python爬虫实战 |
您所在的位置:网站首页 › 今日票房实时猫眼 › python爬虫实战 |
python爬虫实战
|
小白级别的爬虫入门
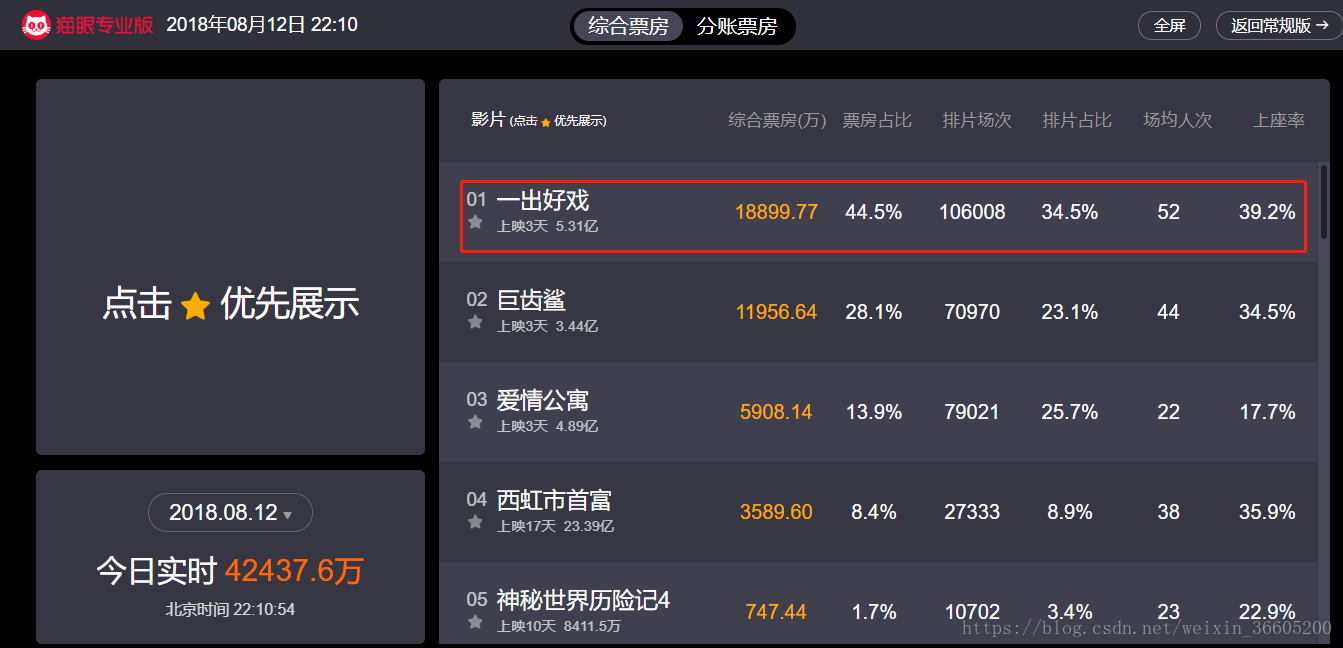
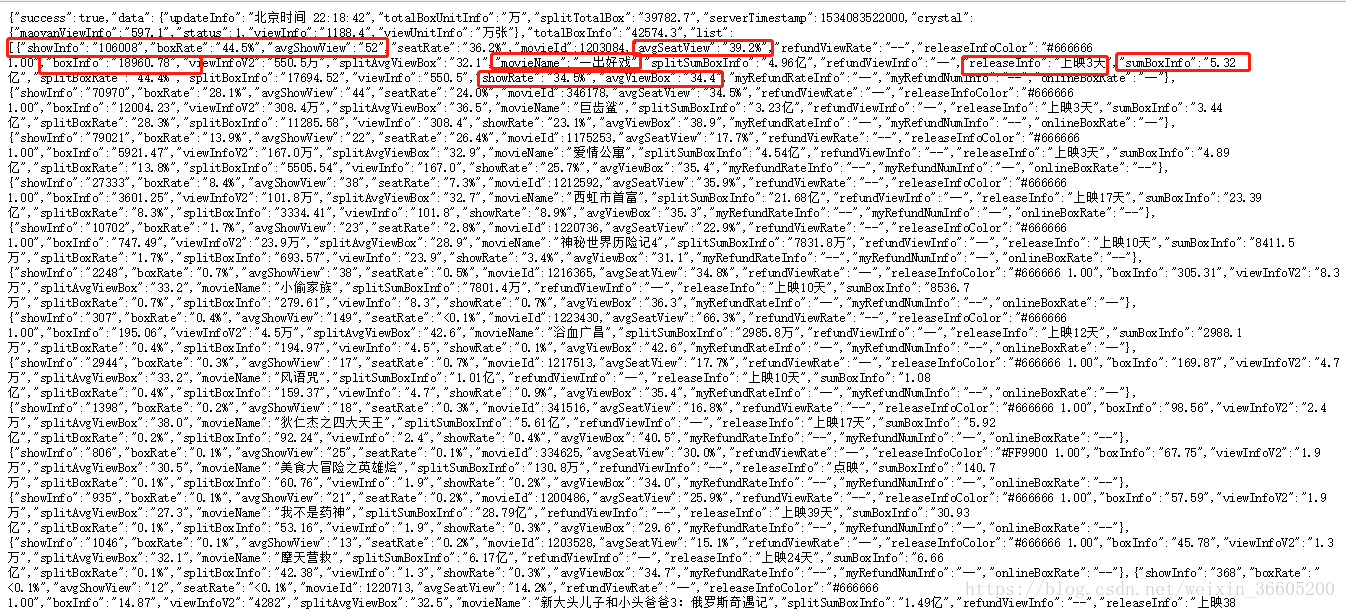
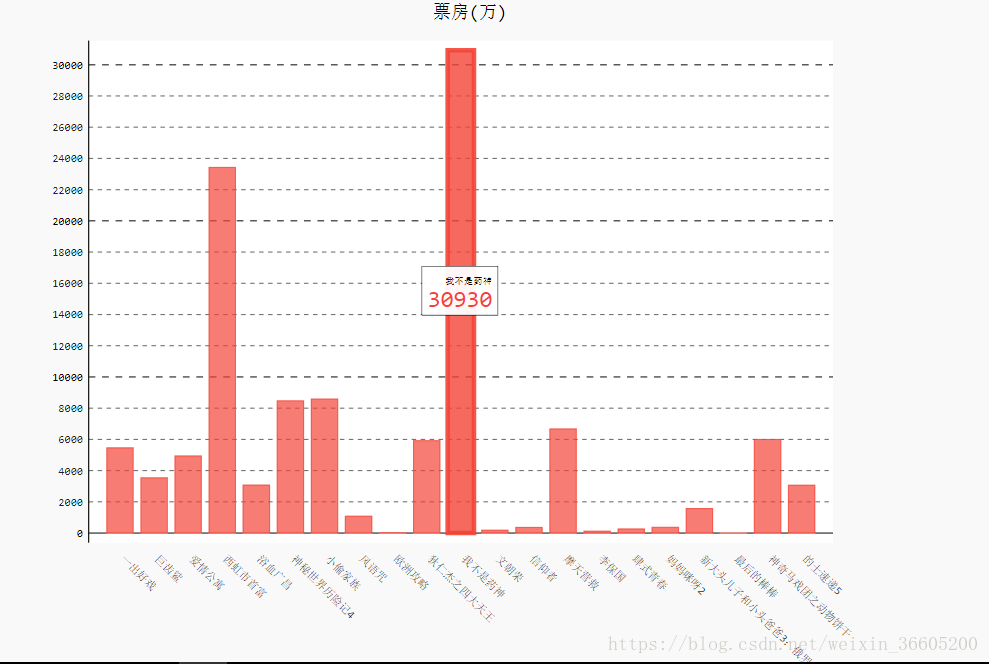
最近闲来无事,发现了猫眼专业版-实时票房,可以看到在猫眼上映电影的票房数据,便验证自己之前学的python爬虫,爬取数据,做成.svg文件。 爬虫开始之前我们先来看看猫眼专业版-实时票房这个网页,看看我们要爬取的数据,分析网页的结构和查看源码。 (1)网页链接:https://piaofang.maoyan.com/dashboard (2)爬取的数据:红框框里面的数据就是我们想要的 (3)查看网页源码:从网页源码中看到我们想要的数据并没有存在,所以通过直接的爬虫爬取数据,也只是获到这部分内容(有试过),这是因为数据是动态加载的。 (4)分析数据是以什么方式出现:检查元素,点击network,再进行刷新,你就会发现这时候会加载一个json文件 json文件的url:https://box.maoyan.com/promovie/api/box/second.json,是动态来加载数据的。从文件中我们就可以看到了我们想要爬取的数据,数据存储在为“list”的关键字里面,接下来我们每次爬取数据就只要抓取这个json文件来进行数据的分析和处理即可 库的选择:BeautifuSoup、urllib.request、json、pygal 部分代码: # 打开网页,获取源码 def open_page(url): try: netword=urlopen(url) except HTTPError as hp: print(hp) else: # 采用BeautifulSoup来解析,且指定解析器 html=bs(netword,'lxml') return html # 获取网页数据 def get_page(url): # 电影名称,上映天数,电影总票房,票房占比,排片场次,排片占比,场均人次,上座率 