基于深度双向学习的人脸素描图像生成系统及方法 |
您所在的位置:网站首页 › 人脸素描画法6步骤 › 基于深度双向学习的人脸素描图像生成系统及方法 |
基于深度双向学习的人脸素描图像生成系统及方法
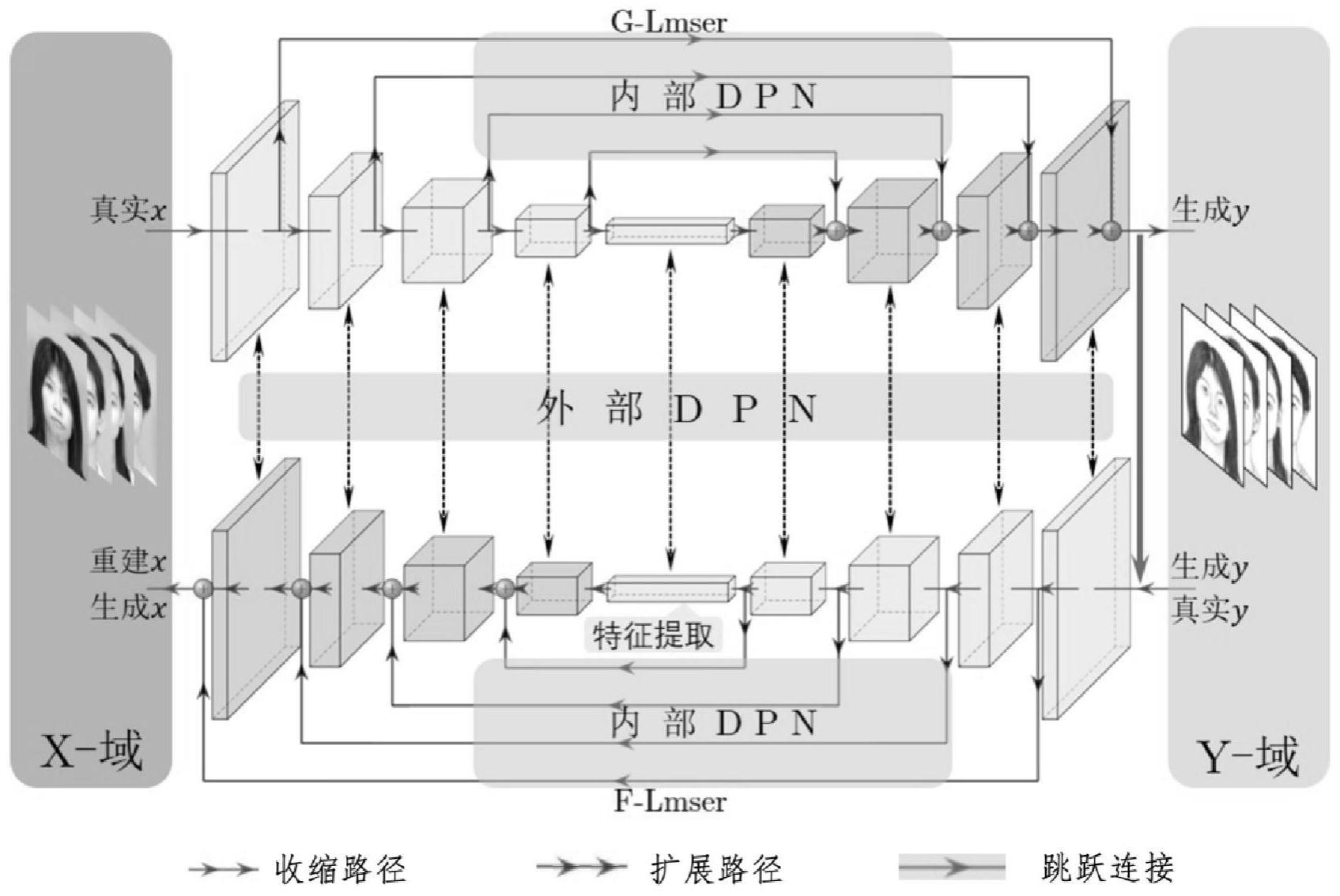 本发明涉及一种深度学习领域和图像处理领域的方法,具体地,涉及一种基于最小平方误差重建自组织网络的深度双向学习框架、神经元对偶特性的人脸素描图像生成系统及方法。 背景技术: 1、人脸素描图像生成是指将人脸照片自动转换为相对应的素描图像,人脸素描图像可应用于刑侦执法,将犯罪嫌疑人的身份照片自动转化为素描图像,与根据现场目击者描述所画之素描图像进行比对,缩小嫌疑人范围;也可应用于数字娱乐领域,如自动生成素描风格的用户头像,具有重要的应用价值。 2、早期,研究者通过人脸照片切片和素描图像切片的相似度搜索和线性组合方法来合成人脸素描图像,如,tang和wang使用一种基于特征变换的方法,通过主成分分析将测试照片映射到训练图像集的特征空间中,然后再通过这个映射将训练素描集进行加权线性组合,生成最后的素描图像,但相似度搜索的过程非常耗时,且合成的样本比较平滑,与真实的画师绘制的素描图像相比,缺乏足够的素描纹理,这些方法无法满足对人类素描图像的生成要求。 3、随着深度神经网络技术的快速发展,特别是卷积神经网络(convolutionalneural networks,cnn)和生成对抗网络(generative adversarial network,gan)在图像生成领域得到了广泛的应用,人脸素描图像生成问题取得了不错的进展。但,采用cnn来直接获得人脸照片到素描图像的映射模型,生成的结果与真实样本的语义和感知相似程度不够高,一些方法所生成的图像还存在较多污点。采用gan技术生成的素描图像质量相对较高,但其需要大量数据来训练才能达到比较理想的表现。一些研究通过引入额外的辅助机制和模块来促进网络的训练,使得在样本规模不大的情况下,提高模型的生成能力。然而,这些辅助模块本身是需要其他的大规模数据集来预训练的,受限于本身的数据集与辅助数据集之间数据模式和分布的差异,应用场景改变后可能不再对模型起正向作用,而且这些辅助的大型数据集收集成本较高,应用价值严重受限。 4、经检索,中国发明专利公开号为cn111667007a公开了一种基于对抗生成网络的人脸铅笔画图像生成方法,该方法通过图像处理、生成对抗网络模型构建、模型训练最后生成人脸铅笔画图像。其不足在于,上述专利使用的gan网络,网络结构比较简单,生成的铅笔画视觉效果比较差,存在模糊、较多噪音的问题,且需要大规模数据集用于训练。 技术实现思路 1、针对现有技术中的缺陷,本发明的目的是提供一种基于深度双向学习的人脸素描图像生成系统及方法。 2、根据本发明的一个方面,提供一种基于深度双向学习的人脸素描图像生成系统,包括:数据采集与预处理模块,所述数据采集与预处理模块采集训练数据并进行预处理; 3、生成网络模块,所述生成网络生成素描图像或者照片; 4、对抗式判别模块,所述对抗式判别模块判别对象是否为所述生成网络生成结果; 5、反馈更新模块,所述反馈更新模块定义损失函数,更新所述生成网络模块和所述对抗式判别模块参数; 6、训练模块,所述训练模块训练所述生成网络模块和所述对抗式判别模块; 7、应用模块,所述应用模块使用训练好的模型实现人脸素描图像生成。 