京东用户行为数据分析报告(python) |
您所在的位置:网站首页 › 京东的数据 › 京东用户行为数据分析报告(python) |
京东用户行为数据分析报告(python)
|
1. 背景与目的
该重构项目对京东的运营数据集的用户购买行为进行分析,研究用户过程中的行为特点、购物偏好、以及在购物过程中的转化率和流失情况,为精准营销提供高质量的目标群体。 2. 分析思路用户行为分析目的(根据目的拆解):促进用户购买商品、精准营销。 根据第3节数据集特点,从以下五个角度分析: 1) 京东用户整体行为信息 2) 用户行为漏斗分析 3) 留存分析 4) 用户购物行为偏好 5) 用户价值分析 3 数据概述 3.1 数据来源数据集来源:https://jdata.jd.com/html/detail.html?id=8 该数据集采用京东用户行为数据表(jdata_action),数据集构成如下: 处理完后的数据预览 可以增加渠道推广投入,进行精准人群推广,推出新用户福利,吸引新用户。推出分享有礼等活动促进老拉新,实现社交裂变;并且,定期进行促销活动保持老用户的活跃度。 根据每小时用户使用京东app时间特点,结合用户商品偏好,来开展营销活动。如在早上9点和晚上21点时候,进行整点秒杀等活动。在用户访问高峰期,进行活动与通知推送,并推送用户感兴趣的商品吸引用户眼球,促进用户参与率与转化率。 结合用户购买行为路径,可以不断优化商品搜索功能与推荐功能,提高商品搜索与推荐准确度,提高用户下单转化率;优化首页布局与详情页展示页展现效果,促进用户下单;并且根据用户行为漏斗分析的结论,商品浏览->下单购买的转化率最高,因此提供一键购物等来简化购物步骤流程,提高用户下单率。另外,通过加购再消费的用户也很多,因此也可以进一步优化购物车下单体验,降低购物复杂度,并且结合用户购物车中的商品进行精准推荐。另外,大部分用户不是很热衷对购物体验进行反馈,可以设置一些奖励制度提高用户评论数,增大用用户粘性。 目前用户留存率情况相对稳定、健康,为了进一步提高留存率,可以推出定期秒杀活动、专享优惠券、签到有奖环节,并建立合理的用户积分体系,增加用户浏览时长和深度。 用户留存率情况稳定,但用户的复购率较低,说明平台的用户体验存在问题,需要进一步找出用户槽点,提高用户购物满意度,并优化售后体验;加强老用户召回机制,给老用户推送消息通知,给予老用户福利和购物补贴等,来换回用户。 通过RFM对用户进行分层,将用户分成不通过消费特点的用户群体,从而进行精细化营销,不同的客户群体使用不同的营销方法和策略。用有限的资源优先服务最重要的客户。 5 分析与指标构建 5.1用户整体行为分析用户行为要素 用户行为过程:访问、加购、下单、消费、关注、评论 用户行为属性:是否会员、是否付费、 时间范围:15天、天、周、时 时间变化趋势 根据第3节数据集特点,指标选择 增长类:用户数、消费用户数、跳失率、复购率 行为类:PV/UV、行为时间 交易类:订单数、下单人数、人均订单数、ARPPU 分析思路 1) 会员与非用户群体访问情况分析 2) 会员与非用户群体消费情况分析 3)会员与非用户群体访问、消费行为随着时间变化情况 5.1.1 京东用户基本行为数据总体用户行为情况 PV:6229177 UV:728959 日均访问量:389323.562 人均访问量:8.545 消费用户数:395874 消费用户数占比:54.307% 消费用户访问量:3918000 消费用户人均访问量:9.897% 消费访问量占比:62.898% 用户整体行为分布情况 跳失率:22.3%(2018年3月30日-2018年4月14日) 结论:相对健康。可以调整首页页面布局、优化用户产品体验,提高产品的吸引力。 用户消费行为 消费频次: 用户消费频次前10的客户: 复购率 2018年3月30日-2018年4月14日期间这两周时间的复购率: (消费过2次及2次以上的购买次数 / 所有购买次数)*100%=13.4% 结论 1) 从数值来看,用户的复购率不高。结合上面的用户消费频次分布可以看出,很多用户购买了一次商品后就没有再进行消费。因此应该加强老用户召回机制,如给老用户发送推送通知、给予购物补贴等,并提升用户购物体验来促进用户消费。 2) 复购率水平要和相应同比、环比周期相比,也要与业内其他公司的复购率水平比较。 5.1.2 用户行为随时间的变化情况随天数变化 每日浏览量
