深度学习中的随机初始化种子random.seed()与参数初始化 |
您所在的位置:网站首页 › 什么叫电脑初始化 › 深度学习中的随机初始化种子random.seed()与参数初始化 |
深度学习中的随机初始化种子random.seed()与参数初始化
|
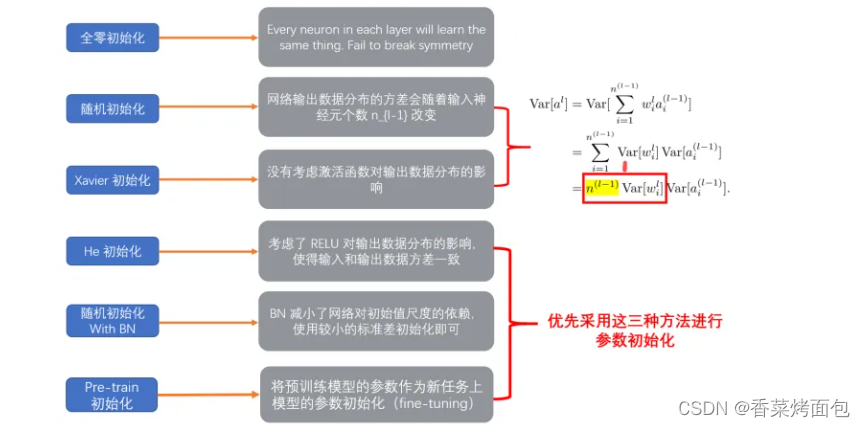
目录 1. 深度学习中的随机初始化种子 2. random函数用法总结 3. 深度学习中的参数初始化 3.1 初始化方法 3.2 初始化方案建议 3.3 偏置初始化 3.4 pytorch 初始化API 3.5 总结 1. 深度学习中的随机初始化种子seed在深度学习代码中叫随机种子,设置seed的目的是由于深度学习网络模型中初始的权值参数通常都是初始化成随机数,而使用梯度下降法最终得到的局部最优解对于初始位置点的选择很敏感,设置了seed就相当于规定了初始的随机值。 即产生随机种子意味着每次运行实验,产生的随机数都是相同的 为将模型在初始化过程中所用到的“随机数”全部固定下来,以保证每次重新训练模型需要初始化模型参数的时候能够得到相同的初始化参数,从而达到稳定复现训练结果的目的。【血泪教训】 torch.manual_seed(seed):设置生成随机数的种子【You can use torch.manual_seed() to seed the RNG for all devices (both CPU and CUDA)】torch.cuda.manual_seed_all():为所有的GPU设置种子【使用多个GPU】torch.cuda.manual_seed(seed):在GPU中设置生成随机数的种子【当设置的种子固定下来的时候,之后依次pytorch生成的随机数序列也被固定下来,当只调用torch.cuda.manual_seed()一次时并不能生成相同的随机数序列,要得到相同的随机数序列就需要每次产生随机数的时候都要调用torch.cuda.manual_seed()】dgl.random.seed(seed):在DGL中设置随机方法的种子random.seed(seed):改变随机生成器的种子,传入的数值用于指定随机数生成时所用算法开始时所选定的整数值,如果使用相同的seed()值,则每次生成的随机数都相同;如果不设置值,每次生成的随机数会不同 2. random函数用法总结 random.random(): 返回随机生成的一个浮点数,范围在[0,1)之间random.uniform(a, b): 返回随机生成的一个浮点数,范围在[a, b)之间random.randint(a,b):生成指定范围内的整数 random.randrange([start],stop[,step]):用于从指定范围内按指定基数递增的集合中获取一个随机数random.choice():从指定的序列中获取一个随机元素random.shuffle(x[,random]):用于将一个列表中的元素打乱,随机排序random.sample(sequence,k):用于从指定序列中随机获取指定长度的片段,sample()函数不会修改原有序列np.random.rand(d0, d1, …, dn): 返回一个或一组浮点数,范围在[0, 1)之间np.random.normal(loc=a, scale=b, size=()): 返回满足条件为均值=a, 标准差=b的正态分布(高斯分布)的概率密度随机数np.random.randn(d0, d1, … dn): 返回标准正态分布(均值=0,标准差=1)的概率密度随机数np.random.standard_normal(size=()): 返回标准正态分布(均值=0,标准差=1)的概率密度随机数np.random.randint(a, b, size=(), dtype=int): 返回在范围在[a, b)中的随机整数(含有重复值)random.seed(): 设定随机种子 3. 深度学习中的参数初始化初始化参数指的是在网络模型训练之前,对各个节点的权重和偏置进行初始化赋值的过程。 在深度学习中,神经网络的权重初始化方法对模型的收敛速度和性能有着至关重要的影响。模型的训练,简而言之,就是对权重参数W的不停迭代更新,以期达到更好的性能。而随着网络深度(层数)的增加,训练中极易出现梯度消失(梯度很小)或者梯度爆炸(梯度很大)等问题。因此,对权重W的初始化显得至关重要,一个好的权重初始化虽然不能完全解决梯度消失或梯度爆炸的问题,但是对于处理这两个问题是有很大帮助的,并且十分有利于提升模型的收敛速度和性能表现。 