java中常见的六种线程池详解 |
您所在的位置:网站首页 › 什么文库比较好用比较全的 › java中常见的六种线程池详解 |
java中常见的六种线程池详解
|
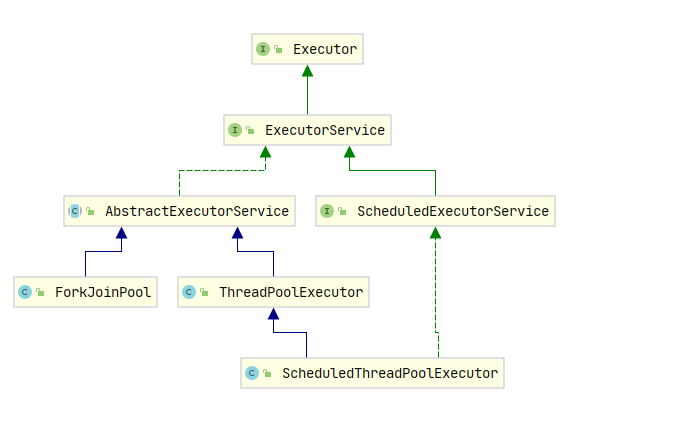
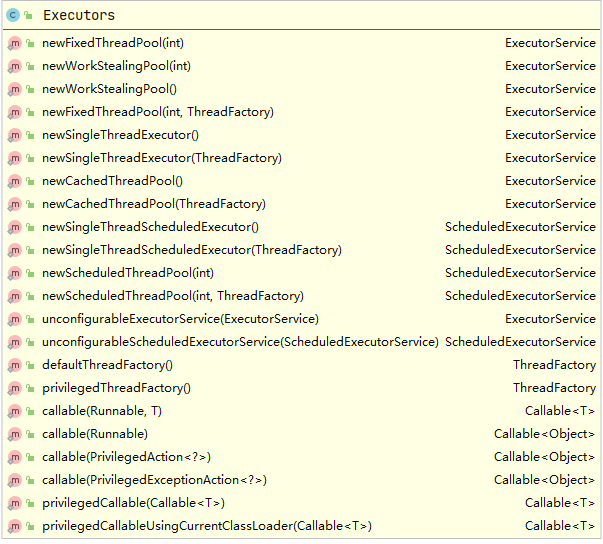
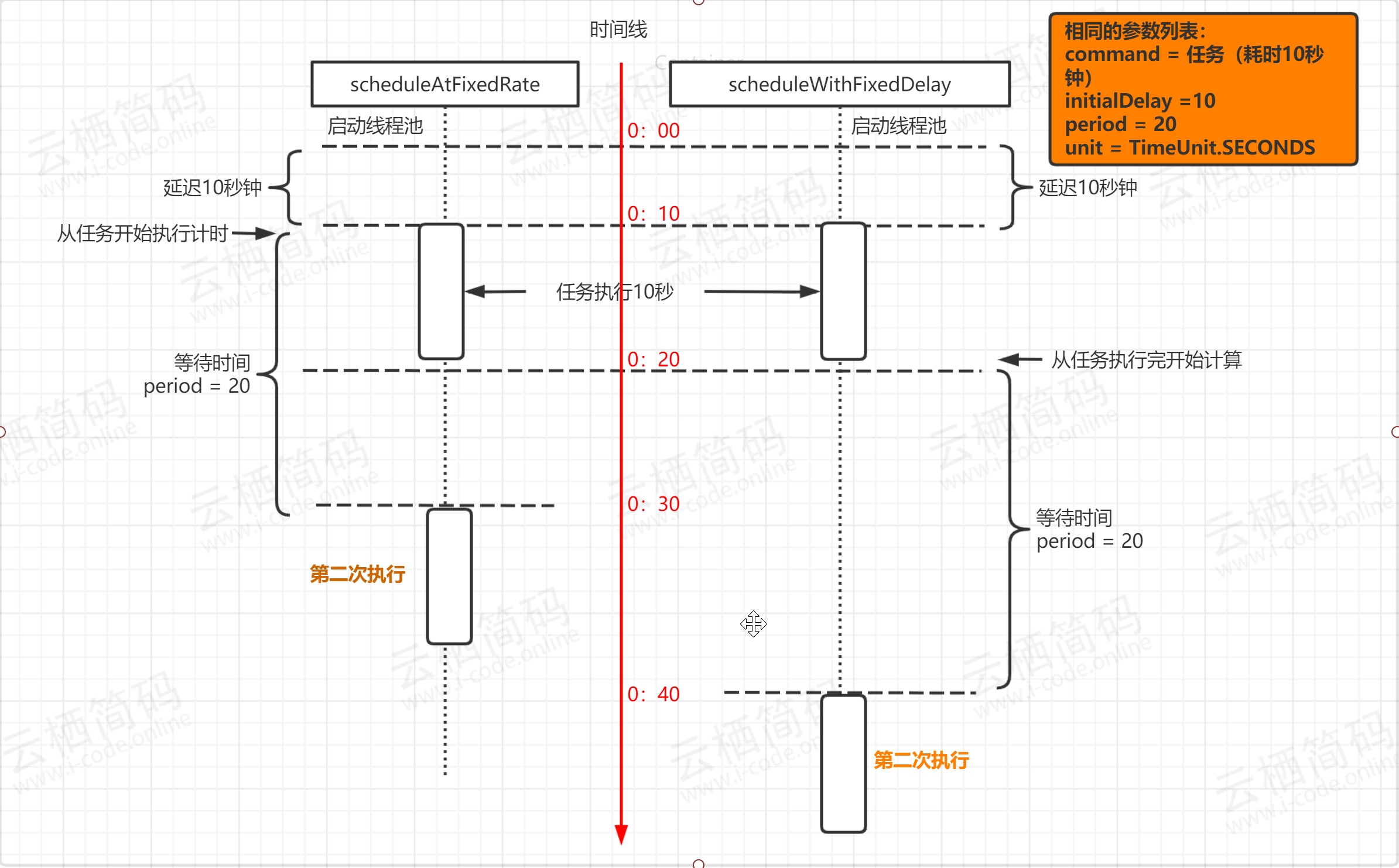
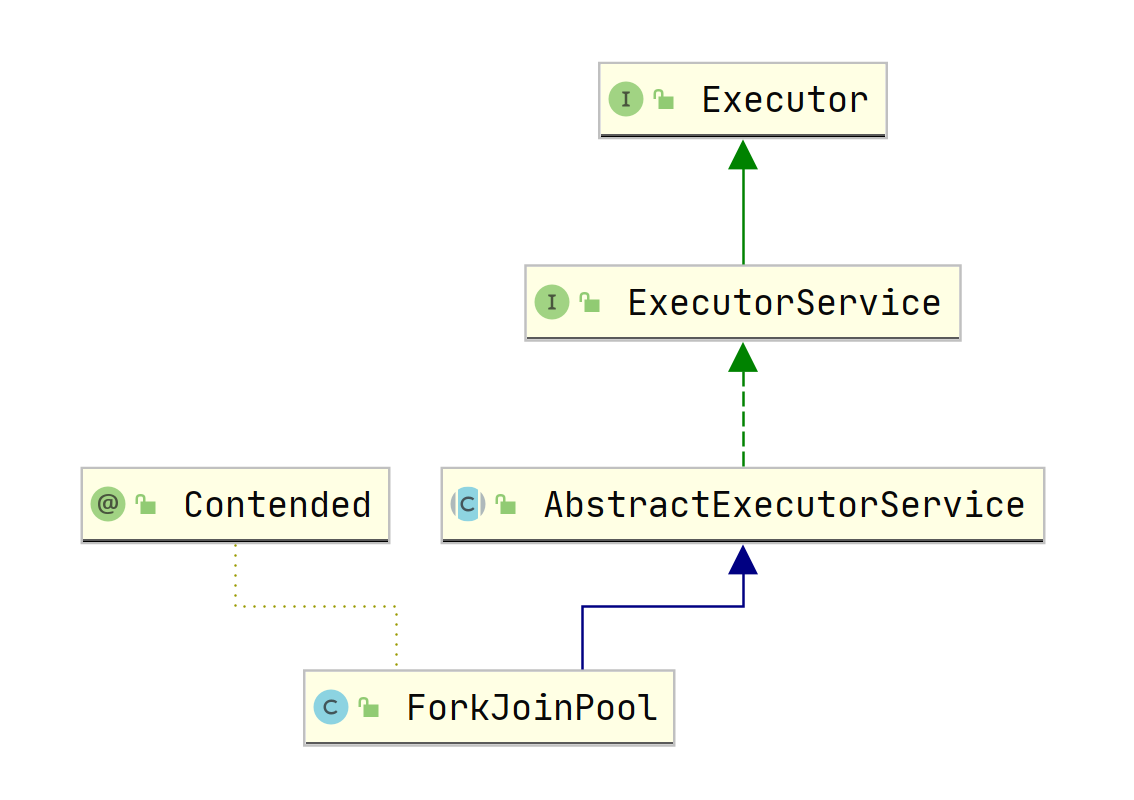
我们可以看到方法内创建线程调用的实际是 ThreadPoolExecutor 类,这是线程池的核心执行器,传入的 nThread 参数作为核心线程数和最大线程数传入,队列采用了一个链表结构的有界队列。 这种线程池我们可以看作是固定线程数的线程池,它只有在开始初始化的时候线程数会从0开始创建,但是创建好后就不再销毁,而是全部作为常驻线程池,这里如果对线程池参数不理解的可以看之前文章 《解释线程池各个参数的含义》。 对于这种线程池他的第三个和第四个参数是没意义,它们是空闲线程存活时间,这里都是常驻不存在销毁,当线程处理不了时会加入到阻塞队列,这是一个链表结构的有界阻塞队列,最大长度是Integer. MAX_VALUE SingleThreadExecutor SingleThreadExecutor 线程的特点是它的核心线程数和最大线程数均为1,我们也可以将其任务是一个单例线程池,它的实现代码是Executors#newSingleThreadExcutor() , 如下: public static ExecutorService newSingleThreadExecutor() { return new FinalizableDelegatedExecutorService (new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue())); } public static ExecutorService newSingleThreadExecutor(ThreadFactory threadFactory) { return new FinalizableDelegatedExecutorService (new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue(), threadFactory)); } 上述代码中我们发现它有一个重载函数,传入了一个ThreadFactory 的参数,一般在我们开发中会传入我们自定义的线程创建工厂,如果不传入则会调用默认的线程工厂 我们可以看到它与 FixedThreadPool 线程池的区别仅仅是核心线程数和最大线程数改为了1,也就是说不管任务多少,它只会有唯一的一个线程去执行 如果在执行过程中发生异常等导致线程销毁,线程池也会重新创建一个线程来执行后续的任务 这种线程池非常适合所有任务都需要按被提交的顺序来执行的场景,是个单线程的串行。 