亚马逊首席科学家演讲全文,揭秘深度学习语音识别 |
您所在的位置:网站首页 › 亚马逊alexa的功能 › 亚马逊首席科学家演讲全文,揭秘深度学习语音识别 |
亚马逊首席科学家演讲全文,揭秘深度学习语音识别
|
今天我要谈谈Alexa的深度学习技术。我会先介绍一下Alexa,然后再说明我们如何将深度学习应用于处理如此大规模的数据,之后我将介绍语音识别和语句合成的技术细节,这是我们主要应用深度学习的两个领域。今天我在这里不是为了讲技术具体原理,所以如果你们希望听的是技术处理的细节,或许在下午的活动中会更开心。最后我将谈谈我们与业界和学界的伙伴合作的其他项目。
起初是这样的,几年前我们发布了Amazon Echo的第一版。我们从小范围做起,限量发布,希望能在大范围公开前先看看使用效果。用户很明确也很快地反馈了他们喜欢我们的产品,反响来得之快远出乎我们意料。从这个起点开始,转眼Amazon Echo设备销量已达到几百万。人们对此很感兴趣,想听我讲更多我们把产品从小做到大、从默默无闻做到具有巨大商业价值的过程。 总之,我们将这个产品做了个扩展,做了个更小的版本,Echo Dots,也是无线设备。顺便提一句,活动结束后,你们可以在我们的展台试用这些产品。去年圣诞期间新加入了白色版本。不只如此,Fire TV、Fire平板电脑,还有其他一些第三方设备上,也可以下载到内建Alexa技术的产品,我们提供了声音识别技术植入它们的API。连手表都用我们的技术,弄得我都想要这种手表了。
以上是植有Alxea技术的一些电子产品。还有很多是智能家居设备,不仅有声音感应功能,而且是由Alexa来进行控制。我最喜欢的是灯的开关。就像我家的那种开关,都是智能的,所以在家经常能听到我说“Alexa,把厨房灯打开”一类的话。其实这个场景看起来挺傻的,因为其实我就站在开关旁边。当然它也可以这么用,比如上楼时,我就说,“楼上的灯,亮!”,很有趣。我家的电视也有这个功能,所以我会说“Alexa,打开电视”。你真应该来看看。
我们扩展的另一个领域,是Alexa可实现的功能。也许你们没有读到新闻,我们最近的成果是,Alexa已经有超过一万项技能了。功能可以由第三方来开发,不用我们亲自来。我们有供第三方使用的API,来让开发者给Alexa加入各种各样的技能,以丰富用户体验。 以上我说的这些,都让Alexa的应用越来越广,也意味着我们收集的数据越来越多。正如我开始说的,我们已经卖出了几百万台设备,应用于各种各样的场景。有时候你根本不知道人们用它来做什么,毕竟上万种功能,我不可能熟知每一种。但我知道,人们很喜欢这个产品。我在这个产业里的时间很长了,我曾经做过人们根本不爱用的系统。所以如今,得到人们的喜爱,让我很庆幸能继续做我所做的。我总是收到各种各样的邮件和亚马逊上的高分评价说他们多么喜欢我们的产品,这意味着我们的产品是真真切切在被使用着,每天都有大量数据在产生着。所以,我们需要从这些数据中学习,这就让我们面临学习方法的巨大挑战——机器学习。
