Guide to Spring Batch Processing |
您所在的位置:网站首页 › 今年平安夜是几号 › Guide to Spring Batch Processing |
Guide to Spring Batch Processing
|
Batch processing—typified by bulk-oriented, non-interactive, and frequently long running, background execution—is widely used across virtually every industry and is applied to a diverse array of tasks. Batch processing may be data or computationally intensive, execute sequentially or in parallel, and may be initiated through various invocation models, including ad hoc, scheduled, and on-demand. This Spring Batch tutorial explains the programming model and the domain language of batch applications in general and, in particular, shows some useful approaches to the design and development of batch applications using the current Spring Batch 3.0.7 version. What is Spring Batch? Spring Batch is a lightweight, comprehensive framework designed to facilitate development of robust batch applications. It also provides more advanced technical services and features that support extremely high volume and high performance batch jobs through its optimization and partitioning techniques. Spring Batch builds upon the POJO-based development approach of the Spring Framework, familiar to all experienced Spring developers. By way of example, this article considers source code from a sample project that loads an XML-formatted customer file, filters customers by various attributes, and outputs the filtered entries to a text file. The source code for our Spring Batch example (which makes use of Lombok annotations) is available here on GitHub and requires Java SE 8 and Maven. What is Batch Processing? Key Concepts and TerminologyIt is important for any batch developer to be familiar and comfortable with the main concepts of batch processing. The diagram below is a simplified version of the batch reference architecture that has been proven through decades of implementations on many different platforms. It introduces the key concepts and terms relevant to batch processing, as used by Spring Batch. 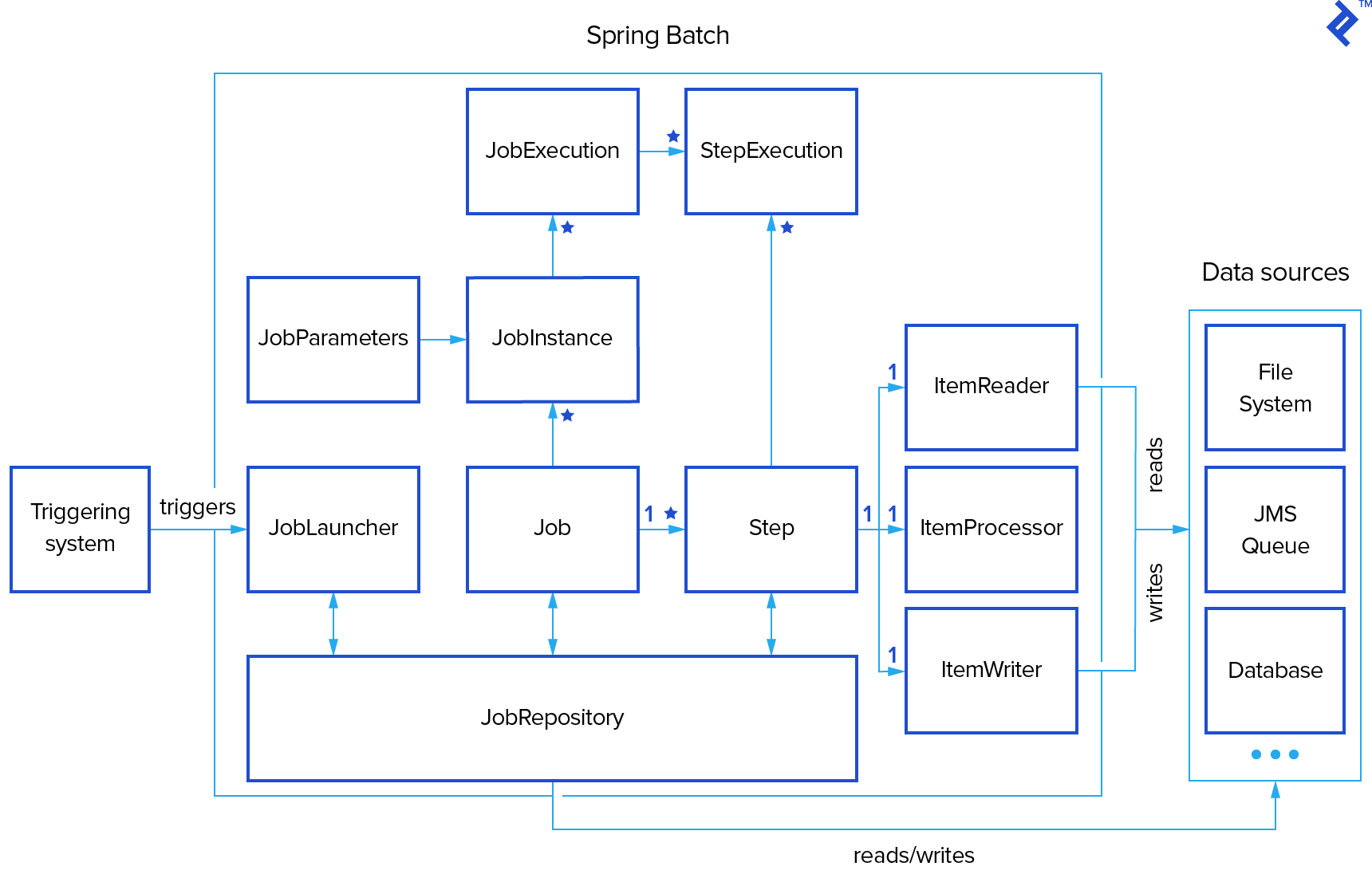
As shown in our batch processing example, a batch process is typically encapsulated by a Job consisting of multiple Steps. Each Step typically has a single ItemReader, ItemProcessor, and ItemWriter. A Job is executed by a JobLauncher, and metadata about configured and executed jobs is stored in a JobRepository. Each Job may be associated with multiple JobInstances, each of which is defined uniquely by its particular JobParameters that are used to start a batch job. Each run of a JobInstance is referred to as a JobExecution. Each JobExecution typically tracks what happened during a run, such as current and exit statuses, start and end times, etc. A Step is an independent, specific phase of a batch Job, such that every Job is composed of one or more Steps. Similar to a Job, a Step has an individual StepExecution that represents a single attempt to execute a Step. StepExecution stores the information about current and exit statuses, start and end times, and so on, as well as references to its corresponding Step and JobExecution instances. An ExecutionContext is a set of key-value pairs containing information that is scoped to either StepExecution or JobExecution. Spring Batch persists the ExecutionContext, which helps in cases where you want to restart a batch run (e.g., when a fatal error has occurred, etc.). All that is needed is to put any object to be shared between steps into the context and the framework will take care of the rest. After restart, the values from the prior ExecutionContext are restored from the database and applied. JobRepository is the mechanism in Spring Batch that makes all this persistence