图像的传统特征和深度特征介绍及其提取方法 |
您所在的位置:网站首页 › 什么是深度感知 › 图像的传统特征和深度特征介绍及其提取方法 |
图像的传统特征和深度特征介绍及其提取方法
|
图像特征及提取
1. 传统图像特征1.1 统计特征---穿透数、不变矩阵、粗网格、方向线素1.2 纹理特征---LBP, Gabor, HOG, GLCM
2. 图像深度特征
1. 传统图像特征
1.1 统计特征—穿透数、不变矩阵、粗网格、方向线素
笔画穿透数(stroke penetration)是一种全局统计特征(global statistical feature),它描述字符的各部分笔划的疏密程度,能够提供比较完整的字符信息。在网格字符图像中,从不同方向进行扫描。根据轮廓交叉(silhouette intersection)的数量,定义穿透数特征函数H。选取水平方向和垂直方向,在每个方向上选取n(n=16)个特征值,然后就可获取到 2 n 2n 2n个特征向量函数 H , H H,H H,H由以下公式定义: H = ( h 11 , h 12 , . . . , h 1 n , h 21 , h 22 , . . . , h 2 n ) , n = ( 1 , 2 , . . . , 16 ) − − − − ( 1 ) H=(h_{11},h_{12},...,h_{1n},h_{21},h_{22},...,h_{2n}), n=(1,2,...,16) ----(1) H=(h11,h12,...,h1n,h21,h22,...,h2n),n=(1,2,...,16)−−−−(1) 假设字符的水平和垂直坐标被规范化为 1 ∼ p 1∼p 1∼p,设H函数的每个初值为 p n = p / n p_n=p/n pn=p/n ,则集合H中的 h n h_n hn 表示为: h n = n / p ∗ ∑ t = 1 p n h ( k + p s − 1 ) − − − − ( 2 ) h_n=n/p*\sum_{t=1}^{p_n}h(k+p_s-1)----(2) hn=n/p∗t=1∑pnh(k+ps−1)−−−−(2) 其中 s = 1 , 2 , t = 1 , 2 , . . . , n s=1,2, t=1,2,...,n s=1,2,t=1,2,...,n, h n h_n hn为字符穿透数特征向量。 不变矩阵(moment)是全局统计特征,其在图像检索(image retrieval)和图像识别(image recognition)中得到了广泛的应用。由于图像区域的某些矩值对于平移(translation)、旋转(rotate)、缩放(scale)等几何操作是不可改变的,因此矩值的表示方法在模式识别中非常重要。对于二维连续函数(2D continuous function) f ( x , y ) , f(x,y), f(x,y),阶矩(order moment)(j+k)定义如下: m j k = ∫ − ∞ + ∞ ∫ − ∞ + ∞ x j y k f ( x , y ) d x d y − − − − ( 3 ) m_{jk}=\int_{-\infty}^{+\infty} \int_{-\infty}^{+\infty} x^jy^kf(x,y)d_xd_y ----(3) mjk=∫−∞+∞∫−∞+∞xjykf(x,y)dxdy−−−−(3) 其中 j 和 k j和k j和k都是非负整数,因此得到了一个无限的矩集。为了描述字符图像的形状,在函数f(x,y)中假设字符的函数值为1,背景函数值为0。所以该函数只反映字符对象的形状,忽略灰度级细节。参数j+k称为矩序。零阶矩(zeroth order moment)则是字符对象的面积,表示为 m 00 = ∫ − ∞ + ∞ ∫ − ∞ + ∞ f ( x , y ) d x d y − − − − ( 4 ) m_{00}=\int_{-\infty}^{+\infty} \int_{-\infty}^{+\infty} f(x,y)d_xd_y ----(4) m00=∫−∞+∞∫−∞+∞f(x,y)dxdy−−−−(4) 当满足条件 j = 1 , k = 0 时 j=1,k=0时 j=1,k=0时, m 10 m_{10} m10为二值字符图像中所有点的水平坐标x之和。同样, m 01 m_{01} m01 是图像中所有点的垂直坐标y之和。 设 ( x ‾ , y ‾ ) ( x ‾ = m 10 m 00 , y ‾ = m 01 m 00 ) (\overline x,\overline y)(\overline x=\frac {m_{10}} {m_{00}},\overline y= \frac {m_{01}} {m_{00}}) (x,y)(x=m00m10,y=m00m01)为二值字符图像的质心坐标,则中心矩(central moment)定义为 μ j k = ∫ − ∞ + ∞ ∫ − ∞ + ∞ ( x − x ‾ ) j ( y − y ‾ ) k f ( x , y ) d x d y − − − − ( 5 ) \mu_{jk}=\int_{-\infty}^{+\infty} \int_{-\infty}^{+\infty} {(x-\overline x)^j}{(y-\overline y)^k}f(x,y)d_xd_y ----(5) μjk=∫−∞+∞∫−∞+∞(x−x)j(y−y)kf(x,y)dxdy−−−−(5) 粗网格(grid pixels)特征是局部统计特征,其反映了图像形状的分布情况。粗网格统计值即为字符图像中每个网格中黑色像素所占的百分比,每个网格分别反映字符的某一部分特征。对样本进行预处理后,将字符划分为8*8的网格图像,每个坐标的像素点
g
(
i
,
j
)
g(i,j)
g(i,j)可以表示为
g
(
i
,
j
)
=
{
1
,
b
l
a
c
k
0
,
w
h
i
t
e
}
−
−
−
−
(
6
)
