临床预测模型这么火,它到底是什么? |
您所在的位置:网站首页 › 什么是预测模型 › 临床预测模型这么火,它到底是什么? |
临床预测模型这么火,它到底是什么?
|
1)目标疾病领域的目标结果是什么?如糖尿病、心血管疾病;某一并发症、死亡。 2)目标患者是谁?如普通人群、65岁以上老年人或2型糖尿病患者。 3)预测模型的目标用户是谁?如疾病领域内其他医生、健康相关组织、有患病风险的群体、其他关心该疾病的群体。 根据以上问题的答案,结合目标领域、患者选择相关领域的数据集,目标用户的类别将决定指标的选择和处理过程,这将影响临床预测模型的专业度和复杂性。
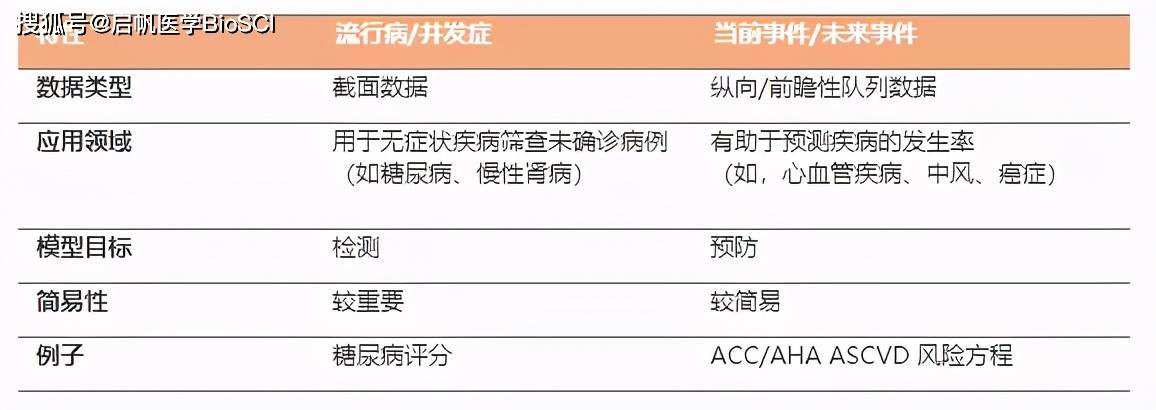
预测模型可应用的问题类型 2 第二阶段:选择数据集 在融合的过程中,医教研管等应用层面的落地,需要人才的聚集和产业生态的建立。自2013年成立以来,近百家中国领先医疗研究机构(排名前150)和政府机构与医疗人工智能公司医渡云达成合作。医渡云在发展中,凭借战略的国际化和文化的多元性,吸引了全球知名科学家及专业领域的优秀人才,为医院处理和集成融合了横跨10余年的医学信息,覆盖40余类重大病种,创建3000多个专科疾病模型,自主开发了医学数据智能平台。 数据集是临床预测模型最重要的组成部分之一,现实中需要搜索最适合的数据集并将其最大利用。通常也可以选择使用专业的临床数据源辅助和管理工具,梳理和建立包含研究终点和所有关键预测因子的主数据集。研究人员可根据预测模型的目的使用方法从中提取不同的子数据集。 不同的临床预测模型问题适合用不同的研究设计数据来回答。对于诊断类问题,其预测因子与结局均在同一时点或很短的时间内,适合采用横断面研究数据构建诊断模型;对于预后类问题,其预测因子与结局有纵向的时间逻辑,适合采用队列研究数据拟合预后模型。随机对照临床试验可视为更为严格前瞻性队列,因此也可用于建立预后模型,但在外推性受限。不同类型的临床预测模型特点如下表所示:
不同预测模型的特点及数据的选择 对于数据集中样本数量的最低要求,没有绝对共识。一般来说,大型、较新的数据集能够更好地反映目标群体的特征,可以增强模型的相关性、可重复性和可推广性,是建模的理想选择。 为了客观验证建模结果,通常需要将研究数据分成两个部分:训练数据集和验证数据集。根据研究者的特定目标,分割率可能会有所不同,但一般来说,应将更多的研究对象分配给开发数据集,而不是验证数据集。 临床预测模型首先通过算法从训练集的中提取规律,其预测性能应根据验证集在不同人群中进行评估。为了确定模型的扩展性和鲁棒性,还可以根据数据集的格式尽可能使用来自外部研究人群或队列组建测试数据集进行外部验证。
医疗大数据已成为预测模型数据集的重要选择 3 第三阶段:处理特征变量 首先要对确定的数据集进行基本清洗,包含包括检查数据一致性,处理无效值和错误值等。由于数据集包含的变量通常多于最终预测模型使用的变量,因此在建立模型前需要评估和选择最具预测性和敏感性的预测因子。一般来说,对特征变量的评估有三个主要方面: 1、需要核查人员对缺失数据进行处理在大多数数据分析中,丢失数据是一个长期的问题,丢失原因各有差异,包括未收集、不可用或不适用、被调查者拒绝、或“不知道”等。为了解决这个问题,研究人员可以考虑采用插补技术,将答案分为“是”和“其他”,或者允许“未知”作为单独的类别,尽可能提高数据的填充率。 2、需要专家的经验判断之前被发现的具有重要意义的预测因子,通常应被视为候选变量,如糖尿病风险评分中的糖尿病家族史。需要注意的是,并非所有重要的预测因子都需要纳入最终模型,如p |

【本文地址】
今日新闻 |
推荐新闻 |