大规模学习一题,我已经在去年AWS的一次演讲上谈过了。那次演讲的题目与今天相同,网上有录像可以找到。我们的语音数据量以小时为单位计算的话,以正常生活作比,是一个人成长16年所听到的语音量。因为除去睡觉、开车和干别的事,你真正在“听”话语的时间,只有一天的10%,16年就是14000小时。婴儿长到16岁,已经完全可以习得听懂谈话的能力了,于是有人拿这个数字来与我们的机器学习作比较。
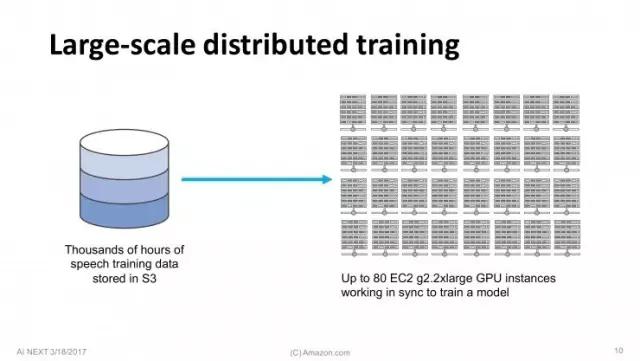
总之,我们有来自用户的几千小时的语音数据,储存在S3上。我们利用AWS EC2云的分布式GPU集群来训练深度学习模型。因为数据量大太,我们只能采用分布式训练法(Distributed training),多台GPU同时运行。这也是我们所面临的挑战。这是比较旧的幻灯片了,上面说我们用的是G2,但其实我们现在用的是更快的GPU了。
8台GPU同时运行,每个线程(Worker)都要和其它线程同步更新几百兆数据,一秒钟之内这个过程要发生多次。问题是,这种方法会迅速到达瓶颈,同步更新的数据量限制了训练无法进一步提升。这时候有几种解决方案,我们在Amazon所做的是:使用逼近算法(approximations)减少更新规模,压缩3个量级。
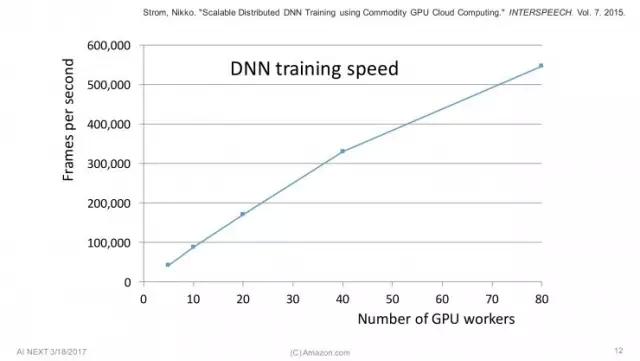
这张图表来自我们几年前发表的一篇论文。X轴是GPU线程数,Y轴是处理速度。可以看到我们最多时用了80个GPU。重点是,这条线几乎是直线。这意味着随着使用越来越多的GPU,训练速度就越快,呈线性增长,且并没有明显的饱和。一个有趣的事情是,图表右上方80台GPU的情况中,处理速度达到了55万帧/秒。翻译成通俗易懂的语言,就是每秒能处理30分钟量的语音。这就是为什么我想强调16年这个数字,一个人通过16年、14000小时学习的语音,我们在一天内就可以学会。 微软发布的号称超越人类的语音识别论文很厉害,但仔细想想,我们自身也是超越人类的,因为有这些资源可以使用。我们可以在一周内把14000小时的语音来回学习好几次,也可以花上16年——和我女儿一样大。 这是Alexa的基本原理,可以在此基础上接着来谈谈语音识别了。语音识别是一切的起点,如果语音识别不管用,那么整个系统就没法用,所以它真的非常重要。语音识别技术最近有很大提升,因为深度学习的应用,我们将来可以对语音识别有更多期待。
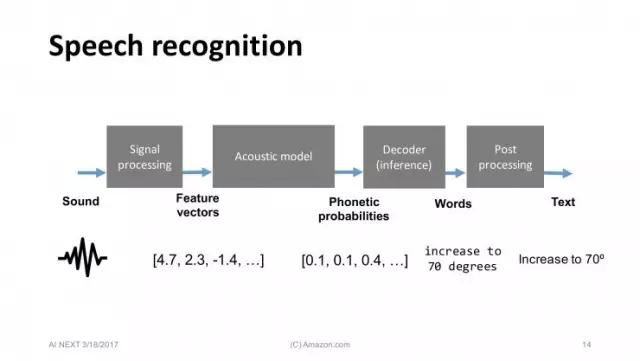
