模型精度问题(FP16,FP32,TF32,INT8)精简版 |
您所在的位置:网站首页 › 什么是单精度浮点 › 模型精度问题(FP16,FP32,TF32,INT8)精简版 |
模型精度问题(FP16,FP32,TF32,INT8)精简版
|
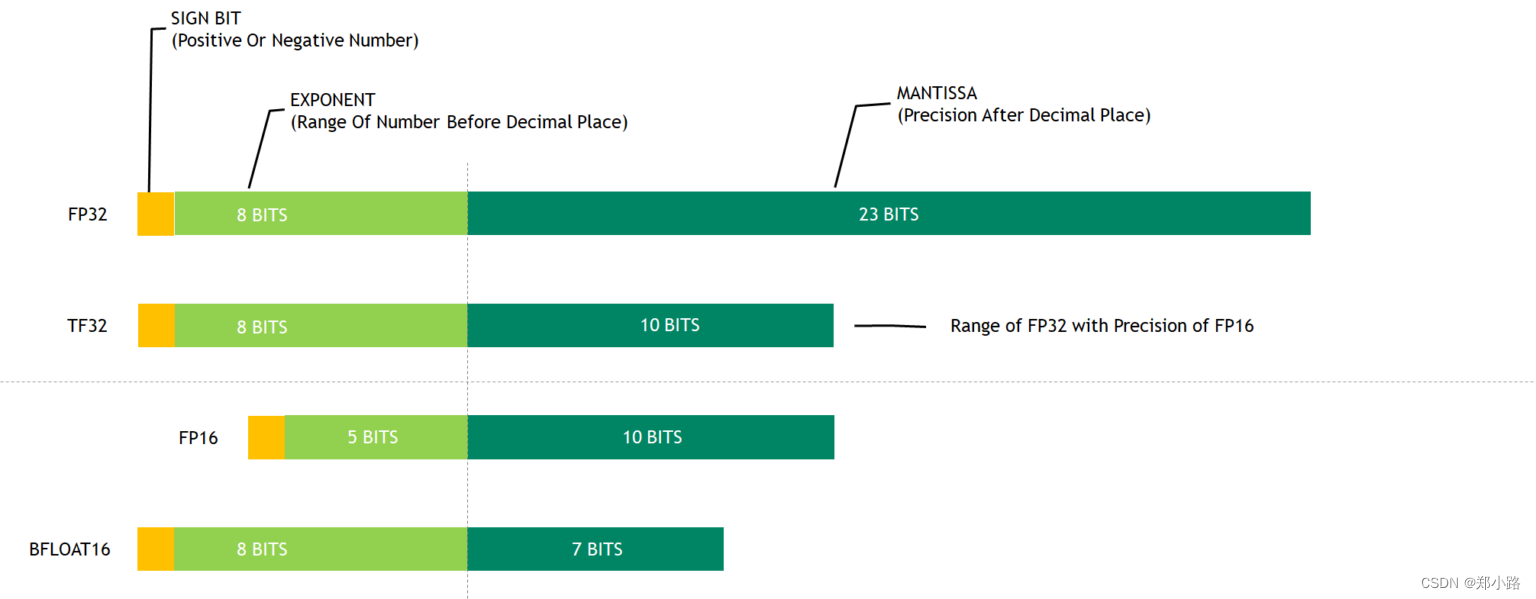
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、整体介绍二、必备知识三、模型精度1.FP322.FP163.TF324.INT 85.数据类型范围与精度 总结 前言相信大家在学习模型部署和加速时都遇到过模型精度问题,精度和效率往往需要根据实际模型应用需求进行取舍,下面我以最精简的方式介绍常见的模型精度类型(FP16,FP32,TF16,INT8),希望对大家处理模型精度问题有所帮助。 提示:以下是本篇文章正文内容,下面案例可供参考 一、整体介绍浮点数精度:双精度(FP64)、单精度(FP32、TF32)、半精度(FP16、BF16)、8位精度(FP8)、4位精度(FP4、NF4) 量化精度:INT8、INT4 注意:在使用TensorRT进行模型部署时,不同的层可以采用不同的精度,关于多精度和混合精度的概念请查询相关文档。 二、必备知识在计算机中,浮点数以二进制的方式进行存储,二进制数由符号位(sign)、指数位(exponent)和小数位(fraction)三部分组成。符号位都是1位,指数位影响浮点数范围,小数位影响精度。 FP32是模型部署常用的精度,FP32也叫做 float32,两种叫法是完全一样的,全称是Single-precision floating-point(单精度浮点数) Pytorch输出FP32信息: import torch torch.finfo(torch.float32) # 结果 finfo(resolution=1e-06, min=-3.40282e+38, max=3.40282e+38, eps=1.19209e-07, smallest_normal=1.17549e-38, tiny=1.17549e-38, dtype=float32) 2.FP16FP16也叫 float16,全称是Half-precision floating-point(半精度浮点数) 。 计算公式: TF32,全称 Tensor Float 32,是NVIDIA提出的面向深度学习训练的一种特殊数值类型,在部分任务中,TF32 相比 FP32 性能提升可达 10 倍! TF32 是一种截短的 Float32 数据格式,将 FP32 中 23 个尾数位截短为 10 bits,而指数位仍为 8 bits,总长度为 19 (=1 + 8 + 10) bits。TF32 保持了与 FP16 同样的精度(尾数位都是 10 位),同时还保持了 FP32 的动态范围(指数位都是 8 位)。 量化的概念: 一般情况下,训练好的模型的权重一般都是FP32也就是单精度浮点型,在深度学习训练和推理的过程中,最常用的精度就是FP32。当然也会有FP16、BF16、TF32等更多的精度,一般精度越低,模型尺寸和推理内存占用越少。 为了尽可能的减少资源占用,量化算法被发明。