爬取今日热榜微博的前十名热点信息数据 |
您所在的位置:网站首页 › 今日热搜榜前十 › 爬取今日热榜微博的前十名热点信息数据 |
爬取今日热榜微博的前十名热点信息数据
|
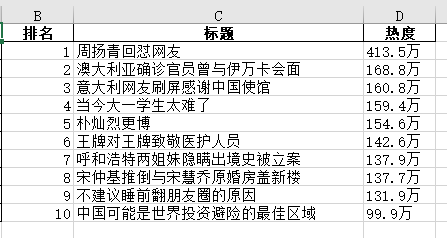
打开今日热榜网站,鼠标右键并查看网页源代码,是html结构,找到热搜榜第一条标题所在的位置。 找到对应标签span,发现class=‘t'是标题,class=’e'是热度,此时爬取目标已经很明确了, 通过find_all()函数查找所有对应内容,最后再用.string方法将找到的内容转化为字符串形式打印出来。 整体代码如下: 1 import requests 2 from bs4 import BeautifulSoup 3 import pandas as pd 4 from pandas import DataFrame 5 6 #定义一个获取html文本的函数 7 def getHTMLText(url): 8 try: 9 #为确保成功访问网站,将爬虫伪装成浏览器 10 headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'} 11 r = requests.get(url,timeout = 30,headers=headers) 12 r.raise_for_status() 13 #更改为utf-8编码以确保不会乱码 14 r.encoding = 'utf-8' 15 return r.text 16 except: 17 return "" 18 19 #定义一个获取并打印爬取数据的函数 20 def printWeiboHot(lst,html,num): 21 #煲汤 22 soup = BeautifulSoup(html, 'html.parser') 23 #查找需要爬取的数据,并将其存放于两个列表里 24 lst1 = soup.find_all('span', class_='t') 25 lst2 = soup.find_all('span', class_='e') 26 #主标题 27 print('{:^55}'.format('微博热搜榜')) 28 #列名 29 print('{:^5}\t{:^40}\t{:^10}'.format('排名', '标题', '热度')) 30 #通过循环把爬取的数据一行一行打印出来 31 for i in range(num): 32 print('{:^5}\t{:^30}\t{:^10}'.format(i+1, lst1[i].string, lst2[i].string)) 33 #将爬取的数据整合到一个列表里,以便输出 34 lst.append([i+1,lst1[i].string,lst2[i].string]) 35 36 #主函数 37 def main(): 38 num = 10 39 lst = [] 40 url = 'https://tophub.today/' 41 html = getHTMLText(url) 42 printWeiboHot(lst,html,num) 43 #创建一个DataFrame存放爬取的数据并将其用excel保存 44 df = pd.DataFrame(lst,columns=['排名','标题','热度']) 45 WeiboHot = r'C:\Users\Yaoner\WeiboHot.xlsx' 46 df.to_excel(WeiboHot) 47 48 main()输出到Excel的结果如下:
|
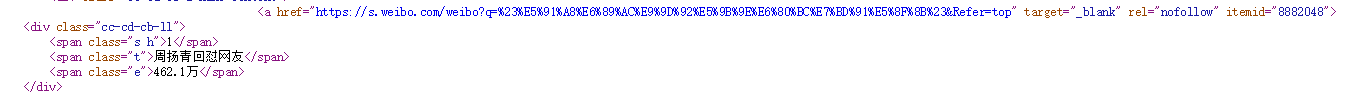
【本文地址】
今日新闻 |
推荐新闻 |