介绍一下标准的语音识别流程。这些数字描述的是要识别的语音的向量。接下来这个模型很重要,叫做听觉模型(Acoustic model)。它采用分类处理,以10毫秒级的速度处理向量、解决问题、分辨发音。接下来的也很重要,就是从数据库中搜索发音的可能结果,从而找出与目标语音片段中发音最像的词组,然后整理出结果。全部模型都是以机器学习和深度学习为基础构建的。 今天我想再多介绍一点,这是个好例子,甚至是第一个将深度学习用于语音识别的例子。它是一个分级器(classifier),输入向量,输出的是可能结果。这是一个缩小范围问题。这个过程有很多可谈的,但今天我将重点说说其中最有趣的一点。那就是深度神经网络在听觉模型的使用。 底部是接收的声音,然后经由一系列隐藏层将数据传输到终端,在那里寻找对应的语音。我们目前用的是英语语音库,已经在美国收集了几千小时的语音资料了。我们得到的模型很不错,虽然Amazon Echo是个远场设备(far field device),使这个过程更难实现,但我们的语音识别目前运行还不错。
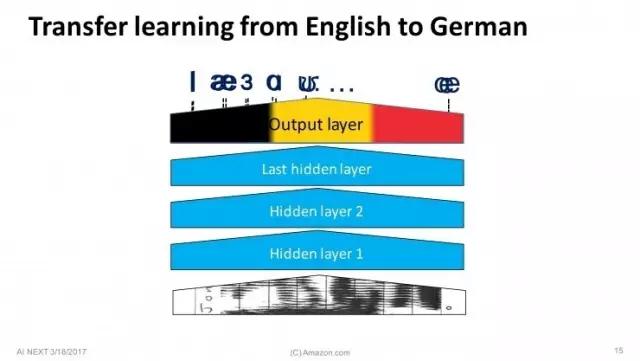
后来,去年的时候我们扩展到了德国。我们做了什么呢?显然我们的德语语音数据并不丰富,于是我们用了一种叫迁移学习(Transport Learning)的方法。迁移学习用传统方法很难做到,但用深度学习就很容易。其他层不变,不同只是将负责输出最终结果的最终层去掉,取而代之的是针对德语的最后一步处理。两种语言音素不一样,所以最终处理不同。只要以少量德语作为数据进行训练,就能得到不错的结果。
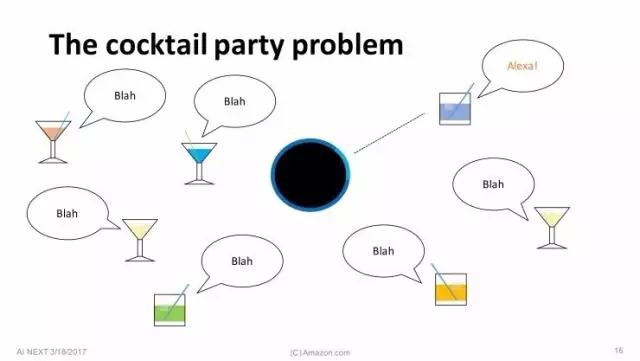
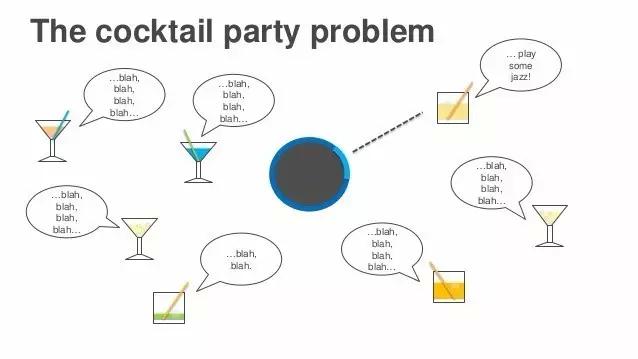
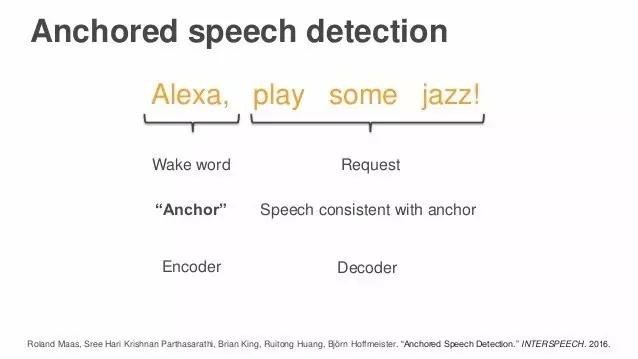
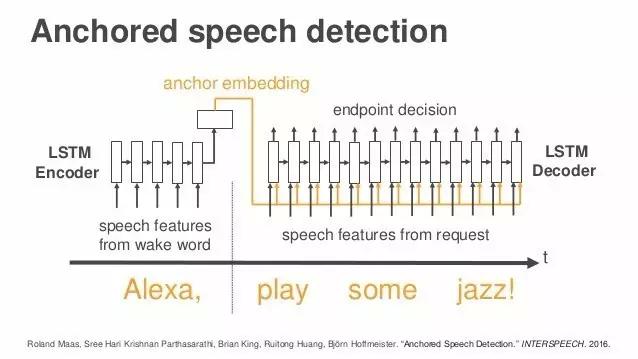
接下来我想说说语音识别中的鸡尾酒会效应。【编者注:鸡尾酒会效应(cocktail party effect)是由英国认知科学家Edward Colin Cherry于1953年提出的,指人类一种听力选择能力。人能够把注意力集中于一个声音刺激上,忽略其他背景音。】就像我说的一样,Alexa是个远场设备,使用时可能很多人同时在一个房间里。Alexa是唤醒词,当有人叫Alexa时,Alexa的麦克风就会顺着声音传来的方向去聆听。唤醒并不难,但接下来的难题是声音从四面八方来,对吗?这步就难多了,因为它是开放性的。周围可能有别人说了发音类似的词,也可能有别的谈话声干扰。最难处理的问题是,我们不知道话语什么时候停止,可能几个人话音刚落,旁边的人又开始发出声音,这会导致我们不知道该什么时候开始和停止处理音频。 我们解决这个难题的方法,叫做锚点语音探测(Anchored speech detection)。还记得我们遇到的问题吗——要判断说话者何时停止发言,即使是在周围有其他人也在说话的情况下。我们的做法是,用Alexa这个词作为锚点词(anchor word),然后寻找与发出这个词的声音特性相同的声音,以确定说话者。