日消费人数占比 简单地把有过一次操作的用户都视为活跃用户,则日消费人数占比 = 日消费次数 / 日活跃人数 用户操作随小时变化情况 PV随小时变化 考虑不同用户操作路径之间的转化率。 用户操作抽象出以下路径: 浏览->付款 浏览->加购->付款 浏览->收藏->付款 浏览->收藏->加购->付款 则不同用户路径的转化率为: 浏览->购买 2)可以优化商品搜索功能,提高商品搜索准确度、易用性,减少用户搜索时间。根据用户喜好在首页进行商品推荐,优化重排商品详情展示页,提高顾客下单欲望,提供一键购物等简化购物步骤的功能,客服也可以留意加购及关注用户,适时推出优惠福利及时解答用户问题,引导用户购买以进一步提高转化率。 5.3 留存分析留存行为分析要点 时间范围:选择次日、7日、14日 起始行为:3月30日起该天有过操作的用户数 回访行为:又有过操作的用户数 分析思路 新增用户在次日、7日、14天的留存率不同用户群体整体留存率判断高留存率用户行为特征根据特征调整策略时间范围:次日、7日、14天留存 参考Facebook的留存率“40–20–10”规则,因平台是电商平台,次日留存率离40%具有一定举例,但可以看出次日留存率、周留存率和14日留存率较为稳定和健康,用户对于平台具有一定依赖性。 因平台发展已经到达稳定阶段,用户保留率不会发生较大波动,数据量足够的情况下可以以年为单位,计算按月的留存率。另外,可以合理安排消息推送来唤醒流失用户。还日常维护好用户积分体系,推出签到有奖等机制提高用户粘性,进一步提高留存率。 5.4 商品偏好商品类别总数: 239007种商品。 销量最高的商品种类: 由于缺少M(金额)列,仅通过R(最近一次购买时间)和F(消费频率)对用户进行价值分析: RF用户类型11重要价值客户10重要发展客户、新客户01重要保持客户00一般挽留客户通过计算,得到以下结果: 用户消费 # 单个用户消费总次数 total_buy_count = (df[df['type']=='pay'].groupby(['user_id'])['type'].count() .to_frame().rename(columns={'type':'total'})) # 消费次数前10客户 topbuyer10 = total_buy_count.sort_values(by='total',ascending=False)[:10] # 复购率 re_buy_rate = total_buy_count[total_buy_count>=2].count()/total_buy_count.count() # 消费频次前10 topbuyer10.reset_index().style.bar(color='skyblue',subset=['total']) # 单用户消费次数分布 tbc_box = total_buy_count.reset_index() fig, ax = plt.subplots(figsize=[16,6]) ax.set_yscale("log") sns.countplot(x=tbc_box['total'],data=tbc_box,palette='Set1') for p in ax.patches: ax.annotate('{:.3f}%'.format(100*p.get_height()/len(tbc_box['total'])), (p.get_x() - 0.1, p.get_height())) plt.title('用户消费总次数')随时间变化 消费 # 日活跃人数(有一次操作即视为活跃) daily_active_user = df.groupby('date')['user_id'].nunique() # 日消费人数 daily_buy_user = df[df['type'] == 'pay'].groupby('date')['user_id'].nunique() # 日消费人数占比 proportion_of_buyer = daily_buy_user / daily_active_user # 日消费总次数 daily_buy_count = df[df['type'] == 'pay'].groupby('date')['type'].count() # 消费用户日人均消费次数 consumption_per_buyer = daily_buy_count / daily_buy_user # 可视化 # 柱状图数据 pob_bar = (pd.merge(daily_active_user,daily_buy_user,on='date').reset_index() .rename(columns={'user_id_x':'日活跃人数','user_id_y':'日消费人数'}) .set_index('date').stack().reset_index().rename(columns={'level_1':'Variable',0: 'Value'})) # 线图数据 pob_line = proportion_of_buyer.reset_index().rename(columns={'user_id':'Rate'}) fig1 = plt.figure(figsize=[16,6]) ax1 = fig1.add_subplot(111) ax2 = ax1.twinx() sns.barplot(x='date', y='Value', hue='Variable', data=pob_bar, ax=ax1, alpha=0.8, palette='Oranges') ax1.legend().set_title('') ax1.legend().remove() sns.pointplot(pob_line['date'], pob_line['Rate'], ax=ax2,markers='D', linestyles='--',color='sienna') # 打印出数值 x=list(range(0,16)) for a,b in zip(x,pob_line['Rate']): plt.text(a+0.1, b + 0.001, '%.2f%%' % (b*100), ha='center', va= 'bottom',fontsize=12) fig1.legend(loc='upper center',ncol=2) plt.title('日消费人数占比')浏览与访问 #每日浏览量 pv_daily = df[df['type'] == 'pv'].groupby('date')['user_id'].count() #每日访客数 uv_daily = df.groupby('date')['user_id'].nunique() # 可视化每日浏览 fig, ax = plt.subplots(figsize=[16,6]) sns.pointplot(pv_daily.index, pv_daily.values,markers='D', linestyles='--',color='limegreen') x=list(range(0,16)) for a,b in zip(x,pv_daily.values): plt.text(a+0.1, b + 2000 , '%i' % b, ha='center', va= 'bottom',fontsize=14) plt.title('每日浏览量') # 可视化每日访问 fig, ax = plt.subplots(figsize=[16,6]) sns.pointplot(uv_daily.index, uv_daily.values, markers='H', linestyles='--',color='darkgoldenrod') x=list(range(0,16)) for a,b in zip(x,uv_daily.values): plt.text(a+0.1, b + 500 , '%i' % b, ha='center', va= 'bottom',fontsize=14) plt.title('每日访客数')每小时访问情况 #每时浏览量 pv_hourly = df[df['type'] == 'pv'].groupby('hour')['user_id'].count() #每时访客数 uv_hourly = df.groupby('hour')['user_id'].nunique() # 用户操作行为随每小时变化 # PV随每小时变化 fig, ax = plt.subplots(figsize=[16,6]) sns.pointplot(pv_hourly.index, pv_hourly.values, markers='H', linestyles='--',color='turquoise') for a,b in zip(pv_hourly.index,pv_hourly.values): plt.text(a, b + 