movieName,releaseInfo,sumBoxInfo,boxInfo,boxRate,showInfo,showRate,avgShowView,avgSeatView=[],[],[],[],[],[],[],[],[] html=open_page(url) p=html.find('p') text=p.get_text() # 将数据转换为python能够处理的格式 jsonObj=json.loads(text) # 获取字典里面特定的键对应的键值 data=jsonObj.get('data') # 想要的数据就在字典的键"list"对应的值 lists=data.get('list') # print(type(lists)==type([]))判断类型 for list in lists: # 获取字典里面特定的键对应的键值,并存储到列表中去 movieName.append(list.get('movieName')) releaseInfo.append(list.get('releaseInfo')) sumBoxInfo.append(list.get('sumBoxInfo')) boxInfo.append(list.get('boxInfo')) boxRate.append(list.get('boxRate')) showInfo.append(list.get('showInfo')) showRate.append(list.get('showRate')) avgShowView.append(list.get('avgShowView')) avgSeatView.append(list.get('avgSeatView')) return movieName,就这样吧,把要爬取的数据全部存储到列表中去了,最终的实现结果(只是处理了两个数据,总票房和综合票房,做出svg文件): 总票房: 综合票房: 完整代码链接:https://pan.baidu.com/s/1SI2IKuGJS8Z5NJPwzVGk1w 密码:vrif |



【本文地址】
今日新闻 |
推荐新闻 |