Selenium实战之Python+Selenium爬取京东商品数据 |
您所在的位置:网站首页 › 京东sku数量 › Selenium实战之Python+Selenium爬取京东商品数据 |
Selenium实战之Python+Selenium爬取京东商品数据
|
实战目标:爬取京东商品信息,包括商品的标题、链接、价格、评价数量。 代码核心在于这几个部分: 其一:使用元素定位来获取页面上指定需要抓取的关键字;其二:将页面上定位得到的数据永久存储到本地文件中。具体来梳理一下从访问URL开始到爬取数据整个流程下来的各个节点我们都做了哪些工作。 爬取京东商品数据具体过程分析 1、准备接口数据 # 京东商城网址 url = 'https://www.jd.com/' 2、创建浏览器实例对象 # driver = webdriver.Firefox() # 创建 Firefox 浏览器实例对象 # driver = webdriver.Ie() # 创建 IE 浏览器实例对象 # driver = webdriver.Edge() # 创建 Edge 浏览器实例对象 # driver = webdriver.Safari() # 创建 Safari 浏览器实例对象 # driver = webdriver.Opera() # 创建 Opera 浏览器实例对象 driver = webdriver.Chrome() # 创建 Chrome 浏览器实例对象通过 webdriver.Chrome() 创建浏览器实例对象后,会启动Chrome浏览器。在 Chrome() 方法中未传入任何参数,即默认使用参数 executable_path="chromedriver" ,executable_path表示的是浏览器驱动的位置,该参数默认浏览器驱动的位置是在Python安装目录下。如果浏览器驱动位置与默认位置不同,则 executable_path 参数需要传入驱动的实际位置,如: driver = webdriver.Chrome(executable_path="D:/driver/chromedriver.exe") 2、访问URL # 浏览器访问地址 drver.get(url)打开浏览器后driver调用get(url) 方法在地址栏中访问该网址。相当于在地址栏输入URL回车打开网址。 3、隐式等待、最大化浏览器窗口 # 隐式等待,确保动态内容节点被完全加载出来——时间感受不到 drver.implicitly_wait(3) # 最大化浏览器窗口,主要是防止内容被遮挡 drver.maximize_window()先使用 implicitly_wait() 方法隐式等待浏览器将页面完全加载出来,再使用maximize_window()将浏览器窗口最大化,防止页面元素未加载出来或被遮挡而查找失败。 3、定位搜索框 # 通过id=key定位到搜索框 input_search = drver.find_element_by_id('key') # 在输入框中输入“口罩” input_search.send_keys(keyword) # 模拟键盘回车Enter操作进行搜索 input_search.send_keys(Keys.ENTER) # 强制等待3秒 sleep(3)driver 先调用 find_element_by_id('key') 通过ID定位到该搜索框,再调用 sent_keys() 传入参数搜索关键字 keyword ,然后在sent_keys() 中传入 Keys.ENTER 模拟键盘回车键,最后再调用 sleep(3) 强制等待搜索内容加载出来。至此, 定位搜索框->搜索框输入关键字->回车搜索 ,整个搜索流程就完成了。 4、定位元素(商品的标题、链接、价格、评价数量) # 获取当前第一页所有商品的li标签 goods = driver.find_elements_by_class_name('gl-item') for good in goods: # 获取商品标题 title = good.find_element_by_css_selector('.p-name em').text.replace('\n', '') # 获取商品链接 link = good.find_element_by_tag_name('a').get_attribute('href') # 获取商品价格 price = good.find_element_by_css_selector('.p-price strong').text.replace('\n', '') # 获取商品评价数量 commit = good.find_element_by_css_selector('.p-commit a').textdriver 通过调用 find_elements_by_class_name('gl-item') 方法定位 class=“gl-item” 到该页面所有商品的 标签,再接着遍历所有的 标签,分别通过不同定位方式查找到商品链接、商品标题、商品价格以及商品评价数量。 定位商品标题:通过 CSS选择器 定位到该元素标签,再调用其属性 text 获取到标签内的文本内容(即商品标题),最后使用 replace() 方法使用 空字符串 代替 换行符 以达到去掉标题中的换行符的目的,这样完整的商品标题就成功获取了。 # 获取商品标题名称 title = good.find_element_by_css_selector('.p-name em').text.replace('\n', '')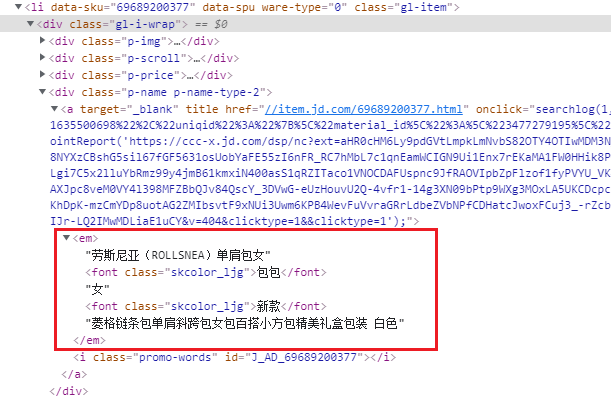 定位商品链接:通过先定位 标签再指定获取其属性 href 的值,最终获取到商品的链接。 # 获取商品链接 link = good.find_element_by_tag_name('a').get_attribute('href') 定位商品价格:通过 CSS选择器 定位到该元素标签,再调用其属性 text 获取到标签内的文本内容(即商品价格),最后使用 replace() 方法使用 空字符串 代替 换行符 以达到去掉文本中的换行符的目的,这样完整的商品价格就成功获取了。 # 获取商品价格 price = good.find_element_by_css_selector('.p-price strong').text.replace('\n', '')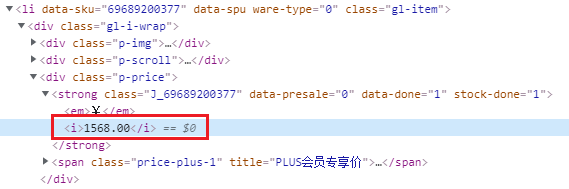 定位商品评论数量:通过 CSS选择器 定位到该元素标签,再调用其属性 text 获取到标签内的文本内容(即商品价格)。 # 获取商品评价数量 commit = good.find_element_by_css_selector('.p-commit a').text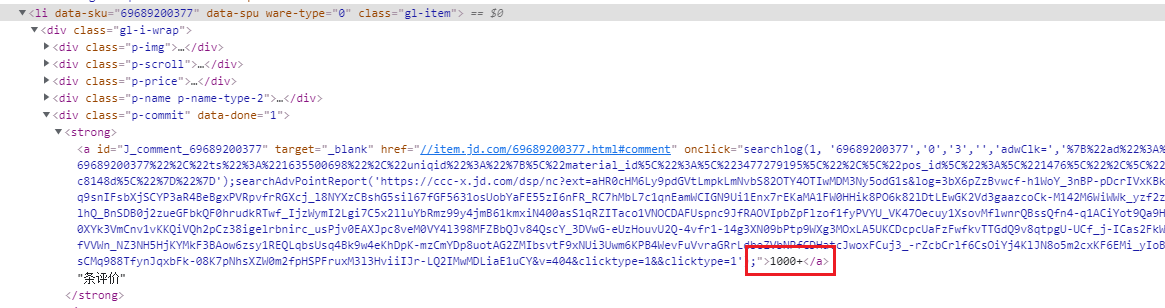 5、将商品数据存储到文件中