10000 , '%i' % b, ha='center', va= 'bottom',fontsize=12) plt.title('浏览量随小时变化') # UV随每小时变化 fig, ax = plt.subplots(figsize=[16,6]) sns.pointplot(uv_hourly.index, uv_hourly.values, markers='H', linestyles='--',color='y') for a,b in zip(uv_hourly.index,uv_hourly.values): plt.text(a, b + 1000 , '%i' % b, ha='center', va= 'bottom',fontsize=12) plt.title('访客数随小时变化') # 用户各操作随小时变化 type_detail_hour = pd.pivot_table(columns = 'type',index = 'hour', data = df,aggfunc=np.size,values = 'user_id') tdh_line = type_detail_hour.stack().reset_index().rename(columns={0: 'Value'}) tdh_line= tdh_line[~(tdh_line['type'] == 'pv')] # 可视化 fig, ax = plt.subplots(figsize=[16,6]) sns.pointplot(x='hour', y='Value', hue='type', data=tdh_line, linestyles='--', palette='muted') plt.title('用户操作随小时变化') 6.2 用户行为漏斗 df['action_time'] = pd.to_datetime(df['action_time'],format ='%Y-%m-%d %H:%M:%S') # 用户行为整体分布 type_dis = df['type'].value_counts().reset_index() type_dis['rate'] = round((type_dis['type'] / type_dis['type'].sum()),3) type_dis.style.bar(color='skyblue',subset=['rate']) # 不同行为之间的转化率 df_con = df[['user_id', 'sku_id', 'action_time', 'type']] df_pv = df_con[df_con['type'] == 'pv'] df_fav = df_con[df_con['type'] == 'fav'] df_cart = df_con[df_con['type'] == 'cart'] df_pay = df_con[df_con['type'] == 'pay'] df_pv_uid = df_con[df_con['type'] == 'pv']['user_id'].unique() df_fav_uid = df_con[df_con['type'] == 'fav']['user_id'].unique() df_cart_uid = df_con[df_con['type'] == 'cart']['user_id'].unique() df_pay_uid = df_con[df_con['type'] == 'pay']['user_id'].unique() pv_pay_df1 = pd.merge(left=df_pv, right=df_pay, how='inner', on=['user_id', 'sku_id'], suffixes=('_pv', '_pay')) # 浏览和加够行为的合并表浏览->关注->加购->付款的转化率漏斗 # 浏览->关注->加购->付款的转化率漏斗 pv_fav = pd.merge(left=df_pv, right=df_fav, how='inner', on=['user_id', 'sku_id'], suffixes=('_pv', '_fav')) pv_fav = pv_fav[pv_fav['action_time_pv'] 'n日后留存率':['次日留存率','7日留存率','14日留存率'], 