python数据分析 |
您所在的位置:网站首页 › 住房面积查询表是什么意思啊 › python数据分析 |
python数据分析
|
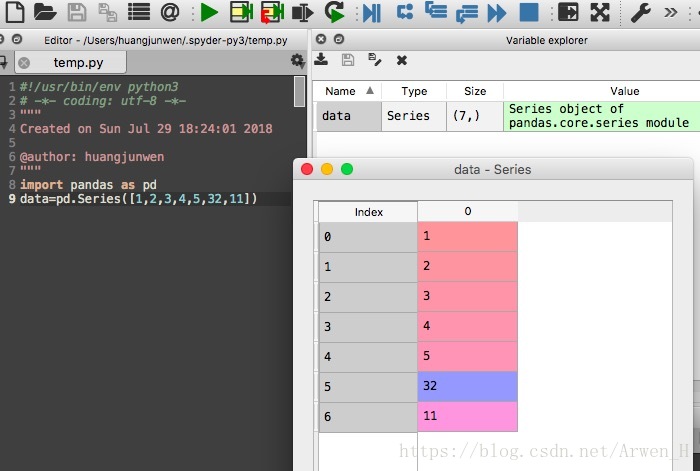
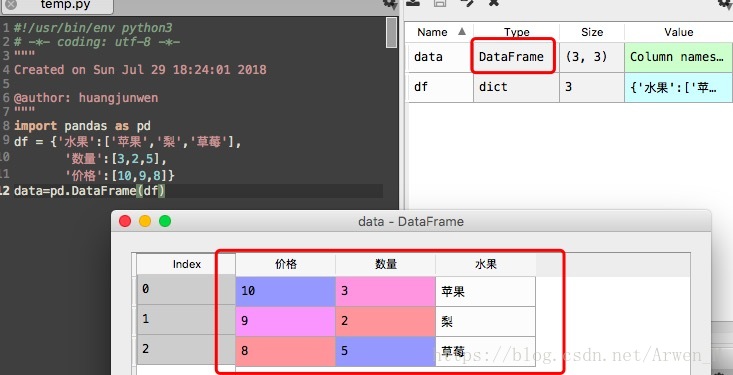
python数据选取,数据查看,获取所需数据这是第一步 前面已经讲了如何用pandas导入数据,这篇文章就来讲一些常用的数据查看、数据选取。做到了这一步,就可以进行一些快速的描述性分析了! 要查看数据与选取数据,我们首先得了解python里数据存储的方式,然后才能进行数据查看、数据选择、数据清洗、数据分析、数据建模等。。 所以本文将分为: 文章目录 一、数据结构篇series介绍编译器里的样子 DataFrame介绍编译器里的样子 二、常用查看/选取数据查看数据常用方法选择数据数据常用方法 三、代码案例及详解案例详解小小练习题(本文会结合大家常用的excel和sql的思维模式来讲解,方便大家具体理解) 一、数据结构篇pandas核心的数据结构有:Series、DataFrame两种,series对照excel我们可以理解为只有一列的数据、DataFrame可以理解为一张完整的表包含字段名、多列多行。series与DataFrame可以进行相互的转化,多个series可以合并成一个DataFrame,而DataFrame可以通过选取一列数据变成Series。 series介绍我们来看看series在anaconda集成spyder编译器里的样子 import pandas as pd #导入pandas库 data=pd.Series([1,2,3,4,5,32,11]) #创建一个series类型的数据 编译器里的样子以下是手动创建的数据一般用的很少,代码只用于结果的展示帮助理解概念。你如果用pandas直接导入数据表之类的,pandas会自动帮你生成一个DataFrame的数据 import pandas as pd df = {'水果':['苹果','梨','草莓'],#用字典的方式手动创建一个 '数量':[3,2,5], '价格':[10,9,8]} data=pd.DataFrame(df)#将数据转化成DataFrame, #!!注意DataFrame使用的时候是需要区分大小写的!! 编译器里的样子在参数说明中DataFrame数据格式的后续简称df,Series数据格式的简称s。pd.DataFrame官方文档 属性描述df.head(n)查看DataFrame对象的前n行df.tail(n)查看DataFrame对象的最后n行df.shape查看数据的行列数各是多少df.info()查看索引、数据类型和内存信息df.describe(percentiles=[.05, .25, .75, .95])查看数值型列的汇总统计,返回计数、均值、标准差、最小最大值、25%50%75%分位数,percentiles0.05,0.95分位数df.unique()快速查看数据列有哪些分类内容,类似groupbys.value_counts(dropna=False)查看Series对象的唯一值和计数df.apply(pd.Series.value_counts)查看DataFrame对象中每一列的唯一值和计数df.sum()返回所有列的求和值df.mean()返回所有列的均值df.corr()返回列与列之间的相关系数df.count()返回每一列中的非空值的个数df.max()返回每一列的最大值df.min返回每一列的最小值df.median()返回每一列的中位数df.std()返回每一列的标准差更多运算函数请查看Python数据分析–计算函数 选择数据数据常用方法 