g(i,j)=\{_{1,black} ^{0, white}\}----(6)
g(i,j)={1,black0,white}−−−−(6) 方向线素(direction line element)是一种局部统计特征(local statistical feature),即轮廓分解后的网格方向特征,在中文和英文等识别中表现的效果较好。方向线素特征描述笔画在不同方向上的贡献度,笔画方向量化为如下图左侧所示的4个方向,分别是垂直,水平和倾斜正负 4 5 o 45^o 45o。 对于3*3网格中的中心黑色像素,可以观察到两种情况:一种是分配了一种线元素(下图(a)-图(d));另一种是三个黑色像素相连,但分配了两种类型的线元素(图(e)-图(l))。例如,在图(f)中,同时分配
4
5
o
45^o
45o的线元素和垂直线元素,以此量化不同方向的线元素。 为了避免受到字符图像位置改变的影响,将对每个区域分配权重。对于16×16像素的子区域,每个子区域分配的权重可表示为 Local Binary Pattern(LBP), Gabor, Histogram of Oriented Gradient(HOG), 灰度共生矩阵(Gray Level CO-Occurrence Matrix, GLCM) LBP:可以看之前的这篇博客,以及本篇的代码公开在GitHub。 Gabor : 1946年提出Gabor滤波器,可以在频域的不同尺度、不同方向上提取相关的特征。对于图像的边缘敏感,能够提供良好的方向选择和尺度选择特性,Gabor滤波器的这一性质,使得其在视觉领域中经常被用来作图像的预处理。 Gabor滤波器示意图,4种角度6种方向: HOG:2005年 CVPR 行人识别。思想为局部目标的表象和形状能够被梯度或边缘的方向密度分布很好地描述,统计边缘梯度信息。 步骤:1.预处理 gama矫正 灰度化等 2. 计算梯度 计算图像横纵(取绝对值)方向的梯度,并据此得出每个像素位置的梯度方向 θ \theta θ及梯度强度 g g g。 θ = a r c t a n g x g y g = g x 2 + g y 2 \theta=arctan \frac {g_x} {g_y} \qquad g=\sqrt{g_x ^2 +g_y ^2} θ=arctangygxg=gx2+gy2 3. 计算梯度直方图 按照梯度的方向和强度,将cell中对应的像素划分至0~180度的9个bins中,得到9维的向量。 4. 向上合并 四个cell进行归一化 HOG Python实现: from skimage.feature import hog, local_binary_pattern import cv2 img = cv2.imread('/1.jpg', cv2.IMREAD_GRAYSCALE) img = cv2.resize(img, (512, 512)) # gray = rgb2gray(image) / 255.0 fd = hog(img, orientations=12, block_norm='L1', pixels_per_cell=[10, 10], cells_per_block=[4, 4], visualize=False, transform_sqrt=True) print(fd.shape) radius = 3 n_point = radius * 16 lbp = local_binary_pattern(img,n_point,radius,'default') cv2.imshow('img', lbp) cv2.waitKey(0) import cv2 import numpy as np import math import matplotlib.pyplot as plt class Hog_descriptor(): def __init__(self, img, cell_size=16, bin_size=8): self.img = img self.img = np.sqrt(img / np.max(img)) self.img = img * 255 self.cell_size = cell_size self.bin_size = bin_size self.angle_unit = 360 // self.bin_size assert type(self.bin_size) == int, "bin_size should be integer," assert type(self.cell_size) == int, "cell_size should be integer," assert type(self.angle_unit) == int, "angle_unit should be divisible by 360" def extract(self): height, width = self.img.shape print(height / self.cell_size) gradient_magnitude, gradient_angle = self.global_gradient() gradient_magnitude = abs(gradient_magnitude) cell_gradient_vector = np.zeros((height // self.cell_size, width // self.cell_size, self.bin_size)) for i in range(cell_gradient_vector.shape[0]): for j in range(cell_gradient_vector.shape[1]): cell_magnitude = gradient_magnitude[i * self.cell_size:(i + 1) * self.cell_size, j * self.cell_size:(j + 