possible. It provides CRUD operations for JobLauncher, Job, and Step instantiations. Once a Job is launched, a JobExecution is obtained from the repository and, during the course of execution, StepExecution and JobExecution instances are persisted to the repository. Getting Started with Spring Batch FrameworkOne of the advantages of Spring Batch is that project dependencies are minimal, which makes it easier to get up and running quickly. The few dependencies that do exist are clearly specified and explained in the project’s pom.xml, which can be accessed here. The actual startup of the application happens in a class looking something like the following: @EnableBatchProcessing @SpringBootApplication public class BatchApplication { public static void main(String[] args) { prepareTestData(1000); SpringApplication.run(BatchApplication.class, args); } }The @EnableBatchProcessing annotation enables Spring Batch features and provides a base configuration for setting up batch jobs. The @SpringBootApplication annotation comes from the Spring Boot project that provides standalone, production-ready, Spring-based applications. It specifies a configuration class that declares one or more Spring beans and also triggers auto-configuration and Spring’s component scanning. Our sample project has only one job that is configured by CustomerReportJobConfig with an injected JobBuilderFactory and StepBuilderFactory. The minimal job configuration can be defined in CustomerReportJobConfig as follows: @Configuration public class CustomerReportJobConfig { @Autowired private JobBuilderFactory jobBuilders; @Autowired private StepBuilderFactory stepBuilders; @Bean public Job customerReportJob() { return jobBuilders.get("customerReportJob") .start(taskletStep()) .next(chunkStep()) .build(); } @Bean public Step taskletStep() { return stepBuilders.get("taskletStep") .tasklet(tasklet()) .build(); } @Bean public Tasklet tasklet() { return (contribution, chunkContext) -> { return RepeatStatus.FINISHED; }; } }There are two main approaches to building a step. One approach, as shown in the above example, is tasklet-based. A Tasklet supports a simple interface that has only one method, execute(), which is called repeatedly until it either returns RepeatStatus.FINISHED or throws an exception to signal a failure. Each call to the Tasklet is wrapped in a transaction. Another approach, chunk-oriented processing, refers to reading the data sequentially and creating “chunks” that will be written out within a transaction boundary. Each individual item is read in from an ItemReader, handed to an ItemProcessor, and aggregated. Once the number of items read equals the commit interval, the entire chunk is written out via the ItemWriter, and then the transaction is committed. A chunk-oriented step can be configured as follows: @Bean public Job customerReportJob() { return jobBuilders.get("customerReportJob") .start(taskletStep()) .next(chunkStep()) .build(); } @Bean public Step chunkStep() { return stepBuilders.get("chunkStep") .chunk(20) .reader(reader()) .processor(processor()) .writer(writer()) .build(); }The chunk() method builds a step that processes items in chunks with the size provided, with each chunk then being passed to the specified reader, processor, and writer. These methods are discussed in more detail in the next sections of this article. Custom ReaderFor our Spring Batch sample application, in order to read a list of customers from an XML file, we need to provide an implementation of the interface org.springframework.batch.item.ItemReader: public interface ItemReader { T read() throws Exception, UnexpectedInputException, ParseException, NonTransientResourceException; }An ItemReader