YOLOv8改进:Gold |
您所在的位置:网站首页 › 作者:薄荷小怪兽 › YOLOv8改进:Gold |
YOLOv8改进:Gold
|
💡💡💡本文独家改进:提出了全新的信息聚集-分发(Gather-and-Distribute Mechanism)GD机制,Gold-YOLO,替换yolov8 head部分 实现暴力涨点 Gold-YOLO | 亲测在多个数据集能够实现大幅涨点 💡💡💡Yolov8魔术师,独家首发创新(原创),适用于Yolov5、Yolov7、Yolov8等各个Yolo系列,专栏文章提供每一步步骤和源码,轻松带你上手魔改网络 💡💡💡重点:通过本专栏的阅读,后续你也可以自己魔改网络,在网络不同位置(Backbone、head、detect、loss等)进行魔改,实现创新!!! 专栏介绍: https://blog.csdn.net/m0_63774211/category_12289773.html ✨✨✨原创魔改网络、复现前沿论文,组合优化创新 🚀🚀🚀小目标、遮挡物、难样本性能提升 🍉🍉🍉持续更新中,定期更新不同数据集涨点情况 1.Gold-YOLO 链接:https://arxiv.org/pdf/2309.11331.pdf 代码:https://github.com/huawei-noah/Efficient-Computing/tree/master/Detection/Gold-YOLO 单位:华为诺亚方舟实验室 理论部分可参考:超越YOLO系列!华为提出Gold-YOLO:高效实时目标检测器 - 知乎 传统YOLO的问题 在检测模型中,通常先经过backbone提取得到一系列不同层级的特征,FPN利用了backbone的这一特点,构建了相应的融合结构:不层级的特征包含着不同大小物体的位置信息,虽然这些特征包含的信息不同,但这些特征在相互融合后能够互相弥补彼此缺失的信息,增强每一层级信息的丰富程度,提升网络性能。 原始的FPN结构由于其层层递进的信息融合模式,使得相邻层的信息能够充分融合,但也导致了跨层信息融合存在问题:当跨层的信息进行交互融合时,由于没有直连的交互通路,只能依靠中间层充当“中介”进行融合,导致了一定的信息损失。之前的许多工作中都关注到了这一问题,而解决方案通常是通过添加shortcut增加更多的路径,以增强信息流动。 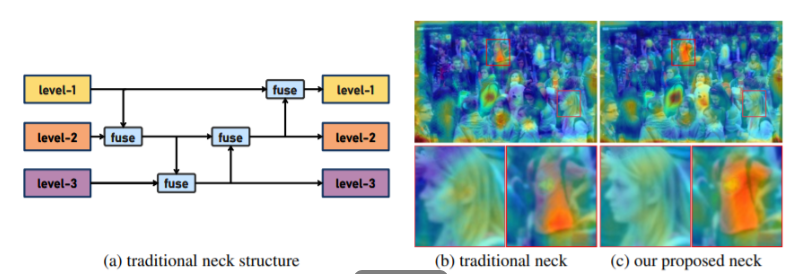 摘要:当前YOLO系列模型通常采用类FPN方法进行信息融合,而这一结构在融合跨层信息时存在信息损失的问题。针对这一问题,我们提出了全新的信息聚集-分发(Gather-and-Distribute Mechanism)GD机制,通过在全局视野上对不同层级的特征进行统一的聚集融合并分发注入到不同层级中,构建更加充分高效的信息交互融合机制,并基于GD机制构建了Gold-YOLO。在COCO数据集中,我们的Gold-YOLO超越了现有的YOLO系列,实现了精度-速度曲线上的SOTA。 