1) * self.cell_size] cell_angle = gradient_angle[i * self.cell_size:(i + 1) * self.cell_size, j * self.cell_size:(j + 1) * self.cell_size] cell_gradient_vector[i][j] = self.cell_gradient(cell_magnitude, cell_angle) hog_image = self.render_gradient(np.zeros([height, width]), cell_gradient_vector) hog_vector = [] for i in range(cell_gradient_vector.shape[0] - 1): for j in range(cell_gradient_vector.shape[1] - 1): block_vector = [] block_vector.extend(cell_gradient_vector[i][j]) block_vector.extend(cell_gradient_vector[i][j + 1]) block_vector.extend(cell_gradient_vector[i + 1][j]) block_vector.extend(cell_gradient_vector[i + 1][j + 1]) mag = lambda vector: math.sqrt(sum(i ** 2 for i in vector)) magnitude = mag(block_vector) if magnitude != 0: normalize = lambda block_vector, magnitude: [element / magnitude for element in block_vector] block_vector = normalize(block_vector, magnitude) hog_vector.append(block_vector) return hog_vector, hog_image def global_gradient(self): gradient_values_x = cv2.Sobel(self.img, cv2.CV_64F, 1, 0, ksize=5) gradient_values_y = cv2.Sobel(self.img, cv2.CV_64F, 0, 1, ksize=5) gradient_magnitude = cv2.addWeighted(gradient_values_x, 0.5, gradient_values_y, 0.5, 0) gradient_angle = cv2.phase(gradient_values_x, gradient_values_y, angleInDegrees=True) return gradient_magnitude, gradient_angle def cell_gradient(self, cell_magnitude, cell_angle): orientation_centers = [0] * self.bin_size for i in range(cell_magnitude.shape[0]): for j in range(cell_magnitude.shape[1]): gradient_strength = cell_magnitude[i][j] gradient_angle = cell_angle[i][j] min_angle, max_angle, mod = self.get_closest_bins(gradient_angle) orientation_centers[min_angle] += (gradient_strength * (1 - (mod / self.angle_unit))) orientation_centers[max_angle] += (gradient_strength * (mod / self.angle_unit)) return orientation_centers def get_closest_bins(self, gradient_angle): idx = int(gradient_angle / self.angle_unit) mod = gradient_angle % self.angle_unit return idx, (idx + 1) % self.bin_size, mod def render_gradient(self, image, cell_gradient): cell_width = self.cell_size / 2 max_mag = np.array(cell_gradient).max() for x in range(cell_gradient.shape[0]): for y in range(cell_gradient.shape[1]): cell_grad = cell_gradient[x][y] cell_grad /= max_mag angle = 0 angle_gap = self.angle_unit for magnitude in cell_grad: angle_radian = math.radians(angle) x1 = int(x * self.cell_size + magnitude * cell_width * math.cos(angle_radian)) y1 = int(y * self.cell_size + magnitude * cell_width * math.sin(angle_radian)) x2 = int(x * self.cell_size - magnitude * cell_width * math.cos(angle_radian)) y2 = int(y * self.cell_size - magnitude * cell_width * math.sin(angle_radian)) cv2.line(image, (y1, x1), (y2, x2), int(255 * math.sqrt(magnitude))) angle += angle_gap return image img = cv2.imread('/1.jpg', cv2.IMREAD_GRAYSCALE) img = cv2.resize(img, (512, 512)) hog = Hog_descriptor(img, cell_size=8, bin_size=8) vector, image = hog.extract() print(np.array(vector).shape) plt.imshow(image, cmap=plt.cm.gray) plt.show() cv2.imshow('img', image) cv2.waitKey(0)GLCM:1973年Haralick等人提出,是一种通过研究灰度的空间相关特性来描述纹理的常用方法,由于纹理是由灰度分布在空间位置上反复出现而形成的,因而在图像空间中相隔某距离的两像素之间会存在一定的灰度关系,即图像中灰度的空间相关特性。 定义:从灰度为 i 的像素点出发,距离(dx,dy)的另一像素点灰度为 j 的的概率。 灰度直方图是对图像上单个像素具有某个灰度进行统计的结果,而灰度共生矩阵是对图像上保持某距离的两像素分别具有某灰度的状况进行统计得到的。 取图像(N×N)中任意一点(x,y)及偏离它的另一点(x+a,y+b),设该点对的灰度值为 (g1,g2)。令点(x,y) 在图像上移动,则会得到多个(g1,g2)值,设灰度值的级数为 k,则(g1,g2) 的组合共有
k
∗
k
k*k
k∗k种。对于整幅图像,统计出每一种 (g1,g2)值出现的次数,然后排列成一个方阵,再用(g1,g2) 出现的总次数将它们归一化为出现的概率
P
(
g
1
,
g
2
)
P_{(g1,g2)}
P(g1,g2) ,这样的方阵称为灰度共生矩阵。 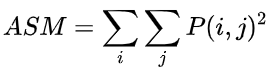 熵(Entropy, ENT),表示图像中纹理的非均匀程度或复杂程度。熵是图像所具有的信息量的度量,纹理信息也属于图像的信息,是一个随机性的度量。当共生矩阵中所有元素有最大的随机性、空间共生矩阵中所有值几乎相等时,共生矩阵中元素分散分布时,熵较大。 熵(Entropy, ENT),表示图像中纹理的非均匀程度或复杂程度。熵是图像所具有的信息量的度量,纹理信息也属于图像的信息,是一个随机性的度量。当共生矩阵中所有元素有最大的随机性、空间共生矩阵中所有值几乎相等时,共生矩阵中元素分散分布时,熵较大。 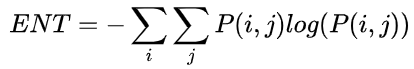 反差分矩阵(Inverse Differential Moment, IDM),反映图像纹理的同质性,度量图像纹理局部变化的多少。 反差分矩阵(Inverse Differential Moment, IDM),反映图像纹理的同质性,度量图像纹理局部变化的多少。 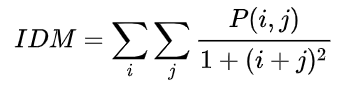 Python 代码实现:
def get_inputs(input): # s为图像路径
# 得到共生矩阵,参数:图像矩阵,距离,方向,灰度级别,是否对称,是否标准化
# glcm = greycomatrix(input, [16, 32, 48, 64, 80, 96, 112, 128, 144, 160], [0, np.pi / 4, np.pi / 2, np.pi * 3 / 4], 256, symmetric=True, normed=True)
glcm = greycomatrix(input, [1], [0, np.pi / 4, np.pi / 2, np.pi * 3 / 4], 256, symmetric=True, normed=True)
# 得到共生矩阵统计值,http://tonysyu.github.io/scikit-image/api/skimage.feature.html#skimage.feature.greycoprops
#temp = greycoprops(glcm,'contrast')
#temp = greycoprops(glcm,'dissimilarity')
#temp = greycoprops(glcm, 'homogeneity')
#temp = greycoprops(glcm, 'correlation')
temp = greycoprops(glcm, 'energy')
print(temp)
#temp = greycoprops(glcm, 'ASM')
# temp1 = np.array(temp)
# temp2 = list(chain.from_iterable(temp1))
return temp
if __name__ == '__main__':
filters = build_filters()
print(len(filters))
a = 0
contrast = np.zeros((40000,40), dtype=np.float32)
dissimilarity = np.zeros((40000,40), dtype=np.float32)
homogeneity = np.zeros((40000,40), dtype=np.float32)
ASM = np.zeros((40000,40), dtype=np.float32)
for filename in os.listdir('D:/'):
img = cv2.imread('D:/' + filename, 0)
