hive面试题 |
您所在的位置:网站首页 › 什么是HIVE钱包 › hive面试题 |
hive面试题
|
1. 什么是hive?
hive是基于Hadoop的一个数据仓库工具,可以将结构化和半结构化的数据文件映射为一张数据库表, 并提供简单的sql查询功能。 注意: (1)Hive本质是将HDFS转换成MapReduce的任务进行运算,底层由HDFS来提供数据存储。 (2)Hive的元数据存储在SQL上,HBase的元数据存储在HDFS上。 hive,mapreduce,HDFS关系?
避免了去写MapReduce,提供快速开发的能力,减少开发人员的学习成本。 优点:可以写sql,可扩展性强,容错性强。 缺点:效率低 3. Hive的内部组成模块,作用分别是什么?元数据:Metastore 元数据包括:表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等。 推荐使用MYSQL存储Metastore 4. Hive支持的数据格式?Text,SequenceFile,ParquetFile,ORC格式RCFILE等。 5. 进入Hiveshell窗口的方式 方式一: 1. 服务端启动metastore服务: nohup hive --service metastore > /dev/null 2>&1 & 2. 监控端口 netstat -ntulp | grep 9083 3. 进入hive的客户端 hive 4. 退出 quit; 5. 全部的客户端均可访问hive 方式二: 1. 先启动metastore nohup hive --service metastore > /dev/null 2>&1 & 2. 服务端启动hiveserver2 nohup hiveserver2 > /dev/null 2>&1 & 需要稍等下,启动服务需要时间 3. 进入命令 (1)先执行beeline,再执行:connect jdbc:hive2://node001:10000 (2)或者直接执行:beeline -u jdbc:hive2://node001:10000 -n root 4. 退出命令行 exit 方式三: 使用-e参数来直接执行hql的语句 [root@node001 ~]# hive -e "show databases;" [root@node001 ~]# beeline -u jdbc:hive2://node001:10000 -n root -e "use bdp; show tables;" beeline比hive方式快 [root@node001 ~]# hive -f hello_hive.sql [root@node001 ~]# beeline -u jdbc:hive2://node001:10000 -n root -f hello_hive.sql 扩展:mestore和hiveserver2两个服务器的差异(1)所有的hive集群,如果使用hive的方式登录客户端时,每一台虚拟机只要输入hive命令,都会启动一个mestore服务,还要指向node001的mestore服务。 而用beeline方式登录hive客户端时,它是指向的node001 hiveserver2这个服务,去node001服务器操作。 hiveserver2是有集群的,一台节点可以load data其中一台hiveserver2,但是这个hiveserver2必须是在主节点才可以成功。 6. 简述Hive主要架构及解析成MR的过程?Hive元数据默认存储在derby数据库,不支持多客户端访问,所以需要将元数据存储在MYSQL中,才支持多客户端访问。
Hive和数据库除了拥有类型的查询语言之外,无其他相似 查询语言 HQL SQL 存储位置 HDFS Raw Device或者Local FS(块设备或本地文件系统) 数据格式 用户定义 系统决定 执行引擎 MapReduce 用自己的执行引擎 执行速度 Hive执行延迟度高,但当它数据规模远远超过数据库处理能力时,Hive的并行计算能力就体现优势了。 数据库执行延迟较低 数据更新 不支持 支持 数据规模 Hive大规模的数据计算,是HDFS的数据规模 数据库能支持得数据规模较小 扩展性 Hive建立在Hadoop上,随Hadoop的扩展性。 数据库由于ACID语义的严格限制,扩展有限。 索引0.8版本之后加入位图索引 复杂的索引 执行 MapReduce Executor 执行延迟 高 低 可扩展性 高 低 数据格式:txt,zip,lzo,tar,gz,orc,rcfile,csv.... 8. Hive内部表和外部表的区别? 