开放领域问答学习笔记 |
您所在的位置:网站首页 › 伊苏9队伍搭配 › 开放领域问答学习笔记 |
开放领域问答学习笔记
|
1 开放领域问答概述
1.1 简介
开放领域问答(Open-domain question answer, QA),即使用大量不同主题的文档来回答问题,是自然语言处理(NLP)、信息检索(IR)和相关领域长期研究的主题。传统的QA系统通常构建为一个 pipeline,由许多不同的组件组成,如问题处理、文档/文章检索和答案处理。随着深度学习的快速发展,现代开放域QA系统通过结合传统IR技术和深度学习模型重构,甚至完全以端到端方式实现。 1.2 技术方案当前开放域问答的技术方案可以主要分为三大类: 1)Two-stage retriever-reader 这类方案通常包含两种组件,文档/段落检索组件和答案抽取组件。首先使用检索组件从大量文档中查找可能包含答案的文档/段落,然后使用答案抽取组件从返回的文档/段落中查找答案。检索组件通常采用传统的sparse vector space方法,如TF-IDF、BM25等实现。答案抽取组件通常采用深度学习模型实现。 2)Dense retriever and end-to-end training 这类方案主要关注如何使用dense representations方法表示代替传统的IR方法,以及如何联合训练检索组件和答案抽取组件。 3)Retriever-free approaches 这类方案没有文档/段落检索组件,依赖于大规模的预训练模型作为隐式知识库,不需要在推理期间访问模型以外的数据。 1.3 常用数据集SQuAD、TriviaQA、Natural Questions、SearchQA、Quasar-T、CuratedTREC、WebQuestions 1.4 评价指标1)Exact match(EM) 精确匹配经过预处理后的两个字符串是否完全相等。 2)F1 测量经过预处理后的两个字符串构成的词袋之间的重叠度。 2 Two-stage retriever-reader================================================================================================ ACL 2017:Reading Wikipedia to Answer Open-Domain Questions ================================================================================================ 概述 本文提出使用基于bigram hashing和TF-IDF的检索组件,基于多层BILSTM的答案抽取组件,结合多任务学习,实现开放领域问答。 模型架构 1)Document Retriever 对语料单词进行清洗,包括去停词等过滤操作,得到所有的bigram,并对bigram做同样规则的清洗得到最终的bigram。将这些bigram进行murmur3 hashing得到每个bigram的id(如果哈系特征数目设置过小,可能会有两个不同bigram的id相同,文章用了特征数目为2^24,可以尽量避免这种哈希冲突)。计算每个每个bigram的TF-IDF。 预测时,根据bigram搜索相关文档,并分别计算问题与返回的文档的bigram TF-IDF向量的相似度,得到与问题最相关的5篇文章。 2)Document Reader 设每个文档包含n个段落,每个段落p={p1, . . . , pm},问题q={q1, . . . , ql}。 Paragraph encoding 使用RNN对p进行编码 Question encodin 使用另外一个RNN对q进行编码,得到 Prediction 对于每个段落,分别计算答案的开始和结束为止
最后对比多个段落, 3)multitask learning 对于CuratedTREC、WebQuestions、WikiMovies使用远监督学习,构造Document Reader的训练数据。 实验结果
特征分析
================================================================================================ 2019:End-to-End Open-Domain Question Answering with BERTserini ================================================================================================
概述 本文提出的架构由基于Anserini的检索组件和基于BERT的答案抽取组件组成。 模型架构 1)Anserini Retriever 本文把检索的对象分成文档、段落、句子三个粒度,探索相应的效果。 使用BM25作为排序函数。 2)BERT Reader 使用BERT-Base作为答案抽取组件,为了可以对比多个文本片段的答案的得分,去掉最后一层softmax层,保留logit分数作为对比。 最后答案的得分,由检索组件和答案抽取组件的得分加权求和得到
实验结果
================================================================================================ ACL 2019:Multi-passage BERT: A Globally Normalized BERT Model for Open-domain Question Answering ================================================================================================ 概述 本文提出几个改进点: 1)之前的模型对同一个问题及其对应的多段候选段落作为独立的训练实例,导致不同段落的答案的分数无法比较。本文提出使用globally normalize,训练过程中对同一问题的多个段落分数进行归一化。 2)把文章按照固定词数划分成段落,结合滑动窗口技术,可以得到4%的提升。 3)使用passage ranker对段落进行评分,可以得到2%的提升。 同时本文测试了问题和段落的显式匹配,对于BERT没有提升。 模型架构 本文的检索模块使用ElasticSearch,BM25作为评分标准。 1)Multi-passage BERT 先把同一问题的多段候选段落分别输入BERT,然后在多个段落的输出上使用softmax。 2)Passage ranker 对于每个段落计算一个得分,然后在多个段落的 实验结果