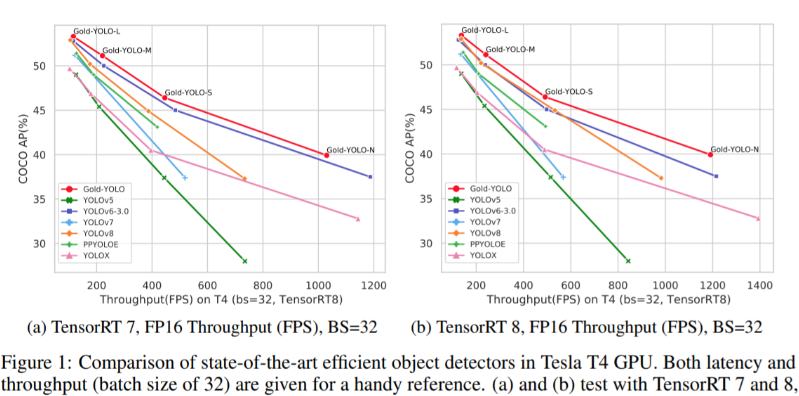 提出了一种全新的信息交互融合机制:信息聚集-分发机制(Gather-and-Distribute Mechanism)。该机制通过在全局上融合不同层次的特征得到全局信息,并将全局信息注入到不同层级的特征中,实现了高效的信息交互和融合。在不显著增加延迟的情况下GD机制显著增强了Neck部分的信息融合能力,提高了模型对不同大小物体的检测能力。 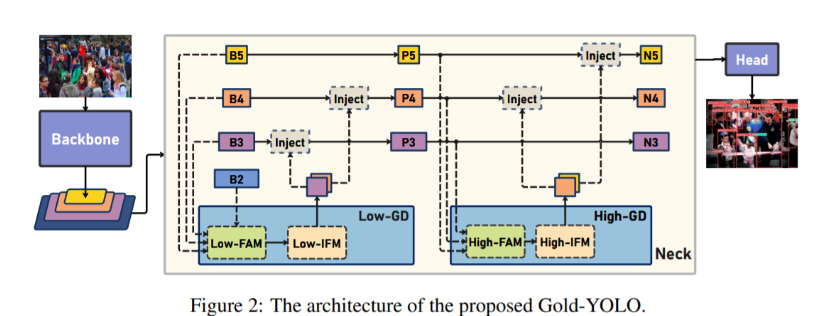 在Gold-YOLO中,针对模型需要检测不同大小的物体的需要,并权衡精度和速度,我们构建了两个GD分支对信息进行融合:低层级信息聚集-分发分支(Low-GD)和高层级信息聚集-分发分支(High-GD),分别基于卷积和transformer提取和融合特征信息。 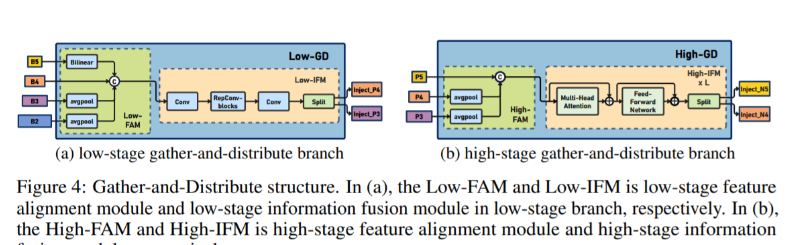 实验结果: 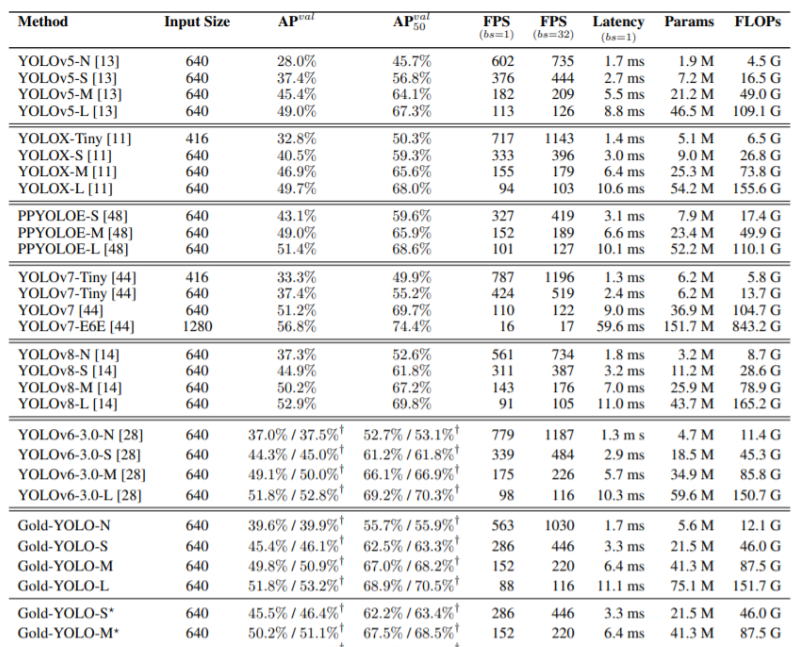 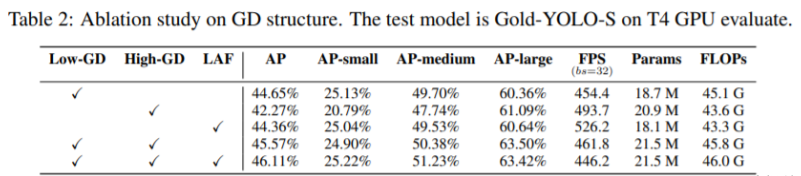 2.gold-yolo引入到yolov82.1新建 gold-yolo加入ultralytics/nn/head/goldyolo.py 2.gold-yolo引入到yolov82.1新建 gold-yolo加入ultralytics/nn/head/goldyolo.py核心代码: ###################### gold-yolo #### STRAT by AI&CV ############################### #gold-yolo Gather-and-Distribute Mechanism class top_Block(nn.Module): def __init__(self, dim, key_dim, num_heads, mlp_ratio=4., attn_ratio=2., drop=0., drop_path=0.): super().__init__() self.dim = dim self.num_heads = num_heads self.mlp_ratio = mlp_ratio self.attn = Attention(dim, key_dim=key_dim, num_heads=num_heads, attn_ratio=attn_ratio) # NOTE: drop path for stochastic depth, we shall see if this is better than dropout here self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity() mlp_hidden_dim = int(dim * mlp_ratio) self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, drop=drop) def