JD京东爬虫 |
您所在的位置:网站首页 › 京东评价在哪儿看 › JD京东爬虫 |
JD京东爬虫
|
JD京东爬虫-商品评论爬虫
附源码
本教程适合初学者。 分析开始--------------- 打开京东商品链接,打开抓包工具(加载网页后打开抓包工具,发现没有抓到数据包,刷新网页就行),这边直接筛选js了,就不用看那么多内容。然后在响应数据中看看有没有想要的评论数据。 导包———>>>>>>>这边只需要导入两个包:分别对应爬虫和正则。 注意----->>>>初学者建议每一步都print一下,看一下动态组成的url是否可以手动访问,还可以看看正则处理前是否获取到数据。 源码如下: # -*- endoding: utf-8 -*- # @ModuleName:京东 # @Function(功能): # @Author : 苏穆冰白月晨 # @Time : 2021/3/7 0:56 import requests import re ''' https://club.jd.com/comment/productPageComments.action? callback=fetchJSON_comment98 &productId=1233203 &score=0 &sortType=5 &page=1 &pageSize=10 &isShadowSku=0 &fold=1 ''' def main(): first = 1 for i in range(1, 50): url = 'https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=1233203&score=0&sortType=5&pageSize=10&isShadowSku=0&fold=1&page=' finalurl = url + str(i) + '&pageSize=10&isShadowSku=0&fold=1' header = { 'User-Agent': "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:38.0) Gecko/20100101 Firefox/38.0", } data = requests.get(url=finalurl,headers=header).text remodel_comment = re.compile(r'\"content\":\"([^"]+)\",\"(?:creationTime|vcontent)\"') # 匹配评论 comment_list = remodel_comment.findall(data) for i in comment_list: print(first,":",i) first += 1 main() |