通俗来讲,量化就是将我们训练好的模型,不论是权重、还是计算op,都转换为低精度去计算。例如:FP32占用4个字节,通过INT8量化为8位,只需要1个字节,极大的加快了模型的推理速度。 量化算法可以参考: https://zhuanlan.zhihu.com/p/58182172 5.数据类型范围与精度 数据类型数值范围数值精度FP32-3.4 x 10^38 ~ 3.4 x 10^3810^-6TF32-3.4 x 10^38 ~ 3.4 x 10^3810^-3FP16-65504 ~ 6550410^-3INT8-128 ~ 1271PyTorch验证 import torch print(torch.finfo(torch.float32)) # finfo(resolution=1e-06, min=-3.40282e+38, max=3.40282e+38, eps=1.19209e-07, smallest_normal=1.17549e-38, tiny=1.17549e-38, dtype=float32) print(torch.finfo(torch.float16)) # finfo(resolution=0.001, min=-65504, max=65504, eps=0.000976562, smallest_normal=6.10352e-05, tiny=6.10352e-05, dtype=float16) print(torch.iinfo(torch.int32)) # iinfo(min=-2.14748e+09, max=2.14748e+09, dtype=int32) print(torch.iinfo(torch.int16)) # iinfo(min=-32768, max=32767, dtype=int16) print(torch.iinfo(torch.int8)) # iinfo(min=-128, max=127, dtype=int8) 总结以上就是关于常见模型精度的精简介绍,本文仅仅简单介绍了FP16、FP32、TF32、INT8的基本知识点,关于详细的模型精度以及量化算法介绍,请查阅其他详细信息,本文的目的是便于初学者快速了解模型精度问题,希望对大家有所帮助。 参考链接: https://zhuanlan.zhihu.com/p/657886517 https://zhuanlan.zhihu.com/p/676509123 https://zhuanlan.zhihu.com/p/673708074 |
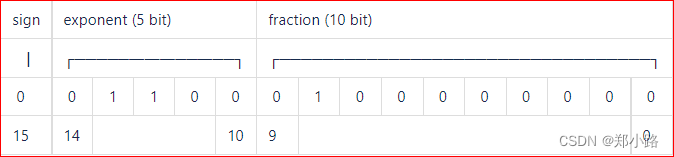 下面以表格的方式展示不同浮点数精度的区别。
下面以表格的方式展示不同浮点数精度的区别。 计算公式:
计算公式: 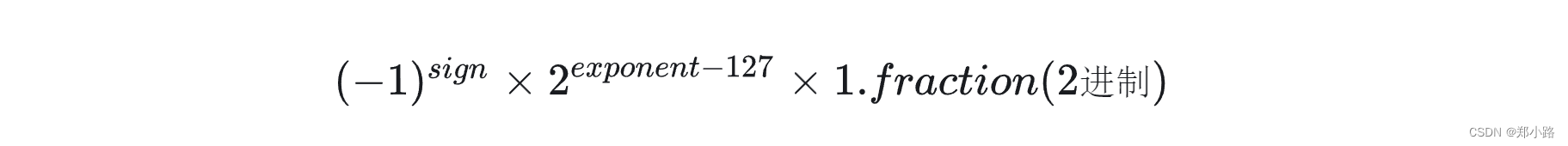
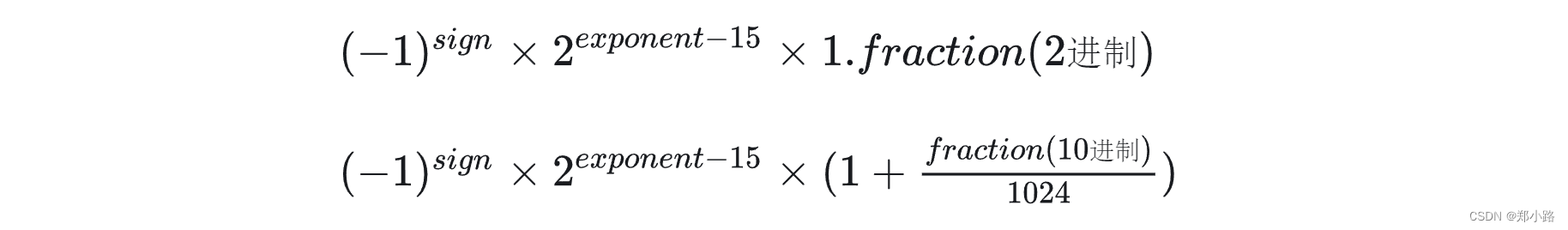 例子:计算FP16可以表示的最大正数:
例子:计算FP16可以表示的最大正数: 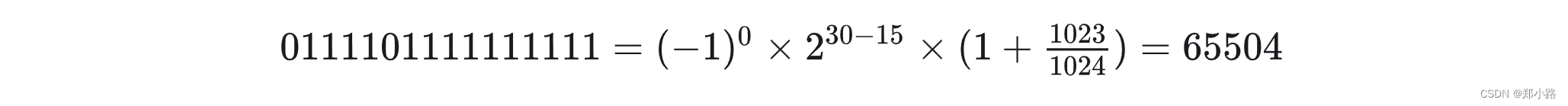
【本文地址】
今日新闻 |
推荐新闻 |