基于哈夫曼编码的文件压缩 |
您所在的位置:网站首页 › 什么是用比例解 › 基于哈夫曼编码的文件压缩 |
基于哈夫曼编码的文件压缩
|
文章目录
前言一、什么是文件压缩?二、为什么需要文件压缩三、怎样实现文件压缩四、创建哈夫曼树1.哈夫曼编码的方式2.构建一棵哈夫曼树
五、压缩1.获取原文件中每个字节出现的次数2.根据字节出现的频次信息构建Huffman树3.获取Huffman编码4.使用Huffman编码来改写文件(压缩)
六、解压缩1.获取解压缩用到的信息2.恢复哈夫曼树3.恢复原文件(解压缩)
总结
前言
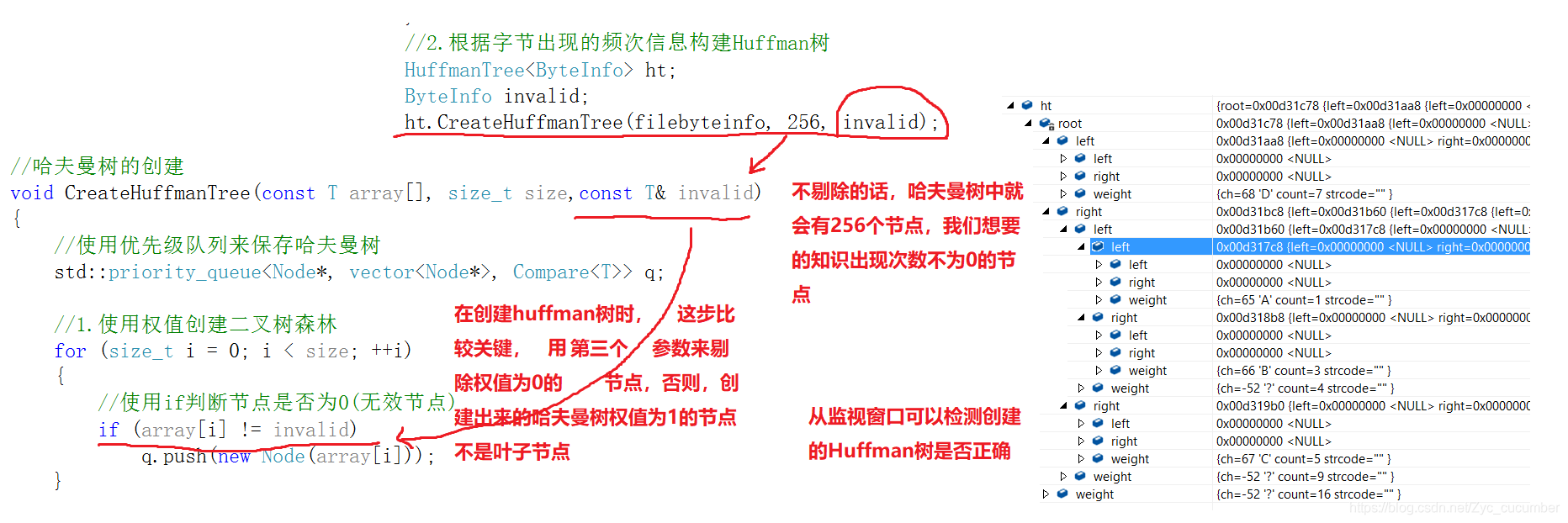
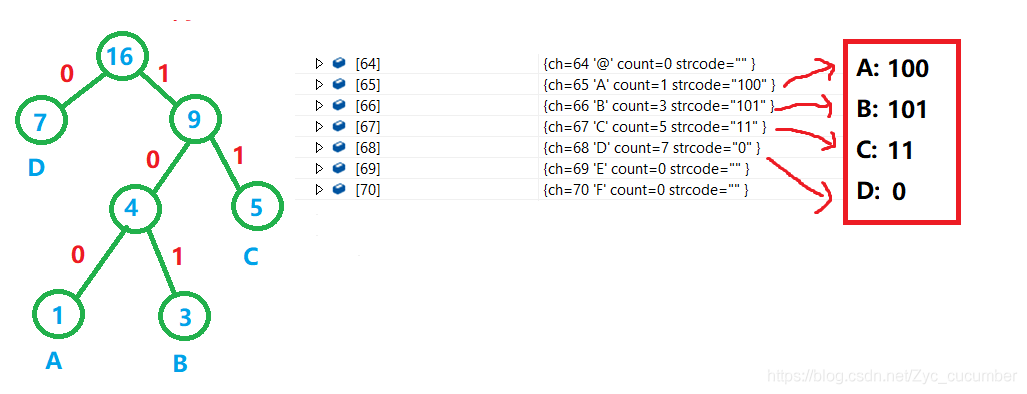
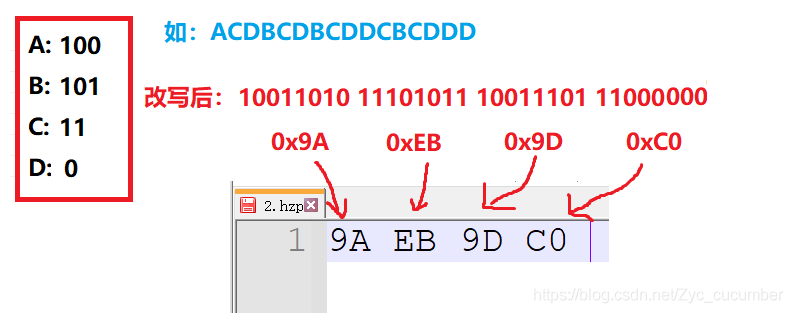
文件压缩的概念在生活中已经屡见不鲜,在这个信息化的时代,我们每天的生活基本上离不开手机电脑,在手机或电脑上下载软件,应用,基本上都能接触到文件压缩。对于文件压缩来讲,有许多种不同的方式,每种方式也有各自的优缺点,这篇文章,就主要介绍以哈夫曼编码的方式来实现文件压缩。 以下是本篇文章正文内容,下面案例可供参考,如有问题,还请大佬及时指正,交流学习!!! 一、什么是文件压缩?文件压缩是指在不丢失有用信息的前提下,缩减数据量以减少存储空间,提高其传输、存储和处理效率,或按照一定的算法对文件中数据进行重新组织,减少数据的冗余和存储的空间的一种技术方法。 实现压缩的方式,大体上主要分为两类:有损压缩和无损压缩。 无损压缩:简单来将,就是压缩之后的文件经过还原后与源文件相同。常用于对文件的压缩 有损压缩:压缩过程中损失一定的信息,常用于图片或视频的压缩,有损压缩的压缩比率要比无损压缩高。 