provides the data and is expected to be stateful. It is typically called multiple times for each batch, with each call to read() returning the next value and finally returning null when all input data has been exhausted. Spring Batch provides some out-of-the-box implementations of ItemReader, which can be used for a variety of purposes such as reading collections, files, integrating JMS and JDBC as well as multiple sources, and so on. In our sample application, the CustomerItemReader class delegates actual read() calls to a lazily initialized instance of the IteratorItemReader class: public class CustomerItemReader implements ItemReader { private final String filename; private ItemReader delegate; public CustomerItemReader(final String filename) { this.filename = filename; } @Override public Customer read() throws Exception { if (delegate == null) { delegate = new IteratorItemReader(customers()); } return delegate.read(); } private List customers() throws FileNotFoundException { try (XMLDecoder decoder = new XMLDecoder(new FileInputStream(filename))) { return (List) decoder.readObject(); } } }A Spring bean for this implementation is created with the @Component and @StepScope annotations, letting Spring know that this class is a step-scoped Spring component and will be created once per step execution as follows: @StepScope @Bean public ItemReader reader() { return new CustomerItemReader(XML_FILE); } Custom ProcessorsItemProcessors transform input items and introduce business logic in an item-oriented processing scenario. They must provide an implementation of the interface org.springframework.batch.item.ItemProcessor: public interface ItemProcessor { O process(I item) throws Exception; }The method process() accepts one instance of the I class and may or may not return an instance of the same type. Returning null indicates that the item should not continue to be processed. As usual, Spring provides few standard processors, such as CompositeItemProcessor that passes the item through a sequence of injected ItemProcessors and a ValidatingItemProcessor that validates input. In the case of our sample application, processors are used to filter customers by the following requirements: A customer must be born in the current month (e.g., to flag for birthday specials, etc.) A customer must have less than five completed transactions (e.g., to identify newer customers)The “current month” requirement is implemented via a custom ItemProcessor: public class BirthdayFilterProcessor implements ItemProcessor { @Override public Customer process(final Customer item) throws Exception { if (new GregorianCalendar().get(Calendar.MONTH) == item.getBirthday().get(Calendar.MONTH)) { return item; } return null; } }The “limited number of transactions” requirement is implemented as a ValidatingItemProcessor: public class TransactionValidatingProcessor extends ValidatingItemProcessor { public TransactionValidatingProcessor(final int limit) { super( item -> { if (item.getTransactions() >= limit) { throw new ValidationException("Customer has less than " + limit + " transactions"); } } ); setFilter(true); } }This pair of processors is then encapsulated within a CompositeItemProcessor that implements the delegate pattern: @StepScope @Bean public ItemProcessor processor() { final CompositeItemProcessor processor = new CompositeItemProcessor(); processor.setDelegates(Arrays.asList(new BirthdayFilterProcessor(), new TransactionValidatingProcessor(5))); return processor; } Custom WritersFor outputting the data, Spring Batch provides the interface org.springframework.batch.item.ItemWriter for serializing objects as necessary: public interface ItemWriter { void write(List |
【本文地址】
今日新闻 |
推荐新闻 |