8、优选地,所述采集训练网络所需的数据,包括:采集香港中文大学面部素描数据库(cufs数据集)和香港中文大学素描feret数据库(cufsf数据集) 9、所述对数据进行预处理,包括:根据数据中人脸双眼和嘴唇中间三点进行几何校正、对数据进行裁剪、对数据进行填充和对数据进行随机裁剪操作。 10、优选地,所述生成网络模块,包括: 11、照片到素描图像生成网络模块:建立基于最小平方误差重建自组织网络(lmser)的深度双向学习网络框架,建立照片到素描图像生成网络; 12、素描图像到照片生成网络模块:基于所述lmser深度双向学习网络框架建立素描图像到照片的生成网络; 13、特征传递模块:包括内部特征传递模块在生成网络内部进行特征传递和外部特征传递模块在两个生成网络之间进行特征传递。 14、优选地,所述照片到素描图像生成网络模块,包括第一神经网络g-lmser,所述g-lmser网络,包括: 15、一个编码器,所述编码器将输入人脸照片映射到隐空间编码; 16、一个解码器,所述解码器将所述隐空间编码映射到素描图像; 17、其中,所述编码器包括5个残差模块(resdown块),每个残差模块包括1个卷积操作的直接映射部分和2个卷积操作的残差部分; 18、所述解码器包括5个残差模块(resup块),每个残差模块包括1个卷积操作的直接映射部分和2个卷积操作的残差部分。 19、优选地,所述素描图像到照片生成网络模块,包括第二神经网络f-lmser网络,所述f-lmser网络,包括: 20、一个编码器,所述编码器将输入素描图像映射到隐空间编码; 21、一个解码器,所述解码器将隐空间编码映射到人脸照片; 22、其中,所述编码器包括5个残差模块(resdown块),每个残差模块包括1个卷积操作的直接映射部分和2个卷积操作的残差部分; 23、所述解码器包括5个残差模块(resup块),每个残差模块包括1个卷积操作的直接映射部分和2个卷积操作的残差部分。 24、优选地,所述特征传递模块,包括: 25、内部特征传递:所述内部特征传递通过神经元对偶特性(内部dpn)作用于内部的两个lmser网络(g-lmser和f-lmser)中,所述内部dpn通过从特征图的收缩路径到与其对应的扩展路径上的跳跃连接实现;跳跃连接把编码器部分对原始数据特征提取过程中得到的特征信息直接传递到解码器中; 26、外部特征传递:所述外部特征传递是利用神经元对偶特性(外部dpn),在g-lmser和f-lmser网络中,f-lmser网络为g-lmser提供正则化约束,通过两者相对应的网络块之间的特征一致性约束的方式实现。 27、优选地,所述对抗式判别器模块建立两个对抗式判别器,分别为: 28、第一对抗式判别器(dy),用于区分素描图像是生成网络生成的还是画师所画的真素描图像,采用patchgan结构,网络包括5个卷积层; 29、第二对抗式判别器(dx)用于区分人脸照片是生成网络生成的还是真正的照片,采用patchgan结构,网络包括5个卷积层。 30、优选地,所述反馈更新模块,包括: 31、定义损失函数,将f-lmser用作感知网络,从y和g(x)中提取高层特征,用一致性损失让两者对应的特征相互趋近;其中,y为人脸照片x对应的真实素描图像,g(x)为人脸照片x通过生成网络g得到的生成素描图像。 