从深度学习角度来讲,我们还有一种编码和解码的方法,第一步由编码完成,第二步用解码完成。我将在这里给你们展示一些细节。这里,你们可以看到一个公式,这是目前的神经网络的第一步用到的,唤醒词Alexa以及它的嵌入(embedding),这些编码描述的是说话者的声音特性。然后是第二步,要识别说话者何时结束,我们依旧用锚点词来定位,也就是当那个人说出“jazz”这个词的时候,就知道这句话已经结束了。虽然周围的声音仍在影响判断,但锚点嵌入(anchor embedding)可以告诉我们:“你需要聆听的那个人在那里。” 我没有进入太多细节,但是你们也许注意到了,幻灯片上有我们已发表的论文信息。不用急着拍照,感兴趣的朋友可以从之后论文中找到你们想要的信息。我还不知道要怎么发送给你们,但有兴趣的话可以之后再问我。
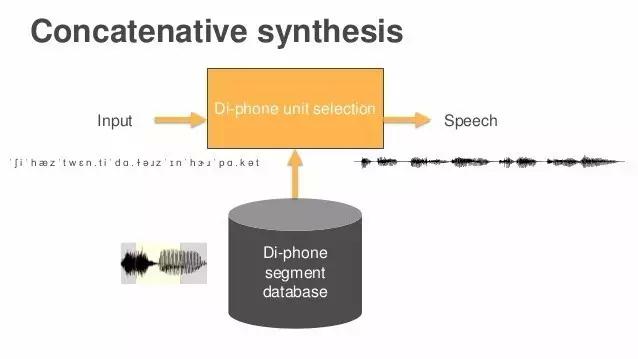
我今天想谈的第二个领域,就是语句合成。现在深度学习用以做很多自然语言处理的工作,今天我主要讲的是语音分析和语句合成。我认为Alexa目前做得很不错,我们还将在这两个领域投入更多资源。 我将以为大家演示一遍问题来结束。这里有一些文本,你希望Alexa说出它们——这是语音识别最后一步的倒序做法。我们将这些文本转化为字素,没有美元符号之类的任何符号,只有单词。然后再将字素转化为音素,由音标组成。现在文本变成了一堆音标,我们没法读出来,但是系统将读出来,这是最难的一步,将字串变为波形,成为真实可听的声音。来,请听——“她口袋里有20美元(She has 20 dollars in her pocket)。”哇,还真读出来了,不错,这就是Alexa的工作方式。 下面我要说说Alexa是怎么做到的。大部分高端系统是这样做的:找一个专业配音员,录下数小时他或她自然发音的音频,就得到了一个巨大的数据库。然后将所有片段和成分都进行标注,然而过程中会产生很多问题——哪里是高音?发音多长?这个音从哪个词发出的?对应的音标是什么?等等。收集到的音素会进入数据库,经过搜索最近似发音后,重组成一句连贯的语句,听起来就像一个人自然而然说出来的。
被切割的片段被称为“双连音片段”(Di-phone segment)
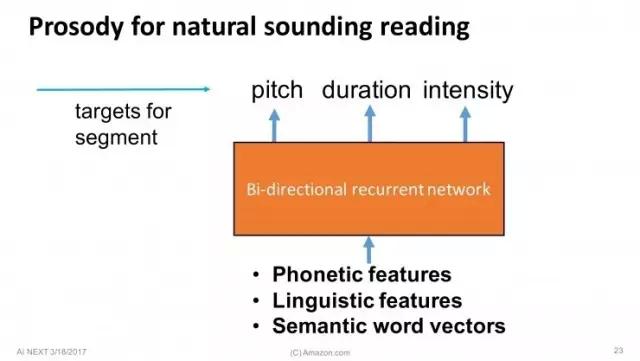
数据库里的音频有三个属性:音高(pitch)、时长(duration)、密度(intensity) 这个技术在业内已经被用了很久了,我想说的是我们的创新,即,交给深度学习来做这些事。比如现在你有一些音素和想说的词汇,你想找出数据库中符合的目标。例如在某个特定语境下,你希望最后发出的声音,音高达到120赫兹,时长达50毫秒,你只要直接搜索数据库中这种类型的片段,就可以合成出你想要的语句了。
|






 返回搜狐,查看更多
返回搜狐,查看更多【本文地址】
今日新闻 |
推荐新闻 |