1)把文章按照100个固定词划分,使用50步的滑动窗口时,效果最好。 2)首先返回100个候选段落,然后使用passage ranker进行评分,对前30个段落提取答案。 3)Multi-passage在返回段落多的情况下,具有鲁棒性。 4)首先使用BERT对问题和段落进行编码,然后把编码结果输入到传统的阅读理解模型如QANet下,效果一般。
================================================================================================ AAAI 2018:R3:Reinforced Ranker-Reader for Open-Domain Question Answering ================================================================================================
概述 本文对提出两个方面的创新:一、提出使用Ranker组件,对搜索组件返回的答案进行挑选,返回最后可能包含答案的段落。二,提出使用强化学习对Ranker和Reader组件进行联合训练。 Match-LSTM简介 首先使用BiLSTM分别对问题和段落进行编码,得到 为了提升效率,本文把注意力权重矩阵的计算方式简化为 问题的最终表示为
最后通过另一个BiLSTM获得段落的最终表示: 模型架构 Ranker和Reader均基于Match-LSTM,其中第一个BiLSTM和矩阵M共享,最后的信息聚合的第二个BiLSTM分别训练。 1)Ranker 首先利用Match-LSTM得到每个段落的表示
其中 动作选择策略为 2)Reader Reader从Ranker选择的段落 首先提取答案开始位置: 其中 最后损失函数定义为: 3)Training Ranker和Reader联合训练,其中Reader采用SGD训练,Ranker从Reader获取监督信号,采用强化学习训练。
损失函数定义为: 训练过程中,为了保证Ranker的梯度的稳定,使用
3)Prediction 预测的时候,结合Ranker和Reader的分数提取答案:
实验结果
================================================================================================ ACL 2018:Denoising Distantly Supervised Open-Domain Question Answering ================================================================================================
概述 本文支持当前的模型只从最相关的段落中提取答案,忽略了其他段落中包含的信息。同时,远监督学习创建的语料包含大量的噪声。本文提出使用段落选择器去除噪声段落,保留有用的段落用于提取答案。 模型架构 首先语料库中搜索返回相关的段落,然后使用段落选择器,去除噪声段落,返回剩下的相关段落,然后使用段落阅读器从返回的段落中提取答案,最后对所有段落提取的答案进行聚合,得到最终的答案。 设问题 段落选择器计算每个段落包含答案相关信息的概率 1)段落选择器 计算每个段落包含答案的概率,用于去除噪声数据。 对于问题,同样分别使用MLP和RNN进行编码:
然后利用self attention获取问题的最终表示
对于段落,分别使用MLP和RNN进行编码:
然后使用max-pooling和softmax计算每个段落包含答案的概率
2)段落阅读器 对于返回的每个段落,首先使用BiLSTM进行编码,得到 然后分别计算答案的开始和结束的位置的概率,并把两个概率相乘,得到该开始和结束位置包含答案的概率:
考虑到一个段落中,正确的答案可能会出现多次的情况,设计算得到的开始和结束位置对为 这里考虑两种情况。 第一种是只返回概率最大的答案位置,则 第二种是对所有的包含答案的位置的概率求和,则 3)训练和推理阶段 训练阶段,损失函数定义为:
其中 推理阶段,最终答案定义为:
对所有段落返回的答案进行聚合,并返回概率最大的答案。 实验结果
================================================================================================ ICLR 2018:Denoising Distantly Supervised Open-Domain Question Answering ================================================================================================
概述 本文指出,之前的模型只从一个段落中提取答案,忽略了其他段落的信息,而正确答案可能需要从多个段落中收集证据。针对这个问题,提出使用两个答案重排序模型,聚合从多个段落中提取的答案。 模型架构 首先使用RC/QA模型提取K个答案,然后使用两个重排序模型,通过不同方式提取信息,读候选答案进行重排序。 strength-based re-ranker:根据答案出现的频率对答案进行排序。 coverage-based re-ranker:如果某个答案的多个不同段落的所有上下文结合起来,可以为问题提供更多的信息,那么该答案得分更高。 1)strength-based re-ranker 通过两种方式计算答案的分数。第一,计算答案在多个段落返回的结果中出现的次数统计。第二,计算答案在多个段落返回的结果中的概率的得分。 2)coverage-based re-ranker 对于每个答案,将包含该答案的所有段落拼接在一起,然后和问题一起输入到一个attention-based match-LSTM模型,得到一个匹配度分数。 设返回的top-k答案为 首先把答案a,问题q,相关段落
然后把 然后分别计算问题和各个答案相关段落的交互表示 然后计算
然后把M输入到另外一个BiLSTM,再通过MaxPooling得到最终表示:
最后把多个答案的交互表示拼接,计算最终的输出:
损失函数使用KL散度计算:
最后,结合两种re-ranker是的输出。首先使用softmax重新标准化两个strength-based re-ranker的输出,结合coverage-based re-ranker的输出,把所有输出相加,选择分数最大的答案作为最终预测。 实验结果
