
out_dir="output/" # 保存检测结果
python demo.py --image_dir $image_dir --model_file $model_file --out_dir $out_dir
Windows系统,请将$image_dir, $model_file,$out_dir等变量代替为对应的变量值即可,如 # 测试图片(Windows系统) python demo.py --image_dir 'data/test_image' --model_file "data/pretrained/mobilenet_v2_1.0_CrossEntropyLoss/model/best_model_078_98.3498.pth" --out_dir "output/" 测试视频文件 # 测试视频文件(Linux系统) video_file="data/video.mp4" # 测试视频文件,如*.mp4,*.avi等 model_file="data/pretrained/mobilenet_v2_1.0_CrossEntropyLoss/model/best_model_078_98.3498.pth" # 模型文件 out_dir="output/" # 保存检测结果 python demo.py --video_file $video_file --model_file $model_file --out_dir $out_dir # 测试视频文件(Windows系统) python demo.py --video_file data/video.mp4 --model_file data/pretrained/mobilenet_v2_1.0_CrossEntropyLoss/model/best_model_078_98.3498.pth --out_dir output/ 测试摄像头 # 测试摄像头(Linux系统) video_file=0 # 测试摄像头ID model_file="data/pretrained/mobilenet_v2_1.0_CrossEntropyLoss/model/best_model_078_98.3498.pth" # 模型文件 out_dir="output/" # 保存检测结果 python demo.py --video_file $video_file --model_file $model_file --out_dir $out_dir # 测试摄像头(Windows系统) python demo.py --video_file 0 --model_file data/pretrained/mobilenet_v2_1.0_CrossEntropyLoss/model/best_model_078_98.3498.pth --out_dir output/       (5) 一些运行错误处理方法
(5) 一些运行错误处理方法
项目不要出现含有中文字符的目录文件或路径,否则会出现很多异常!!!!!!!! cannot import name 'load_state_dict_from_url' 由于一些版本升级,会导致部分接口函数不能使用,请确保版本对应 torch==1.7.1 torchvision==0.8.2 或者将对应python文件将 from torchvision.models.resnet import model_urls, load_state_dict_from_url修改为: from torch.hub import load_state_dict_from_url model_urls = { 'mobilenet_v2': 'https://download.pytorch.org/models/mobilenet_v2-b0353104.pth', 'resnet18': 'https://download.pytorch.org/models/resnet18-5c106cde.pth', 'resnet34': 'https://download.pytorch.org/models/resnet34-333f7ec4.pth', 'resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth', 'resnet101': 'https://download.pytorch.org/models/resnet101-5d3b4d8f.pth', 'resnet152': 'https://download.pytorch.org/models/resnet152-b121ed2d.pth', 'resnext50_32x4d': 'https://download.pytorch.org/models/resnext50_32x4d-7cdf4587.pth', 'resnext101_32x8d': 'https://download.pytorch.org/models/resnext101_32x8d-8ba56ff5.pth', 'wide_resnet50_2': 'https://download.pytorch.org/models/wide_resnet50_2-95faca4d.pth', 'wide_resnet101_2': 'https://download.pytorch.org/models/wide_resnet101_2-32ee1156.pth', } 5.项目源码下载(Python版)整套项目源码内容包含:Pytorch实现戴口罩人脸检测和戴口罩识别(含训练代码 戴口罩人脸数据集) 提供5个戴口罩人脸数据集: facemask-train1, facemask-train2,facemask-train3, synthetic-train1,synthetic-train2 ,facemask-test ,总共约有50000+的数据:提供生成戴口罩人脸代码: python create_facemask.py提供戴口罩分类识别训练代码:train.py提供戴口罩分类识别测试代码:demo.pydemo支持戴口罩人脸检测,支持戴口罩识别:mask(戴口罩)和nomask(未佩戴口罩)提供戴口罩识别Python Demo源码,在普通电脑CPU/GPU上可以实时检测和识别 6.项目源码下载(Android版)目前已经实现Android版本的戴口罩人脸检测和戴口罩识别,详细项目请参考《Android实现戴口罩人脸检测和戴口罩识别(附Android源码)》https://panjinquan.blog.csdn.net/article/details/128404379 戴口罩人脸检测和戴口罩识别Android Demo APP体检:https://pan.baidu.com/s/1meGv_J6xZiDvXzvXBzNnHA 提取码: 73e5 或者戴口罩人脸检测和戴口罩识别AndroidDemoAPP-Android文档类资源-CSDN下载
|



【本文地址】
今日新闻 |
推荐新闻 |