print(filename)
for i in range(len(filters)):
accum = np.zeros_like(img)
for kern in filters[i]:
fimg = cv2.filter2D(img, cv2.CV_8UC1, kern)
accum = np.maximum(accum, fimg, accum)
# print(i)
# cv2.imwrite(str(i) + ".jpg", accum)
contrast1, dissimilarity1, homogeneity1, ASM1 = get_inputs(accum)
# print(contrast, np.mean(contrast))
# energy.append(np.mean(temp))
# for i in range(40):
ASM[a, i] = np.mean(ASM1)
contrast[a, i] = np.mean(contrast1)
dissimilarity[a, i] = np.mean(dissimilarity1)
homogeneity[a, i] = np.mean(homogeneity1)
a += 1
contrast = np.array(contrast)
dissimilarity = np.array(dissimilarity)
homogeneity = np.array(homogeneity)
ASM = np.array(ASM)
# energy = list(chain.from_iterable(energy))
# print('mena:', mean)
contrast = pd.DataFrame(data=contrast)
contrast.to_csv("./feature-/contrast.csv", encoding='utf-8', index=False)
dissimilarity = pd.DataFrame(data=dissimilarity)
dissimilarity.to_csv("./feature-/dissimilarity.csv", encoding='utf-8', index=False)
homogeneity = pd.DataFrame(data=homogeneity)
homogeneity.to_csv("./feature-/homogeneity.csv", encoding='utf-8', index=False)
ASM = pd.DataFrame(data=ASM)
ASM.to_csv("./feature-/ASM.csv", encoding='utf-8', index=False) Python 代码实现:
def get_inputs(input): # s为图像路径
# 得到共生矩阵,参数:图像矩阵,距离,方向,灰度级别,是否对称,是否标准化
# glcm = greycomatrix(input, [16, 32, 48, 64, 80, 96, 112, 128, 144, 160], [0, np.pi / 4, np.pi / 2, np.pi * 3 / 4], 256, symmetric=True, normed=True)
glcm = greycomatrix(input, [1], [0, np.pi / 4, np.pi / 2, np.pi * 3 / 4], 256, symmetric=True, normed=True)
# 得到共生矩阵统计值,http://tonysyu.github.io/scikit-image/api/skimage.feature.html#skimage.feature.greycoprops
#temp = greycoprops(glcm,'contrast')
#temp = greycoprops(glcm,'dissimilarity')
#temp = greycoprops(glcm, 'homogeneity')
#temp = greycoprops(glcm, 'correlation')
temp = greycoprops(glcm, 'energy')
print(temp)
#temp = greycoprops(glcm, 'ASM')
# temp1 = np.array(temp)
# temp2 = list(chain.from_iterable(temp1))
return temp
if __name__ == '__main__':
filters = build_filters()
print(len(filters))
a = 0
contrast = np.zeros((40000,40), dtype=np.float32)
dissimilarity = np.zeros((40000,40), dtype=np.float32)
homogeneity = np.zeros((40000,40), dtype=np.float32)
ASM = np.zeros((40000,40), dtype=np.float32)
for filename in os.listdir('D:/'):
img = cv2.imread('D:/' + filename, 0)
print(filename)
for i in range(len(filters)):
accum = np.zeros_like(img)
for kern in filters[i]:
fimg = cv2.filter2D(img, cv2.CV_8UC1, kern)
accum = np.maximum(accum, fimg, accum)
# print(i)
# cv2.imwrite(str(i) + ".jpg", accum)
contrast1, dissimilarity1, homogeneity1, ASM1 = get_inputs(accum)