类别 外部表 内部表 存储 外部表数据由HDFS管理 内部表数据由hive自身管理 存储 外部表数据存储位置由自己指定(没有指定location则在默认地址下新建) 内部表数据存储在hive.metastore.warehouse.dir(默认在/user/hive/warehouse) 创建 被external修饰的就是外部表 没被修饰的是内部表 删除 删除外部表仅仅删除元数据 删除内部表会删除元数据和存储数据 说明:外部表location [root@node001 data]# pwd /data [root@node001 data]# vim dept.txt { 10,ACCOUNTING,NEW YORK 20,RESEARCH,DALLAS 30,SALES,CHICAGO 40,OPERATIONS,BOSTON } [root@node001 data]# hdfs dfs -put dept.txt /data/; hive (default)> create external table if not exists dept( > DEPTNO int, > DNAME varchar(255), > LOC varchar(255) > ) > row format delimited fields terminated by ',' > location '/data/'; # 创建外部表时,在创建的语句添加location'/data',就能直接能把数据读取出来,不需要再load data # 此时数据文件在HDFS中的/data路径下 如果外部表没有指定地址,则数据存储在默认路径中;内部表的数据存储在默认路径中。 默认路径/hive/warehouse 9. Hive中的order by,sord by,distribute by和cluster by的区别。(1)order by:对数据进行全局排序,只有一个reduce工作 (2)sort by:每个mapreduce中进行排序,一般和distribute by使用,且distribute by写在sort by前面。 当mapred.reduce.tasks=1时,效果和order by一样 (3)distribute by:类似MR的Partition,对key进行分区,结合sort by实现分区排序 (4)cluster by:当distribute by和sort by的字段相同时,可以使用cluster by代替,但cluster by只能是升序,不能指定排序规则 在生产环境中order by使用的少,容易造成内存溢出(OOM) 生产环境中distribute by和sort by用的多 10. row_number(), rank(), dense_rank()区别 select name,subject,score row_number() over(partition by subject order by score desc) rn, rank() over(partition by subject order by score desc) r, dense_rank() over(partition by subject order by score desc) dr from student_score;
分区作用:分区就是辅助查询,缩小查询范围,加快数据的检索速度和对数据按照一定的规格和条件进行管理。 分区过多的坏处: 1.hive如果有过多的分区,由于底层是存储再HDFS上,HDFS上只用于存储大文件而非小文件,因为过多的分区会增加nn的负担 2.hive如果有过多的分区,由于hive转换为mapreduce,mapreduce会转化为task。过多的小文件的话,每个文件一个task, 每个task一个JVM实例,JVM的销毁和开销会降低系统效率。 注意事项: 当分区过多且数据很大时,可以使用严格模式,避免触发一个大的mapreduce任务。当分区数量过多且数量过大时,执行宽范围的数据扫描, 会触发一个很大的mapreduce任务。在严格模式下,当where中没有分区过滤条件会禁止执行。 1.建表:create table tablename(col1 string) partitioned by(col2 string); 2.添加分区:alter table tablename add partition(col2=’202101’); 3.删除分区:alter table tablename drop partition(col2=’202101’); 12. Hive导出数据的五种方式? 