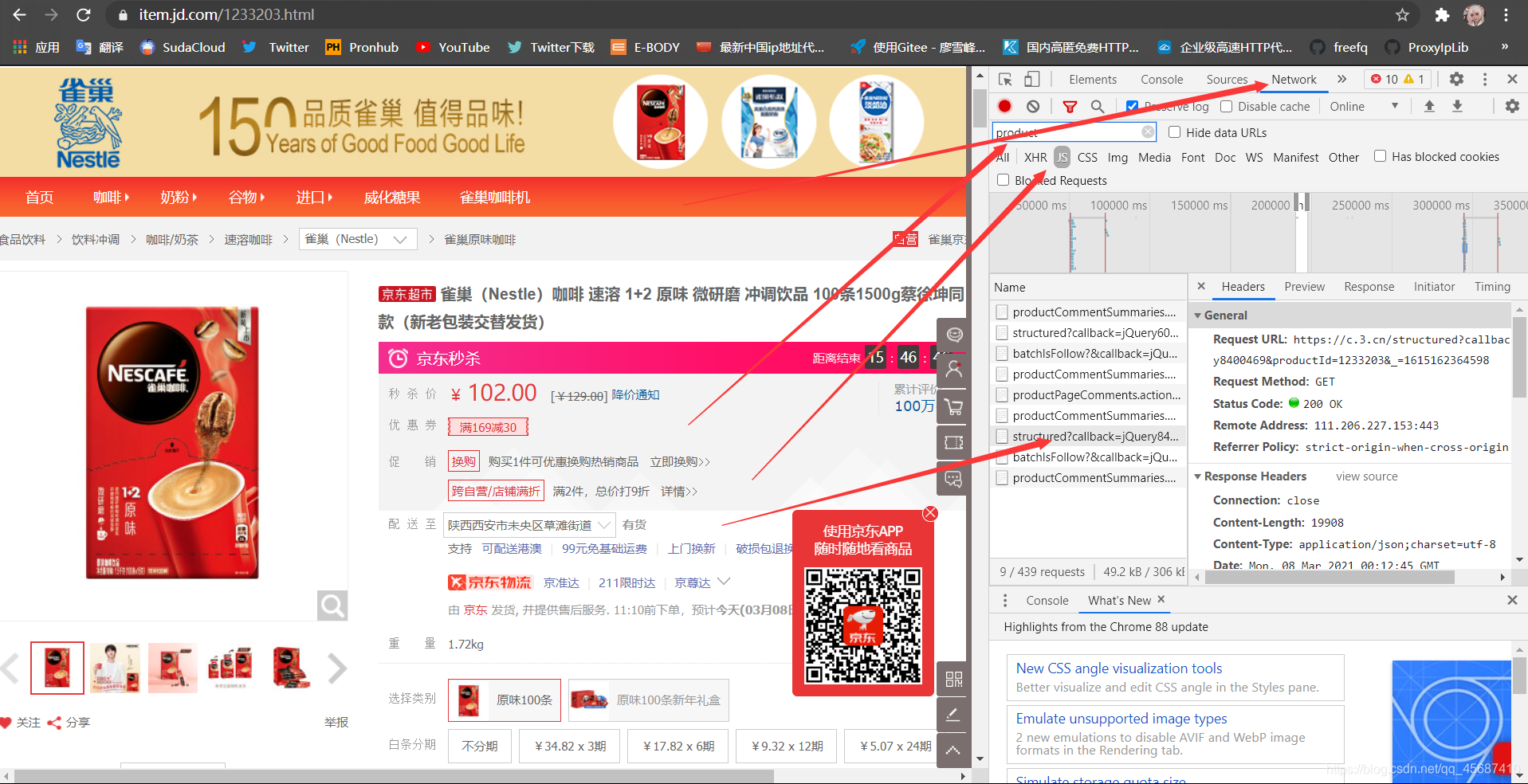 然后双击抓到的数据包,或者复制url进入浏览器。
然后双击抓到的数据包,或者复制url进入浏览器。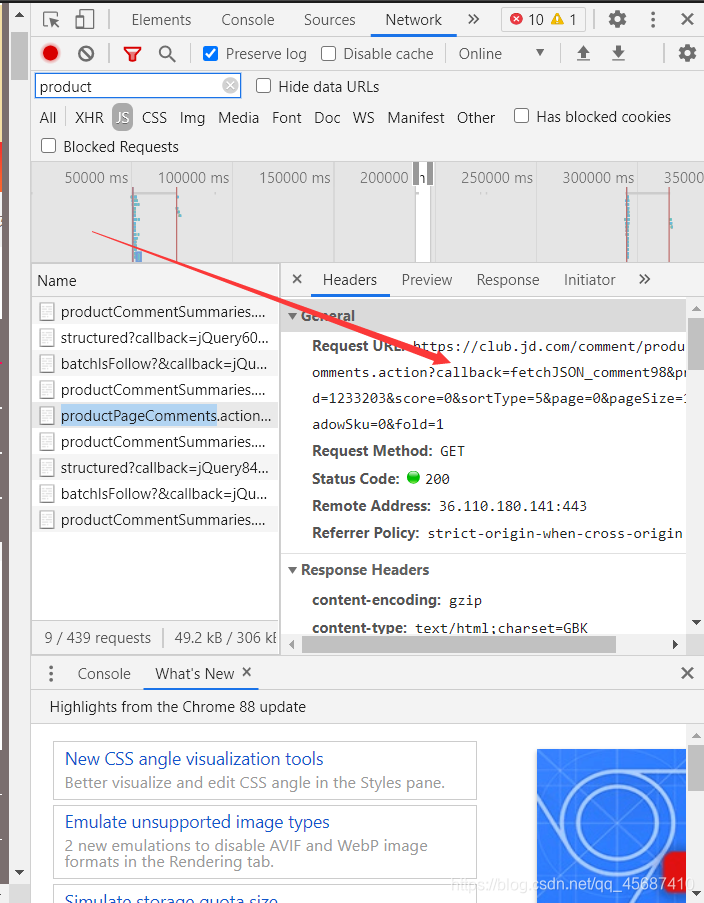 打开后发现是json数据,看到这里是不是头皮发麻,哈哈哈,不要慌!管它呢么多,咱们要的是文字的评论数据,直接使用正则就好了。有时不得不说,正则真的是很好用的。
打开后发现是json数据,看到这里是不是头皮发麻,哈哈哈,不要慌!管它呢么多,咱们要的是文字的评论数据,直接使用正则就好了。有时不得不说,正则真的是很好用的。 但是细心地同志会发现这个网页只有一部分的评论数据,这个时候怎么办呢,我们可以看看url,发现他携带了很多的参数。
但是细心地同志会发现这个网页只有一部分的评论数据,这个时候怎么办呢,我们可以看看url,发现他携带了很多的参数。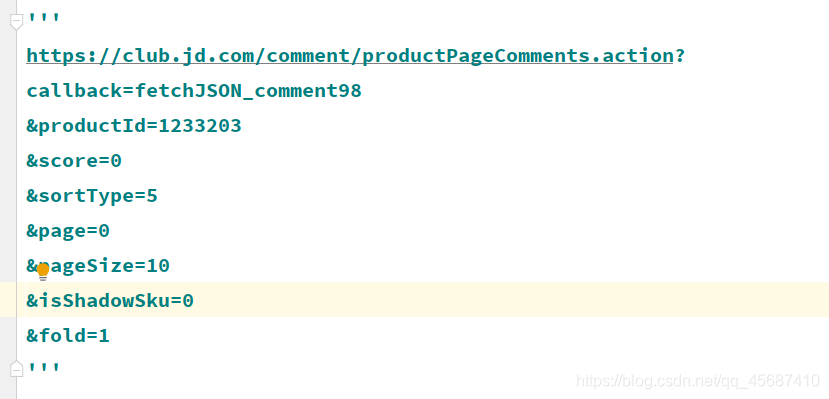 通过尝试,发现“score=0: 是所有评论, score=1是差评,score=2是中评,score=3是好评,page=0:代表的是评论的页数,”修改后访问url发现,的确如此!!!
通过尝试,发现“score=0: 是所有评论, score=1是差评,score=2是中评,score=3是好评,page=0:代表的是评论的页数,”修改后访问url发现,的确如此!!! 分析完毕! 通过分析我们需要,简单的对url进行动态变化再加上,基础爬虫和正则处理就可以拿到想要的数据了。
分析完毕! 通过分析我们需要,简单的对url进行动态变化再加上,基础爬虫和正则处理就可以拿到想要的数据了。 再对url进行动态处理,通过for循环来控制评论页数。
再对url进行动态处理,通过for循环来控制评论页数。 然后进行最基础的爬虫操作。------>>>>>携带请求头通过requests发起get请求。
然后进行最基础的爬虫操作。------>>>>>携带请求头通过requests发起get请求。 再进行正则匹配操作就好。------>>>正则表达式这边是向别人学习的
再进行正则匹配操作就好。------>>>正则表达式这边是向别人学习的 评论获取成功!!
评论获取成功!! 
【本文地址】