1)参数初始化为任一常数:不可行 固定初始化:模型参数初始化为一个固定常数,这意味着所有单元具有相同的初始化状态,所有的神经元都具有相同的输出和更新梯度,并进行完全相同的更新,使得神经元不存在非对称性,效果大打折扣随机初始化:随机对参数初始化,如果不考虑随机初始化的分布则会导致梯度爆炸和梯度消失的问题2)参数初始化为0:不可行 参数初始化为0,会导致后续所有的网络中的权重失效,即反向传播时,参数的偏导数为0,模型参数无法更新,出现梯度消失的问题参数初始化为零虽然经过非线性的激活函数后能更新参数,但是同一层所有参数的梯度都是相同的,使得更新后的同一层参数值是相同的,最终导致模型虽然能训练但整体是无效的3)参数初始化为0.01:不可行 同一层所有参数的梯度都是相同的,使得更新后同一层的参数值是相同的,最终导致模型虽然能训练但是整体是无效的前向传播过程中,随着层数增加,神经元的输出值也是会迅速向0靠拢的,同样会导致反向传播过程中梯度很小,导致梯度消失的问题 3.1 初始化方法1. 随机初始化 将参数设置为接近0的很小的随机数(有正有负),在实际中,随机参数服从高斯分布/正态分布(Gaussian distribution / normal distribution)和均匀分布(uniform distribution)都是有效的初始化方法。 正态分布初始化:又称高斯分布初始化,参数从一个固定均值和固定方差的高斯分布进行随机初始化均匀分布初始化:在一个给定区间 [ -r,r ] 内采用均匀分布来初始化参数2. 标准初始化 标准初始化方法更适用于3. Xavier初始化和He初始化 Xavier初始化适用于
4. 迁移学习初始化 将 预训练模型的参数 作为新任务上的初始化参数 5. 数据敏感初始化 根据自身任务数据集而特别定制的参数初始化方法 3.2 初始化方案建议
Reference:深度学习之参数初始化 - 知乎 3.3 偏置初始化 一般初始化为常数0,对于Relu激活函数,一般设置为一个较小的常数如0.01。 3.4 pytorch 初始化APIReference:torch.nn.init — PyTorch 2.0 documentation 1. 均匀分布 torch.nn.init.uniform_(tensor, a=0.0, b=1.0) # Examples >>> w = torch.empty(3, 5) >>> nn.init.uniform_(w)2. 正态分布 torch.nn.init.normal_(tensor, mean=0.0, std=1.0) # Examples >>> w = torch.empty(3, 5) >>> nn.init.normal_(w)3. Xavier初始化 torch.nn.init.xavier_uniform_(tensor, gain=1.0) # Examples >>> w = torch.empty(3, 5) >>> nn.init.xavier_uniform_(w, gain=nn.init.calculate_gain('relu')) torch.nn.init.xavier_normal_(tensor, gain=1.0) # Examples >>> w = torch.empty(3, 5) >>> nn.init.xavier_normal_(w)4. He初始化 torch.nn.init.kaiming_uniform_(tensor, a=0, mode='fan_in', nonlinearity='leaky_relu') # Examples >>> w = torch.empty(3, 5) >>> nn.init.kaiming_uniform_(w, mode='fan_in', nonlinearity='relu') torch.nn.init.kaiming_normal_(tensor, a=0, mode='fan_in', nonlinearity='leaky_relu') # Examples >>> w = torch.empty(3, 5) >>> nn.init.kaiming_normal_(w, mode='fan_out', nonlinearity='relu') 3.5 总结 Sigmoid、Tanh激活函数时,优先考虑Xavier初始化Relu激活函数时,优先考虑He初始化方法Batch Normalization的引入,使参数初始化方法对结果的影响减弱,实际应用中可以尝试不同的初始化方法 |

【本文地址】
今日新闻 |
推荐新闻 |