'Rate':[the_1_day_retention_rate, the_7_day_retention_rate, the_14_day_retention_rate]}) # 可视化 fig, ax = plt.subplots(figsize=[6,5]) sns.barplot(x='n日后留存率', y='Rate', data=retention_rate, palette='Paired') x=list(range(0,3)) for a,b in zip(x,retention_rate['Rate']): plt.text(a, b + 0.001, '%.2f%%' % (b*100), ha='center', va= 'bottom',fontsize=12) plt.title('用户留存率') 6.4 商品销量分析 df['sku_id'].nunique() # 商品销量排行 sku_num = (df[df['type'] == 'pay'].groupby('sku_id')['type'].count().to_frame() .rename(columns={'type':'total'}).reset_index()) # 销量大于1000的商品 topsku = sku_num[sku_num['total'] > 1000].sort_values(by='total',ascending=False) # 可视化 topsku.set_index('sku_id').style.bar(color='skyblue',subset=['total']) 6.5 RFM 分析 buy_group = df[df['type']=='pay'].groupby('user_id')['date'] #将2018-04-13作为每个用户最后一次购买时间来处理 final_day = datetime.date(datetime.strptime('2018-04-14', '%Y-%m-%d')) #最近一次购物时间 recent_buy_time = buy_group.apply(lambda x:final_day-x.max()) recent_buy_time = recent_buy_time.reset_index().rename(columns={'date':'recent'}) recent_buy_time['recent'] = recent_buy_time['recent'].map(lambda x:x.days) #近十五天内购物频率 buy_freq = buy_group.count().reset_index().rename(columns={'date':'freq'}) RFM = pd.merge(recent_buy_time,buy_freq,on='user_id') RFM['R'] = pd.qcut(RFM.recent,2,labels=['1','0']) #天数小标签为1天数大标签为0 RFM['F'] = pd.qcut(RFM.freq.rank(method='first'),2,labels=['0','1']) #频率大标签为1频率小标签为0 RFM['RFM'] = RFM['R'].astype(int).map(str) + RFM['F'].astype(int).map(str) dict_n={'01':'重要保持客户', '11':'重要价值客户', '10':'重要发展客户', '00':'一般挽留客户'} #用户标签 RFM['用户等级'] = RFM['RFM'].map(dict_n) RFM_pie = RFM['用户等级'].value_counts().reset_index() RFM_pie['Rate'] = RFM_pie['用户等级'] / RFM_pie['用户等级'].sum() fig, ax = plt.subplots(figsize=[16,6]) plt.pie(RFM_pie['Rate'], labels = RFM_pie['index'], startangle = 90,autopct="%1.2f%%", counterclock = False,colors = ['yellowgreen', 'gold', 'lightskyblue', 'lightcoral']) plt.axis('square') plt.title('RFM用户分层') 7 参考参考来源2——知乎:https://zhuanlan.zhihu.com/p/298385597 参考来源——掘金:https://juejin.cn/post/6844904202590748679#heading-0 知乎淘宝用户行为分析:https://zhuanlan.zhihu.com/p/55244488 公众号用SQL分析: https://mp.weixin.qq.com/s?