开放信息抽取(OIE)系统(一) |
您所在的位置:网站首页 › 什么是开放式网络 › 开放信息抽取(OIE)系统(一) |
开放信息抽取(OIE)系统(一)
|
开放信息抽取(OIE)(一)——概述
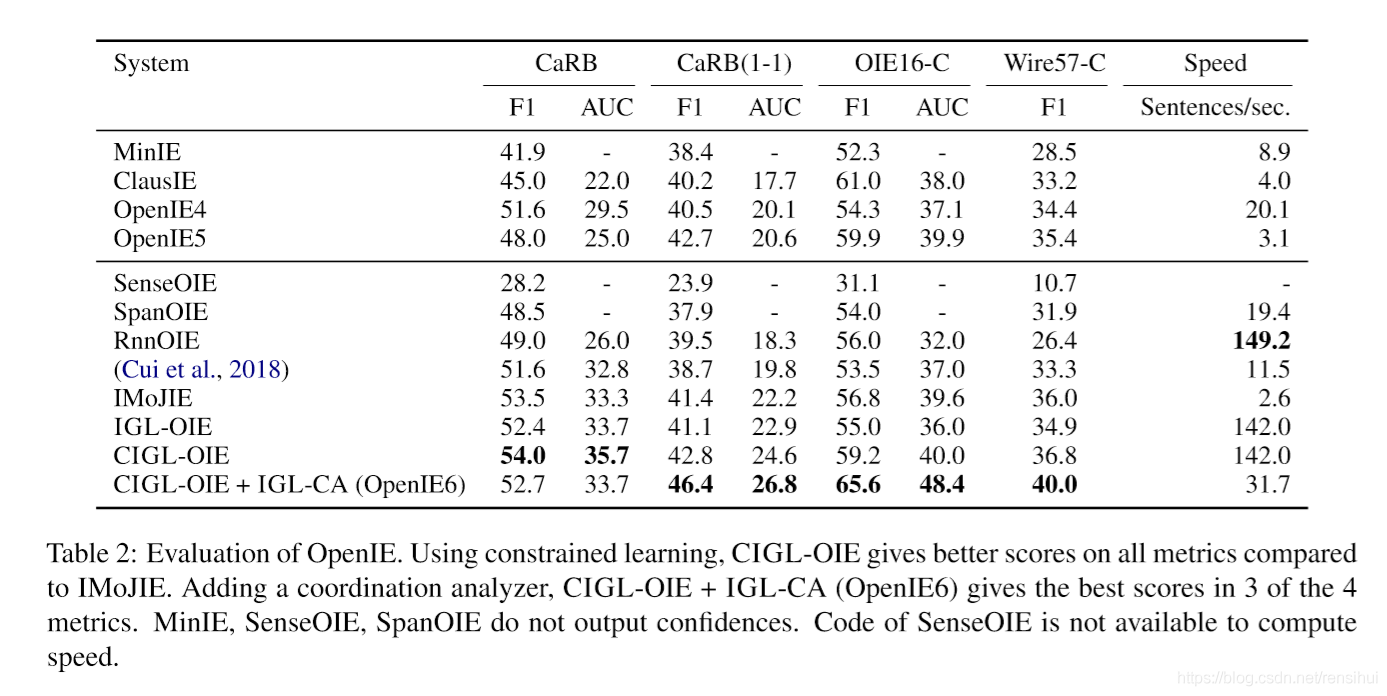
开放信息抽取(OIE)是信息抽取的一种全新的范式,主要思想是减少人工参与,无监督地进行信息抽取,抽取那些实体、关系未定义地情形。 早期,10年代,即机器学习时代等,经典的开放信息抽取系统,一般是利用发展较为成熟、应用较为广泛的、通用的词性标注、依存句法、成分句法、语义角色标注等技术,抽取主谓宾等三元组。 到了20年代,主要是用到早期系统抽取的结果进行有监督的学习,来进行抽取,一般是比较大的语料库。 一、概述 1.1 开发域无/弱监督信息抽取开放域无/弱监督信息抽取一般存在三种方式,即自助法(Bootstrap)、远程监督(Distant-Supervision)、开放信息抽取(OpenIE)等。 开放信息抽取使用通用NLP工具(词性、依存句法、语义角色、从句),可以在无监督的条件下从句子中抽取三元组,但是无法定义关系类别; 远程监督方法利用已有的大型通用知识图谱的三元组进行半监督学习。存在强假设一对实体体中只存在一种关系问题、语义漂移问题; 自助法是把一种关系的少量实体对,作为种子,发现该关系的更多新实体对。存在语义漂移问题、迭代法查准率会不断降低。 二、信息抽取 2.1 定义 信息抽取( IE,Information Extraction)是把文本里包含的信息进行结构化处理,变成表格一样的组织形式。输入信息抽取系统的是原始文本,输出的是固定格式的信息点。信息点从各种各样的文档中被抽取出来,然后以统一的形式集成在一起。这就是信息抽取的主要任务。信息以统一的形式集成在一起的好处是方便检查和比较。 信息抽取技术并不试图全面理解整篇文档,只是对文档中包含相关信息的部分进行分析。至于哪些信息是相关的,那将由系统设计时定下的领域范围而定。 信息检索(IR)和信息抽取(IE)的区别:IR的目的是根用户的查询请求从文档库中找出相关的文档, 用户必须从找到的文档中翻阅自己所要的信息。就其目的而言,IR和IE的不同可表达如下:IR从文档库中检索相关的文档,而IE是从文档中取出相关信息点。这两种技术因此是互补的。若结合起来可以为文本处理提供强大的工具。 IR和IE不单在目的上不同,而且使用的技术路线也不同。部分原因是因为其目的差异,另外还因为它们的发展历史不同。多数IE的研究是从以规则为基础的计算语言学和自然语言处理技术发源的。而IR则更多地受到信息理论、概率理论和统计学的影响。 2.2 任务 信息抽取中的信息通常指的是实体(entity)、关系(relation)和事件(event)等,也就是定义了以下任务: 实体任务: 实体抽取、实体链指、实体消歧、属性抽取;关系任务:关系预测、三元组抽取、实体关系抽取;事件任务:事件抽取、触发词识别、事件类型分类、论元识别和角色分类。 2.3 应用 由于能从自然语言中抽取出信息框架和用户感兴趣的事实信息,无论是在知识图谱、信息检索、问答系统,还是在情感分析、文本挖掘中,信息抽取都有广泛应用。 三. 开放信息抽取 信息抽取(IE)是一种从非结构化或半结构化文本中提取结构化信息的技术。而开放信息抽取(OIE, Open Information Extraction)系统旨在以无监督的方式从非结构化文本中抽取不可见的关系及其参数。简而言之就是开放域信息抽取。在最简单的形式中,给定一个自然语言句子,它们以三元组的形式提取信息,包括主语(S)、关系(R)和宾语(O)。 任务形式为: 输入句子, 输出三元组; 识别正确的边界。 3.1 开放信息抽取系统历史 传统的信息抽取存在的限制是:在小型同质语料库上实现高精度、范围窄且预先指定的提取请求,而且需要人类的广泛参与标注与规则制定。下图不同时期开放信息抽取(OIE)的主要思想(main-feature): Banko等人(2007年)第一次提出了开放信息抽取(OIE, Open Information Extraction)的概念,设计了Textrunner系统,该系统在IE方法所需的手动工作中引入了一种新的提取范式: 即openie不局限于一小部分已知的目标关系,而是提取文本中发现的所有类型的关系,也就是无监督抽取。