32、将感知损失和输出层的一致性损失融合为一个损失函数; 33、在g-lmser和f-lmser中,采用最小平方对抗损失。 34、优选地,所述训练模块,包括: 35、交替采用梯度下降法训练dx和dy; 36、训练第一神经网络g和第二神经网络f。 37、所述应用模块,使用训练好的生成网络,通过一个编码器,对输入的人脸照片进行编码,映射到隐空间,再由一个解码器将所述隐空间编码映射到素描图像,输出人脸素描图像。 38、根据本发明的第二个方面,提供一种基于深度双向学习的人脸素描图像生成方法,包括: 39、采集数据并进行预处理; 40、采用基于最小平方误差重建自组织网络(lmser)的深度双向学习网络框架,建立第一神经网络g,实现照片到素描图像的映射; 41、采用基于最小平方误差重建自组织网络(lmser)的深度双向学习网络框架,建立第二神经网络f,实现素描图像到照片的映射; 42、采用根据神经元对偶特性搭建的内部特征传递机制,在第一神经网络g和第二神经网络f中,对原始数据特征提取过程中得到的特征信息直接传递到解码器中; 43、采用根据神经元对偶特性搭建的外部特征传递机制,使第二神经网络f为第一神经网络g提供一种正则化约束; 44、采用patchgan结构的判别器,建立两个对抗式判别器,一个用于区分素描图像是生成网络生成的还是画师所画的真素描图像,另一个用于区分人脸照片是生成网络生成的还是真正的照片; 45、采用反馈更新机制,对网络进行训练; 46、采用adam优化器,先交替采用梯度下降法训练两个对抗式判别器,再训练第一神经网络g和第二神经网络f,完成网络的训练。 47、与现有技术相比,本发明具有如下的有益效果: 48、本发明实施例中的一种基于深度双向学习的人脸素描图像生成系统及方法,利用深度双向学习进行内部和外部的神经元信息共享传递,仅需少量数据集进行训练即可自动生成具有细节表现的素描风格图像。 49、本发明一优选实施例中的照片到素描图像生成网络模块,使用了一个包含局部跳跃连接的lmser网络,作为生成网络,并且利用dpn前向传递不同网络层学习得到的多层级特征信息,增强素描生成的纹理细节。 50、本发明一优选实施例中的素描图像到照片生成网络模块,使用了一个包含局部跳跃连接的lmser网络,另外,该模块还为照片到素描图像生成网络提供了一种正则化约束,可提升其深度表征学习能力。 51、本发明一优选实施例中的特征传递模块;特征传递包括内部特征传递模块和外部特征传递模块,内部特征传递模块以局部跳跃连接的形式实现,前向传递不同网络层学习得到的多层级特征信息,外部特征传递模块利用f-lmser网络将信息回传给g-lmser网络,使得整个模型具有循环神经网络的特性,善于捕捉素描线条的前后时序特征,促使模型生成贴近艺术家画出来的素描图像。 52、本发明一优选实施例中的对抗式判别器模块;用于分辨输入样本是生成样本的分布还是真实样本的分布,判别器在训练过程中,提高自身分别真假的能力以激励生成网络的生成能力,本发明采用patchgan结构,把输入图像以70*70划分成小块进行判别,有利于提高判别器的判别能力,从而激励生成网络生成更接近样本的人脸素描图像。 |
【本文地址】
今日新闻 |
推荐新闻 |