【2024最全最细LangChain教程 |
您所在的位置:网站首页 › 体智能主要教什么 › 【2024最全最细LangChain教程 |
【2024最全最细LangChain教程
|
【2024最全最细Langchain教程-11】Langchain回调模块-CSDN博客 本节课B站视频:【2024最全最细】Langchain教程之Agent(一)_哔哩哔哩_bilibili 有很多教程把Agent称为“代理”,我觉得这个翻译太没意思了,一来和Proxy很容易混淆,二来一点都不酷。 之所以把Agent翻译成智能体,是因为Agent可以(在LLM推理分析的帮助下)可以自己识别、选择和使用工具,这个就是智能体的表现。人之所以能走上进化的道路,一来是发明了语言,二来是学会了使用工具。就这两点来看,把目前的Agent称为智能体一点也不为过。 我们来构造一个简单的Agent,以此了解Agent的原理和基本实现方法: 目录 1. 构造一个网络搜索工具、一个网页检索器工具 2. 开始构造一个简单的、无记忆的Agent 1. 构造一个网络搜索工具、一个网页检索器工具我们先去Tavily 这个网站进行注册,会给你一个试用账号,然后你要把他给你的那个key配置到系统环境里:
这个API接口每个月有1000次免费的查询机会,我们做研究和学习足够了: from langchain_community.tools.tavily_search import TavilySearchResults search = TavilySearchResults( max_results = 1, verbose = True, ) search.invoke("今天中国A股的表现如何,沪指和深指分别是多少?")有一个问题好像是我设置的max_result 和 verbose好像没有生效,给我的结果依然是两条查询结果,不知道为啥,verbose也没有生效,我没搞懂。不过没关系,我们先来看一下查询结果:
然后我们来构造一个检索器Retriever: import os from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain_community.document_loaders import WebBaseLoader from langchain_community.vectorstores import Chroma from langchain_openai import OpenAIEmbeddings loader = WebBaseLoader("https://docs.smith.langchain.com/overview") docs = loader.load() documents = RecursiveCharacterTextSplitter( chunk_size=1000, chunk_overlap=200 ).split_documents(docs) vector = Chroma.from_documents( documents, OpenAIEmbeddings( openai_api_key = os.getenv("OPENAI_API_KEY"), base_url = os.getenv("OPENAI_BASE_URL") ) ) retriever = vector.as_retriever() retriever.get_relevant_documents("how to upload a dataset")[0]这个retriever的作用,和我们之前写的一个案例类似,不熟悉的可以回过头去看看:【2024最全最细Lanchain教程-9】Langchain互联网查询-CSDN博客 这里调用的加载器是 WebBaseLoader,可以在官网API库里找到这个loader的介绍:langchain_community.document_loaders.web_base.WebBaseLoader — 🦜🔗 LangChain 0.1.4
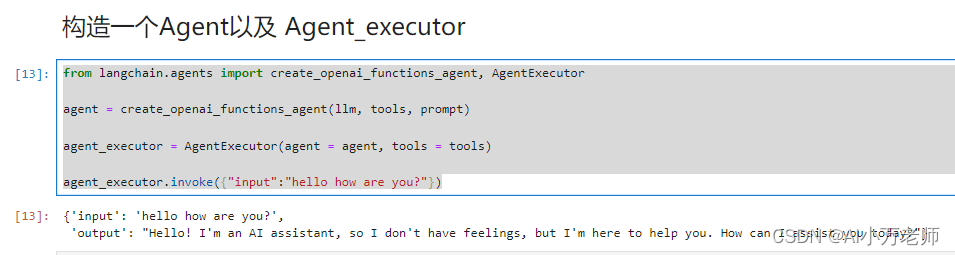