================================================================================================ ACL 2019:Latent Retrieval for Weakly Supervised Open Domain Question Answering ================================================================================================
概述 本文指出,当前的开放领域对话系统需要依赖一个传统的不可训练的IR系统,在用户预先知道答案的情况下,传统的IR系统可以得到不错的效果,但是当用户不知道答案的情况下,传统的IR系统效果下降严重。 本文提出一个可训练的IR系统,可以解决这个问题。首先对IR系统进行预训练,然后对IR系统和RC系统同时进行END-TO-END的微调。 模型架构 设语料包含B条候选文本片段,b是其中一条片段,s是答案所在的位置,所以一个答案表示为(b,s),答案的开始和结束位置分别为START(s)和END(s)。评分函数S(b,s,q)表示给定问题q,答案(b,s)作为正确答案的得分。 通常评分函数由检索模块得分和阅读模块得分两部分组成:
预测时,返回得分最高的答案:
1)Retriever component 分别使用两个BERT提取问题和候选片段的特征,然后通过内积计算相似度:
2)Reader component 通过一个单独的BERT提取答案的开始和结束位置,然后出入到一个全连接神经网络提取得分:
3)Retriever component Pre-training 单纯的使用OpenQA的语料不足以训练以上的模型,所以需要先对检索组件的BERT进行预训练。 本文使用Inverse Cloze Task语料运行预训练吗,把目标句子当做是问题,把目标句子周围的句子当作是需要返回的候选证据。
后续微调时,固定 4)Inference 在推理时,由于 从候选片段中返回得分最高的top-k条。 5)Learning 损失函数定义如下:
为了提升训练效率,本文提出一个早期学习,只更新检索分数,这个阶段检索回来的片段会比较多,取c等于5000:
最后的损失包含两部分:
实验结果
================================================================================================ 2020:REALM: Retrieval-Augmented Language Model Pre-Training ================================================================================================
概述 本文指出之前的预训练语言模型的知识隐晦的存储在模型参数当中,无法清晰的了解模型学习到的知识。本文提出一种新的方法REALM,通过知识检索的方式进行语言模型的预训练,让学习到的模型可解释更强,更加模块化,并应用在开发领域问答当中。 模型架构
设无标注的预训练语料库为 REALM的工作方式可以分为检测-预测两歩,给定输入x,首先从语料库中检索相关的文档 预训练和微调的过程会有轻微的差别。在预训练的过程中,输入x中的某些单词会被mask掉,REALM首先从语料库 REALM可以分为两部分:neural knowledge retriever、knowledge-augmented encoder 1)Neural Knowledge Retriever 检索过程的评分计算方式如下:
其中Embed使用BERT提取,对于句子和文本的计算方式如下:
2)Knowledge-Augmented Encoder 预训练时,使用masked language modeling方式训练,损失函数定义为:
其中 微调时,使用开放领域对话的方式进行训练,损失函数定义为:
3)Training 预测结果可以表示为 由于模型参数在不断的更新,所以文档的索引
MLM trainer训练过程中不断的向Index builder发送新参数的快照。Index builder使用当前参数在后台构建语料库文档的索引,当使用当前参数构建完所有索引后,更新参数,然后重新构造索引,不断重复这个过程。 只有在预训练的过程中会刷新文档的索引,在微调时,文档的索引在最开始生成后,不再更新。 4)训练策略 有几个额外的策略,可以提升模型的效果: 通过屏蔽命名实体和时间,可以提升模型学习知识的效果;某些知识不需要引入外部文档就可以预测得出,通过添加空文档的方式,可以提升学习效果;把预训练的语料库和微调的语料库中重叠的部分去掉;对于Retriever,使用Inverse Cloze Task(ICT)来warm-start。对于Encoder,使用BERT-base来warm-start。实验结果
特征分析
================================================================================================ EMNLP 2020:Dense Passage Retrieval for Open-Domain Question Answering ================================================================================================
概述 本文指出,通过孪生网络架构,使用小型的问答库语料,就可以训练出效果很好的基于稠密向量(dense vectors)的文档检索模块,不需要使用其他额外的语料进行预训练。提出的文档检索模块命名为DPR。 模型架构 设问答语料库为 问题和段落编码器使用两个独立的BERT,分别表示为 推理时,首先使用 1)检索模块预训练 训练样本表示为
对于正样本,选择包含答案的段落。对于负样本,本文使用三种方式选取: Random:随机选取段落作为负样本BM25:使用BM25返回的段落作为负样本Gold:包含其他问题的答案的段落作为负样本实验结果表示,使用同一batch的其他问题的答案段落加上BM25返回的第一条非答案段落组成负样本,效果最好。 本文尝试结合BM25和DPR,计算方式为 本文还测试了使用单独的数据集和结合多个数据集训练的效果的区别。 2)端到端问答系统微调 在DPR的基础上加入答案抽取模块,可以实现端到端的问答系统。 检索模块使用在多个数据集上训练的DPR作为初始化。 答案抽取模块使用另一个BERT,其中,段落选择得分为:
答案的开始和结束位置得分为:
答案最终得分为:
实验结果 1)检索模块
2)问答系统
|