而对于文件的压缩,常用的方式有: ①专有名词采用的固定短语 ②缩短文件中重复的数据 ③给文件中每个字节找一个更短的编码 其中,给文件中每个字节找一个更短的编码这种方式较为常用。因为,文件中的数据在磁盘中都是以字节的方式来进行存储的,1字节=8比特位,可以给每个字节找一个更短的比特位编码来表示,这样就可以达到压缩(减小文件所占空间)的目的。 下图是使用等长的二进制编码来对源文件进行改写: 基于哈夫曼编码的文件压缩方式就是使用不等长的编码来对原文件进行改写的。使用Huffman编码来进行文件压缩要经过四个步骤: 1.获取原文件中每个字节出现的次数 2.根据字节出现的频次信息构建Huffman树 3.获取Huffman编码 4.使用Huffman编码来改写文件 1.哈夫曼编码的方式前面介绍用不等长编码的方式来对文件进行改写,但这些编码是怎么来的呢?为什么A:100 ,B:101, C:11, D:0 这中编码方式是通过哈夫曼树来进行编排的: 知道了哈夫曼编码的方式之后,到底该如何构建一棵哈夫曼树呢? 从二叉树的根结点到二叉树中所有叶结点的路径长度与相应权值的乘积之和为该二叉树的带权路径长度WPL,将带权路径最小的二叉树称为Huffman树。 下图展示了哈夫曼树的构建方法: 压缩过程需要要经过四个步骤: 1.获取原文件中每个字节出现的次数对于获取文件中每个字节出现的次数,采用一个含有256个结构体类型的数组来保存较为方便。因为文件在磁盘中都是以字节的方式来进行存储的,可以用每个字符对应的ASCII码值来作为数组的下标,只需遍历文件中的每一个字节,遇到对应ASCII码的元素对结构体中的count进行++即可。 如下图,数组的下标与字符的ASCII码值一一对应: 在构建哈夫曼树时,直接调用之前写过的创建树的方式即可,但需要注意一点: 哈夫曼树每个节点类型为结构体类型,因此在定义结构体的地方,需要对运算符(+,>,!