1. insert方式,查询结果导出到本地或HDFS 本地:load data local inpath ‘/root/student.txt’ into table student; HDFS:load data inpath ‘/user/hive/data/student.txt’ into table student; 2. Insert方式,往表里插入 insert into table student values(1,’zhanshan’); 3. as select方式,根据查询结果创建表并插入数据 create table if not exists stu1 as select id,name from student; 4. Location方式,创建表并指定数据的路径 create external table stu2 like student location '/user/hive/warehouse/student/student.txt'; 5. Import方式,先从hive上使用export导出再导入 import table stu3 from "/user/export/student"; 13. Hive导出数据的五种方式 1. Insert方式,查询结果导出到本地或HDFS # 重写本地路径的文件 Insert overwrite local directory "/root/insert/student" select id,name from student; # 重写HDFS路径的文件 Insert overwrite directory "/user/insert/student" select id,name from student; 2. Hadoop命令导出本地 hive> dfs -get /user/hive/warehouse/student/ 000000_0 /root/hadoop/student.txt 3. hive Shell命令导出 ]$ bin/hive -e ‘select id,name from student;’ > /root/hadoop/student.txt 4. Export导出到HDFS hive> export table student to ‘/user/export/student’; 5. Sqoop导出 14. 窗口函数 select name,orderdate,cost, sum(cost) over() as sp1, --所有行相加 sum(cost) over(partition by name) as sp2, --按名字分组,组内相加 sum(cost) over(partition by name order by orderdate) as sp3, --按名字分组并按时间排序 sum(cost) over(partition by name order by orderdate rows between unbounded preceding and current row) as sp4,--由起点到当前行的聚合 sum(cost) over(partition by name order by orderdate rows between 1 preceding and current row) as sp5, --由当前一行到当前行的聚合 sum(cost) over(partition by name order by orderdate rows between 1 preceding and 1 following) as sp6, --由当前行到前后一行的聚合 sum(cost) over(partition by name order by orderdate rows between current row and unbouded following) as sp7--由当前行到后面所有行的聚合 from business;