forward(self, x1): x1 = x1 + self.drop_path(self.attn(x1)) x1 = x1 + self.drop_path(self.mlp(x1)) return x1 class TopBasicLayer(nn.Module): def __init__(self, embedding_dim, ouc_list, block_num=2, key_dim=8, num_heads=4, mlp_ratio=4., attn_ratio=2., drop=0., attn_drop=0., drop_path=0.): super().__init__() self.block_num = block_num self.transformer_blocks = nn.ModuleList() for i in range(self.block_num): self.transformer_blocks.append(top_Block( embedding_dim, key_dim=key_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, attn_ratio=attn_ratio, drop=drop, drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path)) self.conv = nn.Conv2d(embedding_dim, sum(ouc_list), 1) def forward(self, x): # token * N for i in range(self.block_num): x = self.transformer_blocks[i](x) return self.conv(x) class AdvPoolFusion(nn.Module): def forward(self, x): x1, x2 = x if torch.onnx.is_in_onnx_export(): self.pool = onnx_AdaptiveAvgPool2d else: self.pool = nn.functional.adaptive_avg_pool2d N, C, H, W = x2.shape output_size = np.array([H, W]) x1 = self.pool(x1, output_size) return torch.cat([x1, x2], 1) ###################### gold-yolo #### END by AI&CV ###############################源码详见:https://cv2023.blog.csdn.net/article/details/133271100 2023腾讯技术创作特训营第二期有奖征文,瓜分万元奖池和键盘手表 |
【本文地址】