属性描述df[col]根据列名,并以Series的形式返回列df[[col1, col2]]以DataFrame形式返回多列df.loc[:3,‘a’]选取a列,选择特定行的数据 ,返回series格式df.loc[:3,[‘a’]]基于a列,选择特定行的数据,返回DataFrame格式df.loc[1:2,[‘a’,‘b’]] & df.loc[1:2,‘a’:‘b’]基于列label,可选取特定行(根据行index)df.iloc[1:3, [1, 2]] & df.iloc[1:3, 1: 3]基于行/列的positiondf.at[3, ‘tip’]根据指定行index及列label,快速定位DataFrame的元素df.iat[3, 1]与at类似,不同的是根据position来定位的df.iloc[0,:]返回第一行,[x,y]x为行,y为列,:代表所有df.iloc[0,0]返回第一列的第一个元素,直接写入数字代表单点位置s.iloc[0]按位置选取数据s.loc[‘index_one’]按索引选取数据/列名 三、代码案例及详解本文数据连接点击下载 案例详解 import pandas as pd data=pd.read_csv(r'/Users/huangjunwen/Desktop/fandango_score_comparison.csv') #这是我的路径大家使用的时候记得改,记得改,记得改! 查看指定行数的数据 print(data.head(10))#查看前10行数据,数据大的时候可以通过该方式快速看到df的数据格式 选取字段RottenTomatoes_User print(data['RottenTomatoes_User'])#选取一个字段返回series print(data[['RottenTomatoes_User','Fandango_Difference']])#选取两个字段返回DataFrame 选取Metacritic列的指定行内容 print(data.iloc[3,3])#选取Metacriticl列的第4行的数据 print(data.iloc[3,:3])#选取的第3行,第一列至第三列的所有数据 #!注意iloc是根据索引位置进行的判断,如索引顺序不规律会自动帮你找到索引为3的行 print(data.iloc[3,4:5])#留个悬念自己跑数试试 data.reset_index(drop=True) #重置索引按顺序排列 小小练习题查看该数据一共有多少行与列? 答案:对比答案见后 请试着计算字段Metacritic、Metacritic_User、IMDB第2行至第5行各字段的和 答案:对比答案见后 有问题留言,不定时更新 python写法各有不同,希望能找到自己喜欢的方式。以下答案代码只是我个人习惯仅供参考: #查看数据行列 import pandas as pd data=pd.read_csv(r'/Users/huangjunwen/Desktop/fandango_score_comparison.csv') print(data.shape)#查看数据data行列分别是多少 #打印结果为:(146,22)146行,22列 ##计算三个字段和 import pandas as pd data=pd.read_csv(r'/Users/huangjunwen/Desktop/fandango_score_comparison.csv') data.reset_index(drop=True)#重新排列索引方便检查所选位置是否正确 df=data.loc[1:4,['Metacritic','Metacritic_User','IMDB']]#选择数据范围 print(df.sum())#打印计算结果 #打印结果为:Metacritic求和为182,Metacritic_User求和为23.7,IMDB求和为25.4 |
【本文地址】
今日新闻 |
推荐新闻 |