__biz=Mzg4OTUyMzY4OQ==&mid=2247490097&idx=1&sn=7789c5699aec955198861e5c035ed6a7&source=41 |
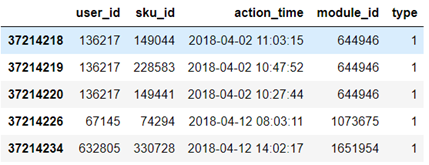 各字段的含义如下:
各字段的含义如下: 
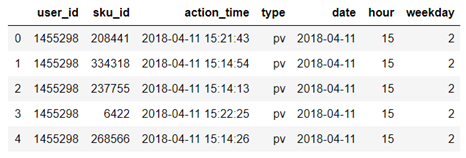
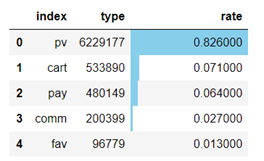 结论:用户整体行为中,有82.6%行为为浏览,实际支付操作仅占6.4。除此之外,用户评论及关注的行为占比也较低,说明大部分用户不是很热衷对购物体验进行反馈,应当增强网站有用户之间的互动,并且可以根据用户购物车内商品进行精准推送。提高评论数量和关注率,增大用户粘性。
结论:用户整体行为中,有82.6%行为为浏览,实际支付操作仅占6.4。除此之外,用户评论及关注的行为占比也较低,说明大部分用户不是很热衷对购物体验进行反馈,应当增强网站有用户之间的互动,并且可以根据用户购物车内商品进行精准推送。提高评论数量和关注率,增大用户粘性。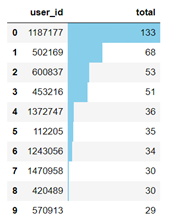 单个用户消费频次分析
单个用户消费频次分析  结论:可以看出绝大多数的用户消费次数为1次。可以增加推广、给予用户补贴优惠、完善购物体验等来提高用户消费次数。
结论:可以看出绝大多数的用户消费次数为1次。可以增加推广、给予用户补贴优惠、完善购物体验等来提高用户消费次数。 每日访客数
每日访客数  结论:每日访客数和每日浏览量曲线表现相符,都在4月4日这一天有所下降。经查发现4月4日这天为清明节前一天,因此各数据在当天有所下降。但是之后就逐渐回升。在清明节假期结束后,访客数量和浏览量继续升高。
结论:每日访客数和每日浏览量曲线表现相符,都在4月4日这一天有所下降。经查发现4月4日这天为清明节前一天,因此各数据在当天有所下降。但是之后就逐渐回升。在清明节假期结束后,访客数量和浏览量继续升高。 结论:可以看出,日消费人数都在20%以上。但在4月4日的时候消费人数骤减,通过时间查看可知这天是清明节,这一天消费人数占比降低。
结论:可以看出,日消费人数都在20%以上。但在4月4日的时候消费人数骤减,通过时间查看可知这天是清明节,这一天消费人数占比降低。 UV随小时变化
UV随小时变化  用户其他操作随小时变化情况
用户其他操作随小时变化情况  结论 1)访客数和浏览量随小时变化情况基本保持一致。在1点到5点之间,用户都在休息,因此整体活跃度很低。当用户逐渐醒来后,活跃度逐渐提升。在10点达到最高,之后略微回落趋于平稳。在18点的时候大多数人时间开始空闲,因此又迎来第二次增长,在晚上21点的时候达到高峰。因此可以在早上9点和晚上20点左右的时候进行一些活动与通知推送等,吸引用户眼球、促进用户参与率与转化率。 2)加入购物车和付款两条曲线贴合比比较紧密,说明大部分用户习惯加入购物车后直接购买。 3) 关注数相对较少,因此可以根据用户购物车内商品进行精准推送。评论数也相对较少,说明大部分用户不是很热衷对购物体验进行反馈,可以设置一些奖励制度提高用户评论数,增大用用户粘性。
结论 1)访客数和浏览量随小时变化情况基本保持一致。在1点到5点之间,用户都在休息,因此整体活跃度很低。当用户逐渐醒来后,活跃度逐渐提升。在10点达到最高,之后略微回落趋于平稳。在18点的时候大多数人时间开始空闲,因此又迎来第二次增长,在晚上21点的时候达到高峰。因此可以在早上9点和晚上20点左右的时候进行一些活动与通知推送等,吸引用户眼球、促进用户参与率与转化率。 2)加入购物车和付款两条曲线贴合比比较紧密,说明大部分用户习惯加入购物车后直接购买。 3) 关注数相对较少,因此可以根据用户购物车内商品进行精准推送。评论数也相对较少,说明大部分用户不是很热衷对购物体验进行反馈,可以设置一些奖励制度提高用户评论数,增大用用户粘性。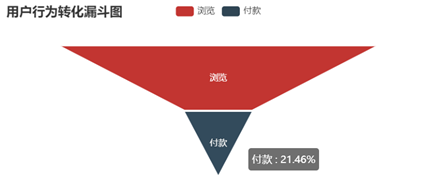 浏览-加购-付款