用UDF函数解析公共字段,用UDTF函数解析事件字段 自定义UDF:继承UDF,重写evaluate方法 自定义UDTF:继承GenericUDTF,重写3个方法,initialize(自定义输出的列名和类型),process(将结果返回forward(result)),close 16. hive几种基本表类型内部表,外部表,分区表,桶表 17. hive创建表的方式及区别? (1) 普通创建(创建后会有表结构) create table if not exists student(id string, name string) row format delimited fields terminated by '\t'; (2)ike克隆表(只带过来表结构) create table if not exists student like stu; (3)as select查询创建(数据和表结构都带过来) create table if not exists student as select id, name from stu; 18. hive元数据存放的位置及区别?(1)内嵌模式:将元数据保存在本地内嵌的derby数据库中,内嵌的derby数据库每次只能访问一个数据文件,也就意味着它不支持多会话连接。 (2)本地模式:将元数据保存在本地独立的数据库中(一般是mysql),这可以支持多会话连接。 (3)远程模式:把元数据保存在远程独立的mysql数据库中,避免每个客户端都去安装mysql数据库。 19. Hive的分组方式?(1)row_number() (2)rank() (3)dense_rank() 20. Hive数据倾斜问题及解决方案? 1. 数据倾斜介绍数据倾斜指单个节点任务所处理的数据量远大于同类型任务所处理的数据量,导致该节点成为整个作业的瓶颈,这是分布式系统不可能避免的问题。 2. 倾斜原因及解决方法map输出数据按key hash分配到reduce中,由于key分布不均匀、或者业务数据本省的特点等原因造成的reduce上的数据量差异过大。 1. 任务读取大文件,最常见的是读取压缩的不可分割的大文件。解决方法:在数据压缩的时候可以采用bzip2和zip支持文件分割的压缩算法或者使用像orc,SequenceFile等列式存储。 2. key分布不均匀 情形: 实际业务中有大量的null值或一些无意义的数据参与到计算机作业中,这些数据可能来自业务未上报 或因数据规范将某类数据进行归一化变成空值或空字符串等形式,这些与业务无关的数据导致在进行分组聚合 或在执行表连接时发生数据倾斜。 解决方案: 在计算过程中排除含有这类"异常"数据即可 情形: 在多维聚合计算时存在这样的场景: select a, b, c, count() I from T group by a, b, c with rollup. 对于上述的SQL,可以拆分成4种类型的键进行分组聚合,它们分别是 (a,b)、(a,b、null)、(a,null, null)和(null, null,null) 如果T表的数据量很大,并且Map端的聚合不能很好地起到数据压缩的情况下,会导致Map端产出的数据急速膨胀,这种情况容易导致作业内存溢出的异常。如果T表含有数据倾斜键,会加剧Shuffle过程的数据倾斜。 解决方法: 1.对上述的情况我们会很自然的想到拆解上面的SQL语句,将rollup拆解成如下多个普通类型分组聚合的组合 select a, b, c, count(1)from T group by a, b, c; select a,b, null, count(1) from T group by a,b; select a,null, null, count(1) from T group by a; select null, null, null, count(1) from T; 这是很笨拙的方法,如果分组聚合的列远不止3个列,那么需要拆解的SQL语句会更多。 2.在Hive中可以通过参数(hive,new job,grouping set,cardinaliy)配置的方式自动控制作业的拆解,该参数默认值是30. 该参数表示针对grouping sets/rollups/cubes这类多维聚合的操作,如果最后拆解的键组合(上面例子的组合是4)大于该值, 会启用新的任务去处理大于该值之外的组合。如果在处理数据时,某个分组聚合的列有较大的倾斜,可以适当调小该值. 3. 无法削减中间结果的数据量引发的数据倾斜无法理解对于参数的修改配置,因为没有修改过,以后修改的时候着重看一下。 情形: 在一些操作中无法削减中间结果,例如使用collect_list聚合函数,存在如下SQL hive(default)> select address,collect_list(name) f1 from t_person group by address; 在student tb txt表中,s_age有数据倾斜,但如果数据量大到一定的数量,会导致处理倾斜的Reduce任务产生内存溢出的异常。 针对这种场景,即使开启hive.groupby.skewinda配置参数,也不会起到优化的作业,反而会拖累整个作业的运行。 