信息检索系列 |
您所在的位置:网站首页 › 余弦相似度计算公式及例子 › 信息检索系列 |
信息检索系列
|
首先,大致梳理以下余弦相似度方法和IF-IDF方法的原理 1、余弦相似度计算文档相似度 余弦相似度方法的原理公式其实与我们高中的时候所学到的余弦公式相似 在计算两个文档的余弦相似度时,首先对两个文档分别构建成词汇向量,词汇向量可以理解成一个文档中所有词汇串成一条线然后构成一个向量,而每个词汇就是一个维度,词汇的频率时维度系数 公式中的分子部分,表示两个向量的点乘,其实就是对应维度相乘积(相当于x1*x2 y1*y2)因为向量中每个词汇都理解成每一个维度,因此两个文档中若是出现相同词汇,则将文档一中该词汇的频率*文档二的词汇频率,将两个文档中全部的词汇进行相同处理,可以得到分子部分。 公式中的分目部分,表示的是各自向量的摸,每个词汇都是一个维度,每个维度的系数是词汇本身。三维中求一个空间向量的模,是对xyz进行平方和的开方,因此词汇向量的模可以进行各自维度系数的平方、取和、开方。从而获得分母部分。 分母和分子的获得即可得到两个文档的余弦相关度。 2、IF-IDF方法 IF-IDF拆分为IF和IDF,IF-IDF与余弦相似度不同的是,余弦相似度只考虑到了词汇的频率IF对文档相关度的影响,但是有些情况下,越为稀少的词往往更能代表一个文档的信息,因此计算文档相似度时,稀少的词汇也应该作为一个判断标准,即IDF。 那么如何判断一个词汇稀少呢,IF-IDF中使用文档在用出现该出现某词汇的文档数占总文档数的比例进行判断,但是文档数的增加与稀少程度并不存在正比例关系,因此IF-IDF使用log对两者进行关联,IDF可以表示为log(N/(N1+1))N表示文档总数,N1表示含某一词汇的文档数。 由此,构建一个词汇向量时,一个词汇对应维度的系数不再是频率本身,而是频率*IDF 接着,再使用余弦相似度方法对两文档进行相关度的计算,即可求得。 下面是代码部分和测试结果: (1)因为要记录词汇在全部文档的出现情况,因此构建一个倒排索引 该倒排索引并非按照term进行所以,而是采用文档id进行索引,因为更便于后续逐个文档间的计算
(2)余弦相似度方法函数 Upnum表示分子上的数、downnum1和downnum2分别表示分母原始值先寻找两个文档中相同的term,计算frency的乘积再分别计算各文档的自身的frency的平方
(3)IF-IDF方法函数
(4)MAX函数,寻找最大相关度
(5)测试结果(IF-IDF)
|
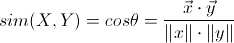







【本文地址】