浏览-加购-付款 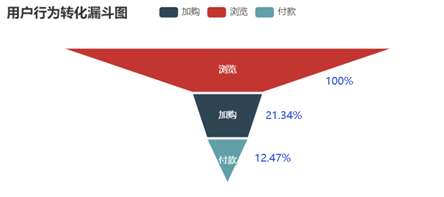 浏览-关注-付款
浏览-关注-付款 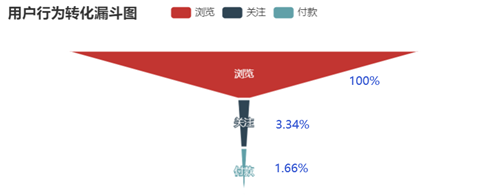 浏览-关注-加购-付款
浏览-关注-加购-付款 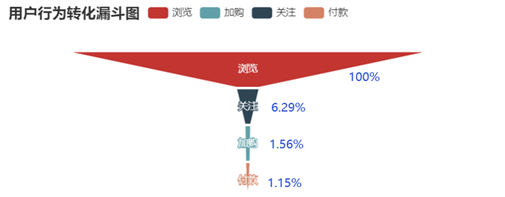 结论 1)比较四种不同的转化方式,最有效的转化路径为浏览直接付款转化率为21.46%,其次为浏览加购付款,转化率为12.47%。可以发现随着结算方式越来越复杂转化率越来越低。加购的方式比关注后购买的方式转化率要高,推其原因为购物车接口进入方便且可以做不同商家比价用,而关注则需要更繁琐的操作才可以查看到商品,因此转化率较低。
结论 1)比较四种不同的转化方式,最有效的转化路径为浏览直接付款转化率为21.46%,其次为浏览加购付款,转化率为12.47%。可以发现随着结算方式越来越复杂转化率越来越低。加购的方式比关注后购买的方式转化率要高,推其原因为购物车接口进入方便且可以做不同商家比价用,而关注则需要更繁琐的操作才可以查看到商品,因此转化率较低。 结论 留存率反应了产品健康程度和保留用户的能力。当前次日留存率是24.87%,7日留存率是18.55%,14日留存率是16.74%。
结论 留存率反应了产品健康程度和保留用户的能力。当前次日留存率是24.87%,7日留存率是18.55%,14日留存率是16.74%。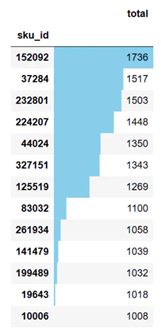 结论:在计算周期内超过1000次以上的共有13种商品。可以增加这13种商品的库存与在线数,并针对这13种商品做相应的推广与活动,吸引用户购买。
结论:在计算周期内超过1000次以上的共有13种商品。可以增加这13种商品的库存与在线数,并针对这13种商品做相应的推广与活动,吸引用户购买。 结论: 1) 不同类型的用户占比差异较小,应首先提升重要价值客户占比。 2) 对于重要价值用户来说,他们是最优质的的用户,应该给予资源倾斜,这部分用户群体占最高的27.6%,表现还不错。需要加强该用户群体粘性,通过提高该用户群体使用京东app的满意度,发放一些特别福利回馈他们来维系。另一方便,需要从其他类型的用户转化而来。 3) 对于重要发展客户,他们最近消费过,但消费频次低,这部分客户占26.19%,是第二多的群体,另外他们也可能是新用户。这部分用户忠诚度较高但购买力度不足,因此需要提高该用户群体的使用时间与消费频次。可以针对改群体设计调查问卷,了解痛点不断优化产品体验提升留存率。在消费上,可以通过交叉销售、更精确的商品推荐、发放优惠券、赠品和促销信息等方式提升消费频次,将他们转化为重要价值用户。 4) 对于重要保持客户,他们消费频率高,但最近一段时间没有使用app,有流失的风险。需要都关注该类型用户的购物习惯做精准营销,并通过消息推送系列活动、上新等方式唤醒和召回用户,提升用户的留存率,减少用户流失。 5) 对于一般挽留用户,可以定期发送邮件或短息换回,争取将他们转化为重要保持客户和重要招呼客户。
结论: 1) 不同类型的用户占比差异较小,应首先提升重要价值客户占比。 2) 对于重要价值用户来说,他们是最优质的的用户,应该给予资源倾斜,这部分用户群体占最高的27.6%,表现还不错。需要加强该用户群体粘性,通过提高该用户群体使用京东app的满意度,发放一些特别福利回馈他们来维系。另一方便,需要从其他类型的用户转化而来。 3) 对于重要发展客户,他们最近消费过,但消费频次低,这部分客户占26.19%,是第二多的群体,另外他们也可能是新用户。这部分用户忠诚度较高但购买力度不足,因此需要提高该用户群体的使用时间与消费频次。可以针对改群体设计调查问卷,了解痛点不断优化产品体验提升留存率。在消费上,可以通过交叉销售、更精确的商品推荐、发放优惠券、赠品和促销信息等方式提升消费频次,将他们转化为重要价值用户。 4) 对于重要保持客户,他们消费频率高,但最近一段时间没有使用app,有流失的风险。需要都关注该类型用户的购物习惯做精准营销,并通过消息推送系列活动、上新等方式唤醒和召回用户,提升用户的留存率,减少用户流失。 5) 对于一般挽留用户,可以定期发送邮件或短息换回,争取将他们转化为重要保持客户和重要招呼客户。【本文地址】
今日新闻 |
推荐新闻 |