启用该配置参数会将作业拆解成两个作业,第一个作业会尽可能将Map的数据平均分配到Reduce阶段,并在这个阶段实现预聚合,以减少第二个作业处理的数据量;第二个作业在第一个作业处理的数据基础上进行结果的预聚合。 hive.groupby.skewindata的核心作用在于生成的第一个作业能够有效减少数量。 但是对于collect list这类要求全量操作所有数据的中间结果的函数来说,明显起不到作用,反而因为引入新的作业增加了磁盘和网络IO的负担,而导致性能变得更为低下。 解决方案: 解决这类问题,最直接的方式就是调整Reduce所执行的内存大小, 使用mapreduce educememory mb这个参数(如果是Map任务内存瓶可以调整mapreducemap memorymb)。 但还存在一个问题,如果Hive的客户端连接的 Hiveserver2一次性需要返回处理的数据很大, 超过了启动Hiveserver2设置的Jawa(Xmx),也会导致Hiveserver2服务内存溢出。 4.两个Hive数据表连接时引发的数据倾斜 问题:两表进行普通的repartition join时,如果表连接的键存在倾斜,那么在Shufe阶段必然会引起数据倾斜。 解决方法: Hive的通常做法还是启用两个作业,第一个作业处理没有倾斜的数据,第二个作业将倾斜的数据存到分布式缓存中,分发到各个M即任务所在节点在Map价段完成join操作,即Mapjoin,这避免了Shuffle,从而避免了数据倾斜。 5. SQL语句造成数据倾斜 1.group by group by优于distinct group 情形:group by维度过小,某值的数量过多,导致处理某值的reduce非常耗时。 解决方式: 采用sum() group by的方式来替换count(distinct) 完成计算 2.count(distinct) 情形: 1.某特殊值过多 2.处理此特殊值的reduct耗时 解决方式: 1.count distinct时,将值为空的情况单独处理,如:可以直接过滤空值的行 2.在最后结果中加1。如果还有其他计算,需要进行group by,可以先将值为空的记录单独处理,再和其他计算结果进行union。 3.不同数据类型关联产生数据倾斜 情形: 比如用户表中 user_id 字段为 int,log 表中 user_id 字段既有 string 类型也有int类型。 当按照 user_id 进行两个表的 Join 操作时,处理此特殊值的reduce耗时;只有一个reduce任务,默认的Hash操作会按int型的id来进行分配,这样会导致所有string类型id的记录都分配到一个Reducer中。 解决方式: 把数字类型转换成字符串类型。 4.空值分布产生数据倾斜 解决方案: 1.把空值的key变成一个字符串加上一个随机数,把倾斜的数据分到不同的reduce上,由于null值关联不上,处理后并不影响最终的结果。 2.对于异常值如果不需要的话,最好是提前在 where 条件里过滤掉,这样可以使计算量大大减少。 3.实践中,可以使用 case when 对空值赋上随机值。此方法比直接写 is not null 更好,因为前者 job 数为 1,后者为 2. 4.如果上述的方法还不能解决,比如当有多个JOIN的时候,建议建立临时表,然后拆分HIVE SQL语句。 5.对于sql语句产生数据倾斜 解决方案: 1.选用join key分布最均匀的表作为驱动表。做好列裁剪和filter操作,以达到两表join的时候,数据量相对变小的效果。 2.大小表join:使用map join让小的维度表(1000条以下的记录条数)先进内存。在Map端完成reduce. 5. 开启数据倾斜时负载均衡 set hive.groupby.skewindata=true; 思想:就是先随机分发并处理,再按照 key group by 来分发处理 操作:当选项设定为 true,生成的查询计划会有两个 MRJob。 第一个 MRJob 中,Map 的输出结果集合会随机分布到 Reduce 中,每个 Reduce 做部分聚合操作,并输出结果,这样处理的结果是相同的 GroupBy Key 有可能被分发到不同的Reduce 中,从而达到负载均衡的目的; 第二个 MRJob 再根据预处理的数据结果按照 GroupBy Key 分布到 Reduce 中(这个过程可以保证相同的原始 GroupBy Key 被分布到同一个 Reduce 中),最后完成最终的聚合操作。 总结:它使计算变成了两个 mapreduce,先在第一个中在 shuffle 过程 partition 时随机给 key 打标记,使每个 key 随机均匀分布到各个reduce 上计算,但是这样只能完成部分计算,因为相同 key 没有分配到相同 reduce 上。