5、将商品数据存储到文件中
①存储到txt文件中 # 获取当前文件路径 paths = path.dirname(__file__) # 将当前文件路径与文件名拼接起来作为商品数据的存储路径 file = path.join(paths, 'good.txt') # 以追加写入的方式将商品数据保存到文件中 with open(file, 'a+', encoding='utf-8', newline='') as wf: wf.write(msg)②存储到CSV文件中 # 表头 header = ['商品标题', '商品价格', '商品链接', '评论量'] # 获取当前文件路径 paths = path.dirname(__file__) # 将当前文件路径与文件名拼接起来作为商品数据的存储路径 file = path.join(paths, 'good_data.csv') # 以追加写入的方式将商品数据保存到文件中 with open(file, 'a+', encoding='utf-8', newline='') as wf: f_csv = csv.DictWriter(wf, header) f_csv.writeheader() f_csv.writerows(data) 6、退出浏览器 # 退出关闭浏览器 drver.quit()抓取完商品数据后就可以直接将浏览器关闭,释放资源了。这就是整个爬取的过程,而抓取数据的过程再接着继续分析。 完整示例代码 ①存储到txt文件中 # -*- coding: utf-8 -*- # @Time : 2021/10/26 17:35 # @Author : Jane # @Software: PyCharm # 导入库 from time import sleep from selenium import webdriver from selenium.webdriver.common.keys import Keys # 键盘按键操作 from os import path # 京东商城网址 url = 'https://www.jd.com/' # 创建浏览器对象 driver = webdriver.Chrome() # 浏览器访问地址 driver.get(url) # 隐式等待,确保动态内容节点被完全加载出来——时间感受不到 driver.implicitly_wait(3) # 最大化浏览器窗口,主要是防止内容被遮挡 driver.maximize_window() # 通过id=key定位到搜索框 input_search = driver.find_element_by_id('key') # 在输入框中输入“口罩” input_search.send_keys('女士包包') # 模拟键盘回车Enter操作进行搜索 input_search.send_keys(Keys.ENTER) # 强制等待3秒 sleep(3) # 获取当前第一页所有商品的li标签 goods = driver.find_elements_by_class_name('gl-item') for good in goods: # 获取商品链接 link = good.find_element_by_tag_name('a').get_attribute('href') # 获取商品标题名称 title = good.find_element_by_css_selector('.p-name em').text.replace('\n', '') # 获取商品价格 price = good.find_element_by_css_selector('.p-price strong').text.replace('\n', '') # 获取商品评价数量 commit = good.find_element_by_css_selector('.p-commit a').text msg = ''' 商品:%s 链接:%s 价格:%s 评论:%s '''%(title, link, price, commit) # 获取当前文件路径 paths = path.dirname(__file__) # 将当前文件路径与文件名拼接起来作为商品数据的存储路径 file = path.join(paths, 'good.txt') # 以追加写入的方式将商品数据保存到文件中 with open(file, 'a+', encoding='utf-8', newline='') as wf: wf.write(msg) # 退出关闭浏览器 driver.quit() ②存储到CSV文件中 # -*- coding: utf-8 -*- # @Time : 2021/10/26 17:35 # @Author : Jane # @Software: PyCharm # 导入库 from time import sleep from selenium import webdriver from selenium.webdriver.common.keys import Keys # 键盘按键操作 from os import path import csv # 京东商城网址 url = 'https://www.jd.com/' # 创建浏览器对象 driver = webdriver.Chrome() # 浏览器访问地址 driver.get(url) # 隐式等待,确保动态内容节点被完全加载出来——时间感受不到 driver.implicitly_wait(3) # 最大化浏览器窗口,主要是防止内容被遮挡 driver.maximize_window() # 通过id=key定位到搜索框 input_search = driver.find_element_by_id('key') # 在输入框中输入“口罩” input_search.send_keys('女士包包') # 模拟键盘回车Enter操作进行搜索 input_search.send_keys(Keys.ENTER) # 强制等待3秒 sleep(3) # 获取当前第一页所有商品的li标签 goods = driver.find_elements_by_class_name('gl-item') for good in goods: # 获取商品链接 link = good.find_element_by_tag_name('a').get_attribute('href') # 获取商品标题名称 title = good.find_element_by_css_selector('.p-name em').text.replace('\n', '') # 获取商品价格 price = good.find_element_by_css_selector('.p-price strong').text.replace('\n', '') # 获取商品评价数量 commit = good.find_element_by_css_selector('.p-commit a').text msg = ''' 商品:%s 链接:%s 价格:%s 评论:%s '''%(title, link, price, commit) # 表头 header = ['商品标题', '商品价格', '商品链接', '评论量'] # 获取当前文件路径 paths = path.dirname(__file__) # 将当前文件路径与文件名拼接起来作为商品数据的存储路径 file = path.join(paths, 'good_data.csv') # 以追加写入的方式将商品数据保存到文件中 with open(file, 'a+', encoding='utf-8', newline='') as wf: f_csv = csv.DictWriter(wf, header) f_csv.writeheader() f_csv.writerows(data) # 退出关闭浏览器 driver.quit() ③将代码进行封装 # -*- coding: utf-8 -*- # @Time : 2021/10/26 17:35 # @Author : Jane # @Software: PyCharm # 导入库 from time import sleep from selenium import webdriver from selenium.webdriver.common.keys import Keys # 键盘按键操作 from os import path import csv def spider(url, keyword): # 创建浏览器对象 drver = webdriver.Chrome() # 浏览器访问地址 drver.get(url) # 隐式等待,确保动态内容节点被完全加载出来——时间感受不到 drver.implicitly_wait(3) # 最大化浏览器窗口,主要是防止内容被遮挡 drver.maximize_window() # 通过id=key定位到搜索框 input_search = drver.find_element_by_id('key') # 在输入框中输入“口罩” input_search.send_keys(keyword) # 模拟键盘回车Enter操作进行搜索 input_search.send_keys(Keys.ENTER) # 强制等待3秒 sleep(3) # 抓取商品数据 get_good(drver) # 退出关闭浏览器 drver.quit() # 抓取商品数据 def get_good(driver): # 获取当前第一页所有商品的li标签 goods = driver.find_elements_by_class_name('gl-item') data = [] for good in goods: # 获取商品链接 link = good.find_element_by_tag_name('a').get_attribute('href') # 获取商品标题名称 title = good.find_element_by_css_selector('.p-name em').text.replace('\n', '') # 获取商品价格 price = good.find_element_by_css_selector('.p-price strong').text.replace('\n', '') # 获取商品评价数量 commit = good.find_element_by_css_selector('.p-commit a').text # 将商品数据存入字典 good_data = { '商品标题':title, '商品价格':price, '商品链接':link, '评论量':commit } data.append(good_data) saveCSV(data) # 保存商品数据到CSV文件中 def saveCSV(data): # 表头 header = ['商品标题', '商品价格', '商品链接', '评论量'] # 获取当前文件路径 paths = path.dirname(__file__) # 将当前文件路径与文件名拼接起来作为商品数据的存储路径 file = path.join(paths, 'good_data.csv') # 以追加写入的方式将商品数据保存到文件中 with open(file, 'a+', encoding='utf-8', newline='') as wf: f_csv = csv.DictWriter(wf, header) f_csv.writeheader() f_csv.writerows(data) # 判断文件程序入口 if __name__ == '__main__': # 京东商城网址 url = 'https://www.jd.com/' # 搜索关键字“女士编包” keyword = '女士包包' # 爬取数据 spider(url, keyword) |
【本文地址】
今日新闻 |
推荐新闻 |