可以看到,和我们之前的案例一样,也是用BeautifulSoup来进行内容提取的,只不过他的这个源码写的结构更清晰、对于异常的处理也更完善,时间足够的话值得去仔细研究一下。 这个构造完了之后,需要把检索器工具再进行一下包装以供Agent调用,使用的是 create_retriever_tool 方法: from langchain.tools.retriever import create_retriever_tool retriever_tool = create_retriever_tool( retriever, "langsmith_search", # 这里相当于一个工具的使用说明,agent在选择工具时会检查这个说明 "Search for information about LangSmith.For any questions about LangSmith, you must use this tool" ) tools = [search,retriever_tool]注意输入参数的第三行str,是一个对于工具的说明,agent在选择工具时会检查这个说明,类似于一个prompt。最后一行代码,完成了两个工具的封装一个搜索一个检索: tools = [search,retriever_tool] 2. 开始构造一个简单的、无记忆的Agent首先加载一个聊天模型包装器: from langchain_openai import ChatOpenAI llm = ChatOpenAI( temperature=0, openai_api_key = os.getenv("OPENAI_API_KEY"), base_url = os.getenv("OPENAI_BASE_URL") )可以到langsmith的hub里找别人已经写好的提示词,我这里就直接用别人写好的提示词了: from langchain import hub # Get the prompt to use - you can modify this! prompt = hub.pull("hwchase17/openai-functions-agent") print(prompssages[0].prompt.template)然后构造一个agent和一个agent_executor: from langchain.agents import create_openai_functions_agent, AgentExecutor agent = create_openai_functions_agent(llm, tools, prompt) agent_executor = AgentExecutor(agent = agent, tools = tools) agent_executor.invoke({"input":"hello how are you?"})可以看到初步的输出结果:
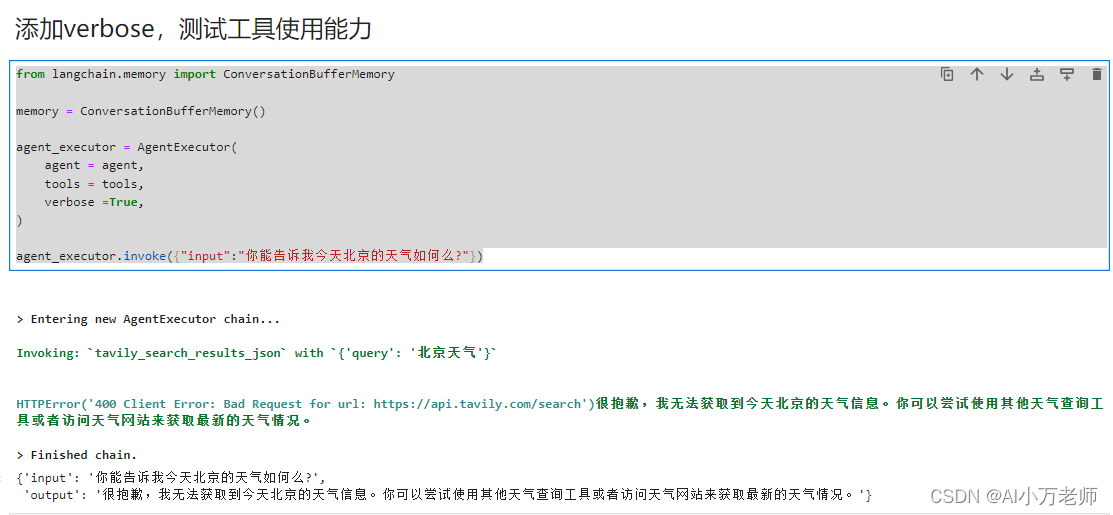
我们想要看一下Agent实现的一些中间过程,这里我们可以给agent_executor添加一个 verbose = True的属性,然后测试一下agent的工具使用能力: from langchain.memory import ConversationBufferMemory memory = ConversationBufferMemory() agent_executor = AgentExecutor( agent = agent, tools = tools, verbose =True, ) agent_executor.invoke({"input":"你能告诉我今天北京的天气如何么?"})这个查询比较失败,看来tavily目前没有查询中国天气的能力:
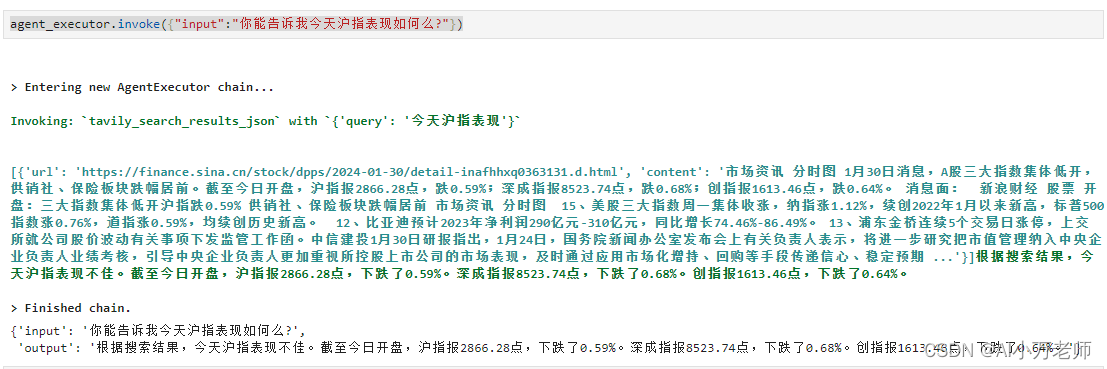
我们来试一试其他的查询:
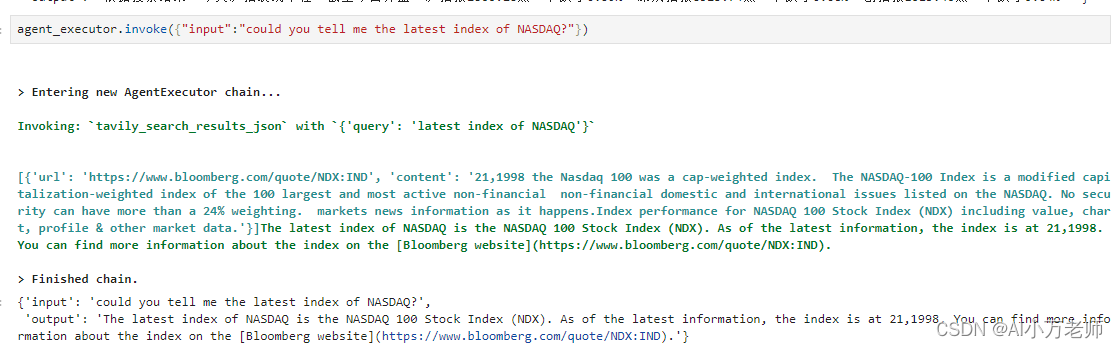
这个表现还好点,不过给的是1月30号的数据,我们看看获取美国那边的数据会不会好点:
给的数据也看不出来是不是最新的,存疑。我们来看看检索器工具好不好使:
检索器工具还不错。 下一篇,我们讨论一下如何给Agent添加记忆功能,并探索更多类型的Agent。 |




【本文地址】
今日新闻 |
推荐新闻 |