# print(contrast, np.mean(contrast))
# energy.append(np.mean(temp))
# for i in range(40):
ASM[a, i] = np.mean(ASM1)
contrast[a, i] = np.mean(contrast1)
dissimilarity[a, i] = np.mean(dissimilarity1)
homogeneity[a, i] = np.mean(homogeneity1)
a += 1
contrast = np.array(contrast)
dissimilarity = np.array(dissimilarity)
homogeneity = np.array(homogeneity)
ASM = np.array(ASM)
# energy = list(chain.from_iterable(energy))
# print('mena:', mean)
contrast = pd.DataFrame(data=contrast)
contrast.to_csv("./feature-/contrast.csv", encoding='utf-8', index=False)
dissimilarity = pd.DataFrame(data=dissimilarity)
dissimilarity.to_csv("./feature-/dissimilarity.csv", encoding='utf-8', index=False)
homogeneity = pd.DataFrame(data=homogeneity)
homogeneity.to_csv("./feature-/homogeneity.csv", encoding='utf-8', index=False)
ASM = pd.DataFrame(data=ASM)
ASM.to_csv("./feature-/ASM.csv", encoding='utf-8', index=False)
设计神经网络模型来挖掘图像更深、更为抽象的特征。CNN随着深度的增加时所表达的高级语义信息比较强,而浅层的卷积结构对物体的轮廓刻画比较明显 下图,原图经卷积后随深度增加,特征随之抽象。代码公开在GitHub |
 对每个网格内的前景像素进行统计,可得到64维粗网格特征向量。
对每个网格内的前景像素进行统计,可得到64维粗网格特征向量。 将字符图像划分为具有16×16像素的7×7子区域,然后将每个子区域分成4个嵌套块,表示为A、B、C和D,尺寸分别为16×16、12×12、8×8和4×4。对于每个子区域,定义一个四维向量
X
=
(
x
1
,
x
2
,
x
3
,
x
4
)
T
X=(x_1,x_2,x_3,x_4)^T
X=(x1,x2,x3,x4)T ,其中
x
1
x_1
x1、
x
2
x_2
x2 、
x
3
x_3
x3 和
x
4
x_4
x4分别表示四个方向上的方向线素的数量,四个方向包括
0
o
、
4
5
o
、
9
0
o
和
13
5
o
。
0^o、45^o、90^o和135^o。
0o、45o、90o和135o。
将字符图像划分为具有16×16像素的7×7子区域,然后将每个子区域分成4个嵌套块,表示为A、B、C和D,尺寸分别为16×16、12×12、8×8和4×4。对于每个子区域,定义一个四维向量
X
=
(
x
1
,
x
2
,
x
3
,
x
4
)
T
X=(x_1,x_2,x_3,x_4)^T
X=(x1,x2,x3,x4)T ,其中
x
1
x_1
x1、
x
2
x_2
x2 、
x
3
x_3
x3 和
x
4
x_4
x4分别表示四个方向上的方向线素的数量,四个方向包括
0
o
、
4
5
o
、
9
0
o
和
13
5
o
。
0^o、45^o、90^o和135^o。
0o、45o、90o和135o。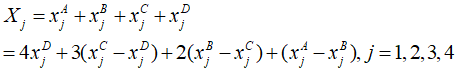 其中,
x
j
A
x_j ^A
xjA 、
x
j
B
x_j ^B
xjB 、
x
j
C
x_j ^C
xjC 、
x
j
D
x_j ^D
xjD 分别表示区域A、区域B、区域C、区域D中某个方向上的方向线素的数量。每个子区域可以得到一个四维特征向量,每个字符图像得到7×7×4=196维方向线素特征向量。
其中,
x
j
A
x_j ^A
xjA 、
x
j
B
x_j ^B
xjB 、
x
j
C
x_j ^C
xjC 、
x
j
D
x_j ^D
xjD 分别表示区域A、区域B、区域C、区域D中某个方向上的方向线素的数量。每个子区域可以得到一个四维特征向量,每个字符图像得到7×7×4=196维方向线素特征向量。 以及生成的24张滤波图像
以及生成的24张滤波图像 
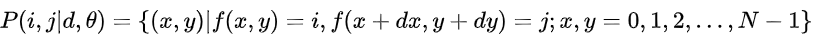 其中,d:用像素数量表示的相对距离;
θ
\theta
θ : 一般考虑四个方向,分别为 0°,45°,90°,135° ;
i
,
j
=
0
,
1
,
2
,
.
.
.
,
L
−
1
i, j =0,1,2,...,L-1
i,j=0,1,2,...,L−1 ;(x,y)为图像中的像素坐标,L为图像灰度级的数目。可以简单理解为灰度图像中某种形状的像素对,在图像中出现的次数。
其中,d:用像素数量表示的相对距离;
θ
\theta
θ : 一般考虑四个方向,分别为 0°,45°,90°,135° ;
i
,
j
=
0
,
1
,
2
,
.
.
.
,
L
−
1
i, j =0,1,2,...,L-1
i,j=0,1,2,...,L−1 ;(x,y)为图像中的像素坐标,L为图像灰度级的数目。可以简单理解为灰度图像中某种形状的像素对,在图像中出现的次数。

【本文地址】
今日新闻 |
推荐新闻 |