CachedThreadPool cachedThreadPool 线程池的特点是它的常驻核心线程数为0,正如其名字一样,它所有的县城都是临时的创建,关于它的实现在 Executors#newCachedThreadPool() 中,代码如下: public static ExecutorService newCachedThreadPool() { return new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue()); } public static ExecutorService newCachedThreadPool(ThreadFactory threadFactory) { return new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue(), threadFactory); } 从上述代码中我们可以看到 CachedThreadPool 线程池中,最大线程数为 Integer.MAX_VALUE , 意味着他的线程数几乎可以无限增加。 因为创建的线程都是临时线程,所以他们都会被销毁,这里空闲 线程销毁时间是60秒,也就是说当线程在60秒内没有任务执行则销毁 这里我们需要注意点,它使用了 SynchronousQueue 的一个阻塞队列来存储任务,这个队列是无法存储的,因为他的容量为0,它只负责对任务的传递和中转,效率会更高,因为核心线程都为0,这个队列如果存储任务不存在意义。 ScheduledThreadPool ScheduledThreadPool 线程池是支持定时或者周期性执行任务,他的创建代码 Executors.newSchedsuledThreadPool(int) 中,如下所示: public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) { return new ScheduledThreadPoolExecutor(corePoolSize); } public static ScheduledExecutorService newScheduledThreadPool( int corePoolSize, ThreadFactory threadFactory) { return new ScheduledThreadPoolExecutor(corePoolSize, threadFactory); } 我们发现这里调用了 ScheduledThreadPoolExecutor 这个类的构造函数,进一步查看发现 ScheduledThreadPoolExecutor 类是一个继承了 ThreadPoolExecutor 的,同时实现了 ScheduledExecutorService 接口,我们看到它的几个构造函数都是调用父类 ThreadPoolExecutor 的构造函数 public ScheduledThreadPoolExecutor(int corePoolSize) { super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS, new