=,==)进行重载,让编译器知道count之间的比较方式。 下图是创建Huffman树时需要注意的点: 我们现在已经有了根据频次信息创建的Huffman树,现在只需要遍历Huffman树来获取编码即可。对于编码的获取方式,可以从根节点遍历到叶子节点来获取,也可以从叶子节点向上找到根节点获取。 这里采用第二种方式来获取编码,需要给节点中增加双亲的指针域,让Huffman树的表示方法为孩子双亲表示法。通过这种方式获取的编码最后需要进行逆置才是最终结果,下图是获取编码后的结果,与期望的编码相同: 前三个步骤进行完之后,只需改写文件即可。还是需要循环读取文件内容,采取位操作按位或的方式将Huffman编码放置到比特位当中。 步骤:1.定义ch = 0,先让ch左移一位,再判断Huffman编码的每个比特位是否为1,为1则让ch与Huffman编码为1比特位进行或操作,这样就能将文件按照编码的方式改写。 最终改写结果: 解压缩过程与压缩过程相反,需要将压缩文件还原成原文件。但使用解压缩进行还原是需要条件的,不能凭空还原,需要根据原文件信息进行。 因此,在压缩过程中就需要将解压缩需要的信息重新保存一下。解压缩还原有很多种方法,但每种方法的还原效率不一样,这里选择用哈夫曼树的方式来进行还原:通过原文件字节出现的频次信息,还原出一棵哈夫曼树,再从根节点遍历,读取压缩数据,当读到0往左子树走,读到1往右子树走,直到走到叶子节点的位置即还原了原数据,再回到根节点循环遍历压缩数据。 在解压缩过程中用到的信息: 1.原文件后缀 2.统计频次信息的总行数(方便对数据进行操作) 3.获取原文件字节出现的频次信息 4.