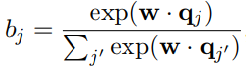
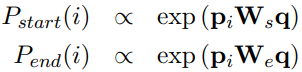










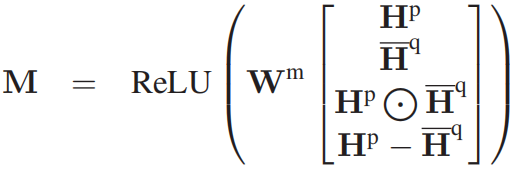
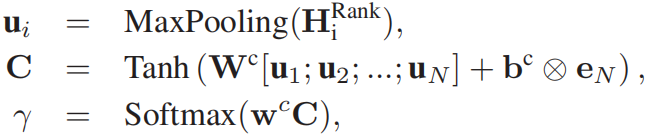

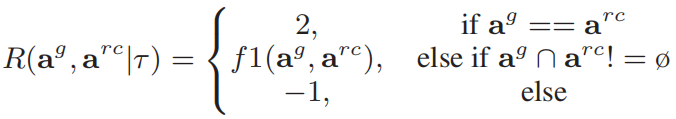




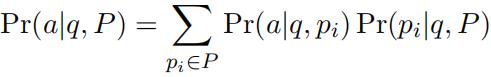 。
。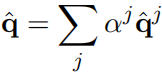 ,
,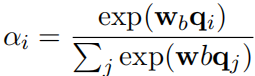
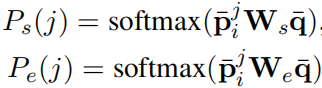
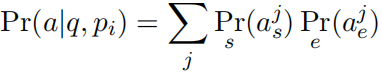 。这里只是适用于训练阶段,因为训练阶段知道正确答案是什么。
。这里只是适用于训练阶段,因为训练阶段知道正确答案是什么。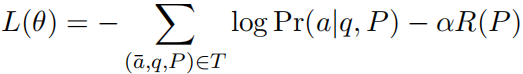
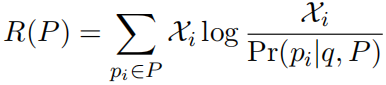
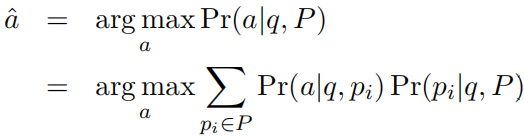






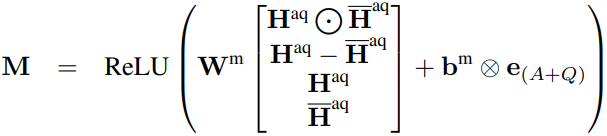
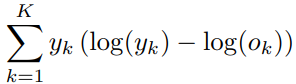




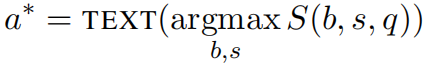
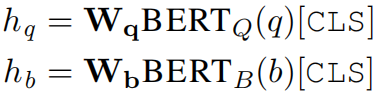
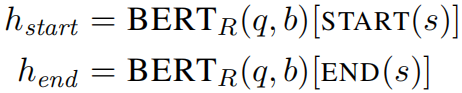

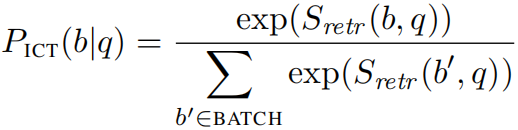
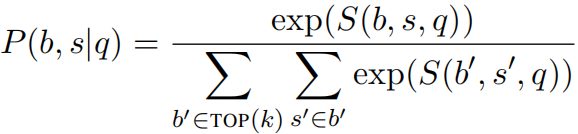
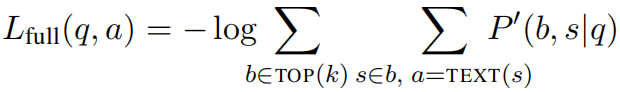






















【本文地址】
今日新闻 |
推荐新闻 |