DelayedWorkQueue()); } public ScheduledThreadPoolExecutor(int corePoolSize, ThreadFactory threadFactory) { super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS, new DelayedWorkQueue(), threadFactory); } public ScheduledThreadPoolExecutor(int corePoolSize, RejectedExecutionHandler handler) { super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS, new DelayedWorkQueue(), handler); } public ScheduledThreadPoolExecutor(int corePoolSize, ThreadFactory threadFactory, RejectedExecutionHandler handler) { super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS, new DelayedWorkQueue(), threadFactory, handler); } 从上面代码我们可以看到和其他线程池创建并没有差异,只是这里的任务队列是 DelayedWorkQueue 关于阻塞丢列我们下篇文章专门说,这里我们先创建一个周期性的线程池来看一下 public static void main(String[] args) { ScheduledExecutorService service = Executors.newScheduledThreadPool(5); // 1. 延迟一定时间执行一次 service.schedule(() ->{ System.out.println("schedule ==> 云栖简码-i-code.online"); },2, TimeUnit.SECONDS); // 2. 按照固定频率周期执行 service.scheduleAtFixedRate(() ->{ System.out.println("scheduleAtFixedRate ==> 云栖简码-i-code.online"); },2,3,TimeUnit.SECONDS); //3. 按照固定频率周期执行 service.scheduleWithFixedDelay(() -> { System.out.println("scheduleWithFixedDelay ==> 云栖简码-i-code.online"); },2,5,TimeUnit.SECONDS); } 上面代码是我们简单创建了 newScheduledThreadPool ,同时演示了里面的三个核心方法,首先看执行的结果:
结果:
|




【本文地址】
今日新闻 |
推荐新闻 |