压缩数据 往文件中写入信息后: 有了这些信息,就可以对哈夫曼树进行恢复,继续进行解压缩的过程了,恢复哈夫曼树的过程相对简单,基于之前写过的构建哈夫曼树的方法,只需对文件中压缩信息做相对应的处理 3.恢复原文件(解压缩)解压缩过程就是:根据压缩数据来遍历恢复的哈夫曼树,压缩数据为1就往右子树走,为0就往左子树走,知道走到叶子节点。通过以上所有步骤就能够完成压缩与解压缩的所有过程了。 这里还有一个小问题,压缩方法不能处理文件中的汉字,因为汉字是采用UTF-8编码进行编排的,它的编码不在ASCII码表中。因此需要将所有的char类型改变为unsigned char类型!!! 下面为原文件与解压缩之后的结果: 以上就是今天要讲的内容,本文简单介绍了基于哈夫曼编码的文件压缩方法,我收获很多。在写代码途中,不免遇到很多bug调试半天还解决不了,但最终还是解决了出来,这也是写代码必经的一个过程。 以下是我总结完成过程中注意的一些问题: ①创建哈夫曼树时,使用优先级队列来保存字符出现的频次信息时,优先级队列的比较方式需要自己进行给出,使用仿函数的方法让比较方式为每个节点中的权值 ②在使用结构体来创建哈夫曼树时,需要对+,>,==,!=,进行重载,重载的目的:让编译器知道权值中的count之间的比较方式 ③在构建哈夫曼树时,发现其他节点构建正确,但是值域为1的节点不是叶子节点,是因为数组中还存放着许多字符出现次数为0的节点,需要进行过滤,设置第三个参数invalid来过滤权值为0的节点 ④再次读取文件时,需要将文件指针的位置重置到文件头部,使用fseek函数或者rewind函数 ⑤在解压缩时,不一定是8个比特位都需要解压缩,因此需要增加判定条件,只要解压缩后的字节数与原文件相等就停止解压缩 ⑥压缩和解压缩代码写完后,需要讲char类型改成unsigned char类型,因为原文件可能出现汉字,汉字对应的是utf-8编码,不在ASCII码表中 ⑦在测试多行数据压缩时,又出现了问题,原因是当读取到\n换行使,并没有将换行所在的数据GetLine,因此解压缩时数据少了一行。 ⑧在进行大量数据测试时出现问题,发现解压缩一部分内容就停止了,部分数据丢失,但已经解压缩的部分内容与原文件一样。原因是解压缩文件是二进制文件(即压缩结果是二进制数字),二进制文件中可能会 出现-1(FF),当为-1时就默认读到了文件末尾就结束解压缩过程了。 改进方法是: 将所有打开文件(fopen)中文件的读写方式由"r",“w"改为二进制读写式"rb”“wb” ⑨经过测试,发现对不同的文件(文本文件,二进制文件),图片,视频都能够进行压缩,但哈夫曼编码的文件压缩对不同种类的压缩率是不同的。 对于txt/c/cpp类后缀的文本文件,压缩率较高在30%~50% 对于png/jpg类后缀的图片,压缩率一般在70%~90% 对于exe类后缀的可执行文件,压缩率较低在80%~90% ⑩在对文件进行多次压缩时,压缩结果的大小不是每次会减少,有一个限度。 同时,哈夫曼编码的压缩方法也是可能会出现压缩结果变大的可能性。当文件中字节的种类偏多,并且字节出现的次数比较平均的情况下,压缩效率就会变差,因为统计字节出现的频次信息时,各个字节出现的次数差不多,构建出来的哈夫曼树就接近平衡二叉树,效果就会不理想。 当然,也会出现压缩后文件变大的情况:当哈夫曼编码的平均长度大于8字节时,压缩文件就会变大 |

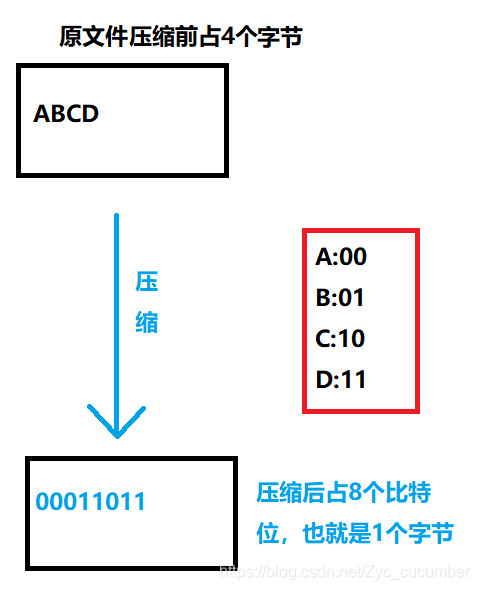 使用等长的编码来对文件进程改写,不一定能达到最好的压缩率。 但使用不等长的编码来改写文件的话,压缩率往往会更好,这种方式是使用出现频率高的字符采用更短的编码进行表示。 下图是使用了不等长编码方法:
使用等长的编码来对文件进程改写,不一定能达到最好的压缩率。 但使用不等长的编码来改写文件的话,压缩率往往会更好,这种方式是使用出现频率高的字符采用更短的编码进行表示。 下图是使用了不等长编码方法: 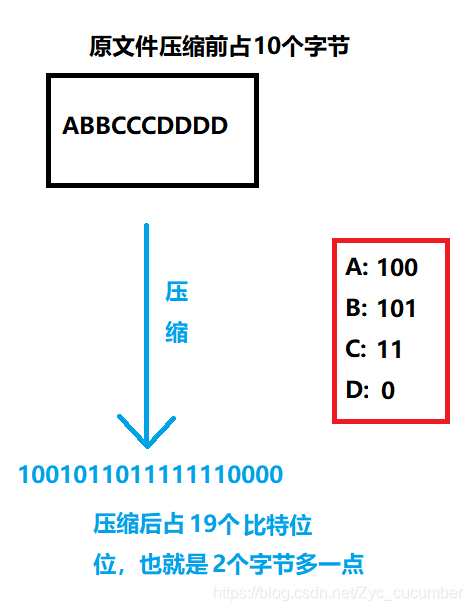
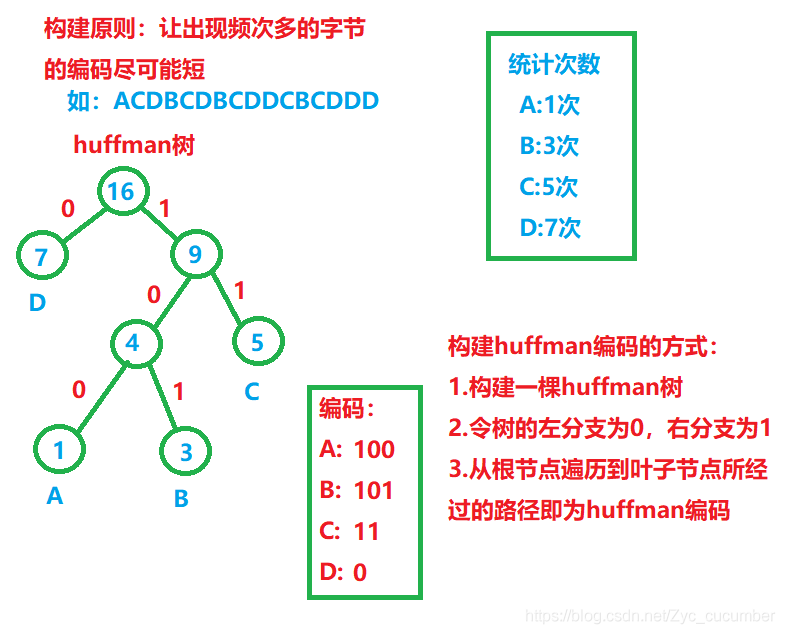
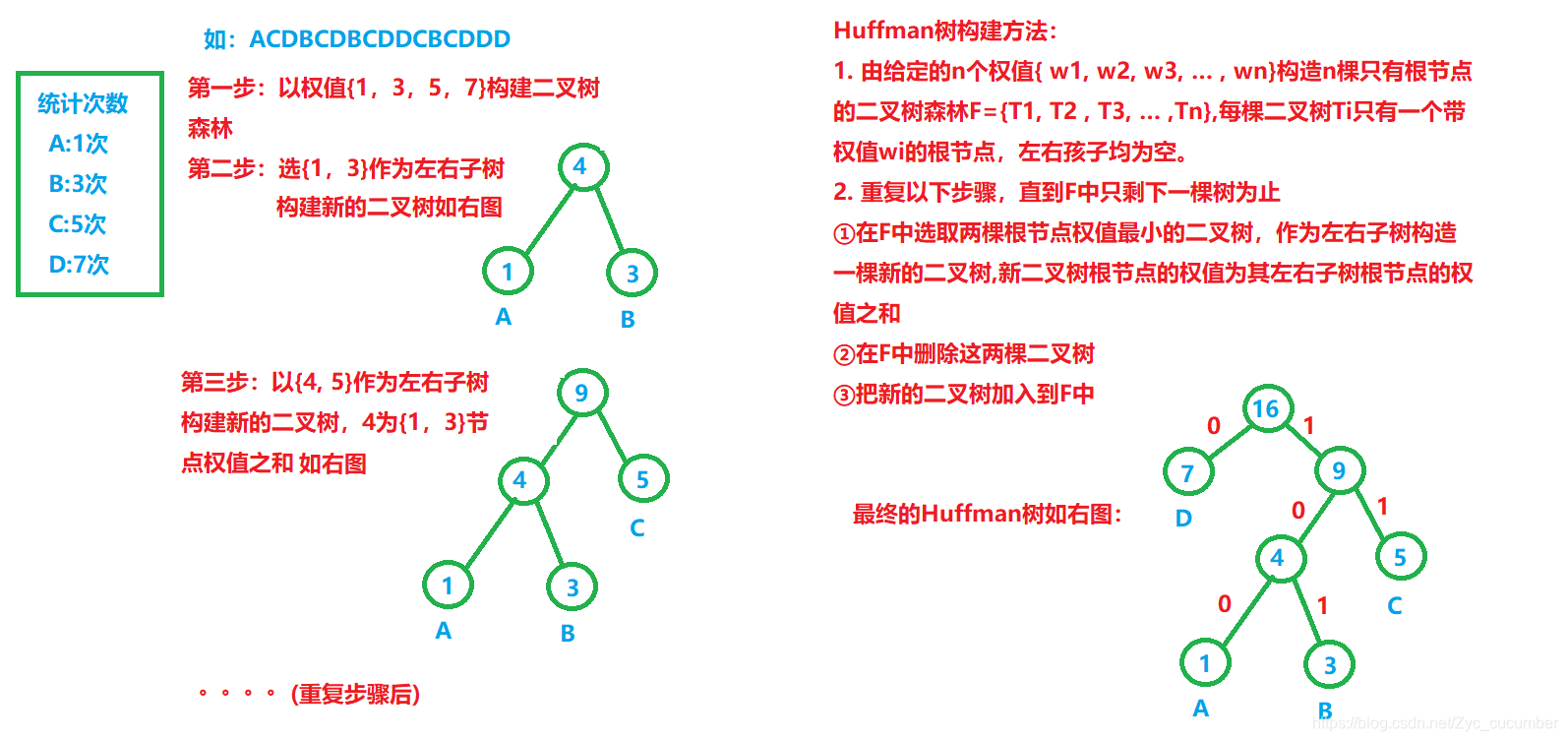 关于具体哈夫曼树的创建代码,请参考: (https://gitee.com/zhang-yucheng329/c-file-compression)
关于具体哈夫曼树的创建代码,请参考: (https://gitee.com/zhang-yucheng329/c-file-compression)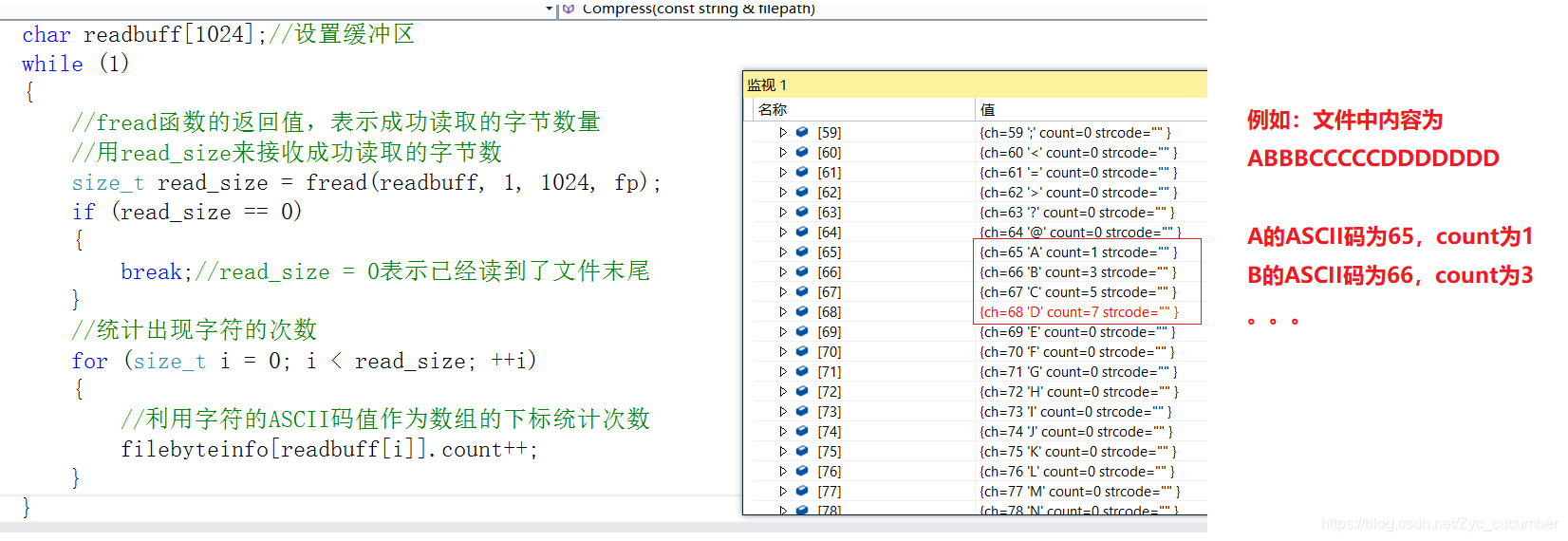
 关于具体文件压缩的代码,请参考: (https://gitee.com/zhang-yucheng329/c-file-compression/tree/master/Compress)
关于具体文件压缩的代码,请参考: (https://gitee.com/zhang-yucheng329/c-file-compression/tree/master/Compress)
 关于具体解压缩的代码(最终代码),请参考: (https://gitee.com/zhang-yucheng329/c-file-compression)
关于具体解压缩的代码(最终代码),请参考: (https://gitee.com/zhang-yucheng329/c-file-compression)【本文地址】
今日新闻 |
推荐新闻 |