所以需要第二次的 mapreduce,这次就回归正常 shuffle,但是数据分布不均匀的问题在第一次 mapreduce 已经有了很大的改善,因此基本解决数据倾斜。因为大量计算已经在第一次mr 中随机分布到各个节点完成。 21. 描述数据中的null在hive底层如何存储?null在hive底层默认是用"\N"来存储的 22. hive中的压缩格式RCFile、TextFile、SequenceFile各有什么区别?TextFile:默认格式,数据不做压缩,磁盘开销大,数据解析开销大 SequenceFile:Hadoop API提供的一种二进制文件支持,使用方便,可分割,支持三种压缩,NONE,RECORD,BLOCK RCFILE:是一种行列存储相结合的方式。首先,将数据按行分块,保证同一个record在同一个块上,避免读一个记录读取多个block。 其次,块数据列式存储,有利于数据压缩和快速的列存取。数据加载的时候性能消耗大,但具有较好的压缩比和查询响应。 23. hive如何优化?(要背过) 1. 表的优化(小表与大表)Hive默认第一个(左面的)表是小表,然后将其存放到内存中,然后去与第二张表进行比较 现在优化后小表前后无所谓 join优化:尽量将小的表放在join的左边,如果一个表很小可以采用map join. 2. 表的优化(大表与大表)针对于空值,可以将空值随机设置一个不影响结果的值 将来reduce的时候可以分区到不同的reduce,减少压力 3. mapside聚合简单来说,即再Reduce阶段完成join,容易发生数据倾斜;可以用MapJoin把小表全部加载到内存在map端进行join,避免reducer处理。 默认情况下,Map阶段同一个key数据分发给一个reduce,当一个key数据过大时就倾斜了。 并不是所有的聚合操作都需要在Reduce端完成,很多聚合操作都可以先在Map端进行部分聚合,最后在Reduce端得出最终结果。 (1)开启Map端聚合参数设置是否在Map端进行聚合,默认为True hive.map.aggr = true (2)在Map端进行聚合操作的条目数目hive.groupby.mapaggr.checkinterval = 100000 (3)有数据倾斜的时候进行负载均衡(默认是false)hive.groupby.skewindata = true 当选项设定为true,生成的查询计划会有两个MR Job. 分两次进行mapreduce,第一次随机分 获取中间结果;第二次正常分,获取最终结果。 4. Count(Distinct)防止所有的数据都分到一个Reduce上面 首先使用Group By对数据进行分组,然后再统计 5. 防止笛卡尔乘积行列过滤(列裁剪): 当表关联的时候,优先使用子查询对表的数据进行过滤,这样前面表关联数据就是少的,减少关联的次数。 案例实操: 1.测试先关联两张表,再用where条件过滤。 select o.id from bigtable b join ori o on o.id = b.id where o.id |

 元数据包括表名,表所属的数据库(默认是default),表的拥有者,列/分区字段,表的类型(是否是外部表),表的数据所在目录
一般需要借助于其他的数据载体(数据库),主要用于存放数据库的建表语句,推荐使用Mysql数据库存放数据,连接数据库需要提供:uri,username,password,driver
元数据包括表名,表所属的数据库(默认是default),表的拥有者,列/分区字段,表的类型(是否是外部表),表的数据所在目录
一般需要借助于其他的数据载体(数据库),主要用于存放数据库的建表语句,推荐使用Mysql数据库存放数据,连接数据库需要提供:uri,username,password,driver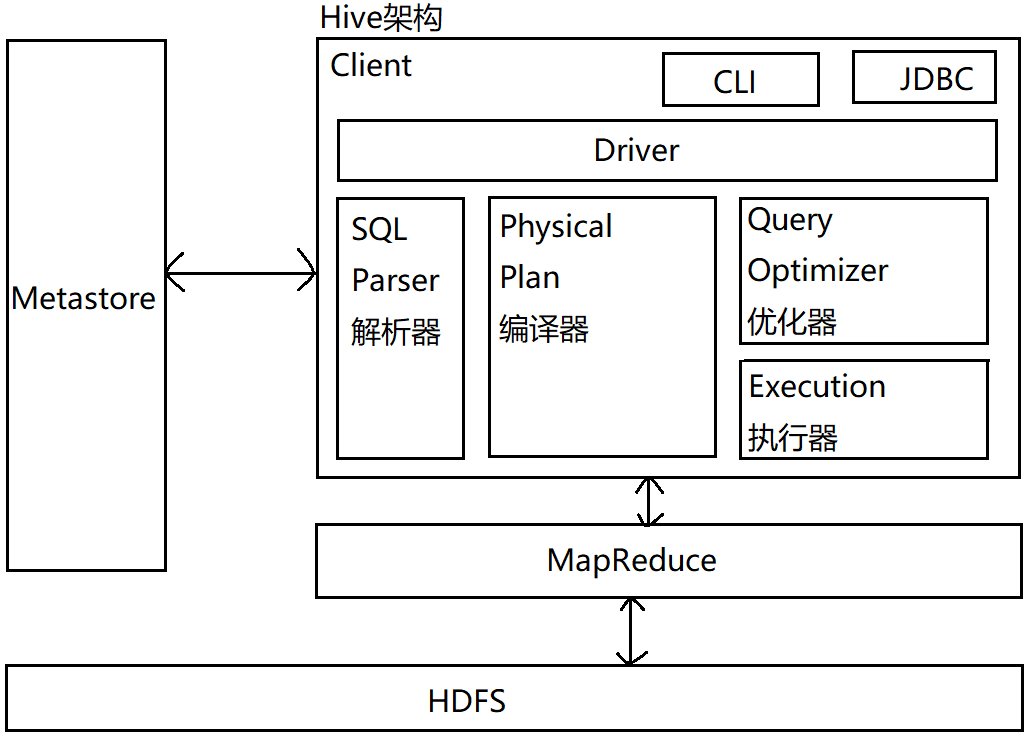 Hive解析成MR的过程:
Hive通过给用户提供一系列交互接口,接收到用户的指令(sql语句),结合元数据(metastore),经过Driver内的解析器,编译器,优化器,
执行器转换成mapreduce,提交给hadoop执行,最后将执行返回的结果输出到用户交互接口。
Hive解析成MR的过程:
Hive通过给用户提供一系列交互接口,接收到用户的指令(sql语句),结合元数据(metastore),经过Driver内的解析器,编译器,优化器,
执行器转换成mapreduce,提交给hadoop执行,最后将执行返回的结果输出到用户交互接口。



【本文地址】
今日新闻 |
推荐新闻 |