此后Wu and Weld等(2010年)提出了WOE系统,Mausam等(2012年)提出了OLLIE系统,这些系统有一个通用的范式,即先抽取实体再抽取关系,实体抽取一般采用句子成分、词性标注、依存句法、自助法等方式;关系抽取则是依照一定的规则等构建训练集,训练好一个机器学习分类器进行关系预测,通常被称为第一代开放信息抽取系统。 虽然第一代开放信息抽取系统开创了一个时代,取得了不错的效果,但是依旧存在比较严重的三个问题: 即大量非关键提取(即省略关键信息的提取)、非一致性提取(即关系短语没有有意义的解释)和冗余关系提取(传达了太多的信息), 这些问题给进一步的下游语义任务中使用造成了很大的困难。所以第二代开放信息抽取便呼之欲出了。 第一代开放信息抽取系统抽取的关系词语可能没有可解释性的意义,即序列决策时存在误差;此外抽取忽略了关键性的信息,原因是没有处理好light verb constructions (LVCs, 动词和名词组成的多词谓语,并且名词携带了谓词的语义信息)。由此,Fader等(2011年)提出了REVERB系统,首先抽取动词的关系,然后再寻找名词性短语作为实体。这种基于关系构建规则的方法能达到很高的召回率,使用比较广泛。此后,Mausam等(2011, 2016年)提出的OPENIE4系统, 结合语义角色抽取SRL、名词性短语RELNOUN等两种思路, 至今仍然是应用最广泛的开放信息抽取系统。Likun Qiu等(2014年)提出了中文ZORE系统,即所谓的双重传播语义标注,基本思想是通过对候选关系中参数的首词进行语义标记来迭代地识别关系和实体。White等(2016年)提出了PredPatt系统,使用通用依赖(UD)解析规则、构建有向图、提取谓词参数结构,不受语言的限制支持不同语种。Yuen-Hsien Tseng等(2018年)提出了的中文CORE系统,认为不需要多余的处理,开放的源码实现为依靠语义角色标注和LTP依存句法。 第二代开放信息抽取系统能够抽取到召回率很高的三元组,那么能不能抽取精确率更高的三元组呢,答案是可以的。那就是基于子句的第三代开放信息抽取系统(clause-based),这种系统的思路是引入一个句子重组阶段,将复杂句子转化为简单句,然后利用句子成分进行三元组的抽取。Del Corro and Gemulla等(2013年)提出了ClausIE系统,使用语法知识(句子重组)的方法转换复杂句子,语法和从句等分析句子成分。Angel等(2015年)提出了Stanford Open IE系统,使用学习分类器判断一组句子是否构成独立子句(简单句),然后通过手工构建的14种规则抽取三元组。Gashteovski等(2017年)提出了MinIE系统,构建在ClausIE系统之上,重点关注冗余项, 是不是可信。 然后便进入了深度学习时代,提出了基于深度学习的第四代开放信息抽取系统。第四代开放信息抽取系统的思路主要是:1.未标注语料使用OPENIE4系统等构建高召回的训练集(自助法);2.使用1中获取到的数据集,抽取式或生成式的端到端深度学习。这一时期的主要论文如下图所示: 2018 RnnOIE: Supervised Open Information ExtractionCopyAttention: Neural Open Information Extraction 2019 SenseOIE: SupervisingUnsupervisedOpenInformationExtractionModels 2020 SpanOIE(BiLSTM_span): Span Model for Open Information Extraction on Accurate CorpusMulti2OIE(BERT+Classify+Attention): Multilingual Open Information Extraction based on Multi-Head Attention with BERTIMoJIE(BERT+CopyAttention): Iterative Memory-Based Joint Open Information ExtractionOpenIE6(BERT+IGL(Attention+Label-encode))): Iterative Grid Labeling and Coordination Analysis for Open Information Extraction 五. 评估指标
|

【本文地址】
今日新闻 |
推荐新闻 |