spark |
您所在的位置:网站首页 › 云分为哪三层 › spark |
spark
|
学习目录
一、基本介绍二、举例说明1.写在一个scala文件中2.使用三层架构
一、基本介绍
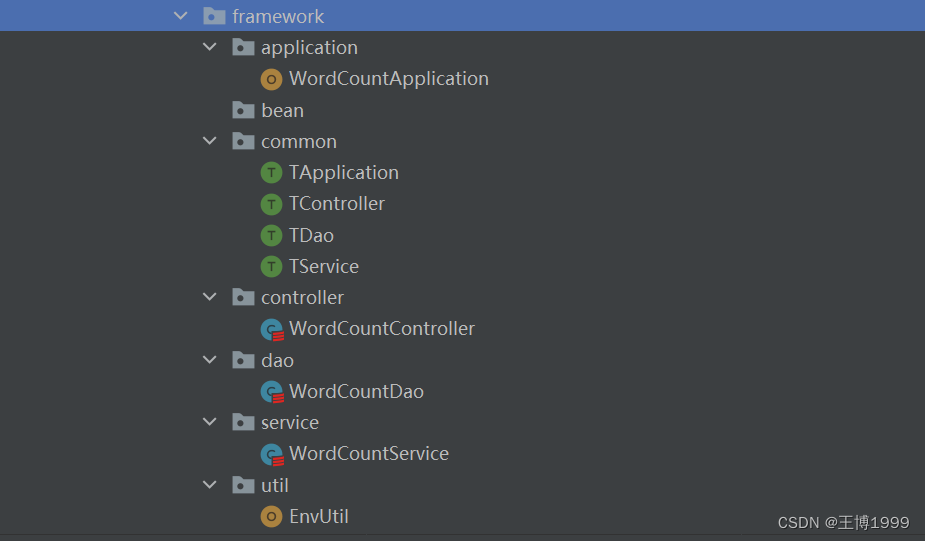
基本概念:三层架构分为controller(控制层)、service(服务层)、dao(持久层),区分层次的目的即为了高内聚低耦合的思想。 controller:主要负责对数据的调度 service:主要负责对数据的操作和逻辑 dao:主要负责对数据的读取,跟文件、数据库等打交道 高内聚: 再来介绍高内聚,很多人对低耦合比较了解,但对高内聚却没有很多的了解,这是因为你再实现低耦合的过程中,其实无意中已经实现了高内聚,但我们还是要对其有了解,高内聚,故名思意,极高的内部聚合,这个内聚是针对于类的成员方法,模块间的耦合已经降低了,但对于模块内部呢?也就是一个一个的类中呢?我们应该尽可能的减少一个成员方法所能做的事情,尽可能使它只做一件事。这对我们寻找程序的问题和升级一个功能来说也是很有利的,我们不需要再去一个方法中的功能,而是直接添加或者修改一个方法,不需要去担心参数的问题。参考文章 低耦合: 我们先来说低耦合,因为这个比较广为人知,低耦合是针对于各个模块之间的,我们在实现一个项目时,会把各种功能分开实现,封装成为一个一个模块,从而降低他们之间的耦合性,耦合就是类似于齿轮,我们熟知,一个一个的齿轮协同工作,虽然看起来非常完美,但一旦其中一个出现问题,就需要停掉所有服务,重新修理,这对维护和升级来说都是非常痛苦的一件事。所以,我们倡导尽可能降低耦合,注意,耦合是不可能被完全消除的,只能尽可能减低,并且,降低模块间的依赖也有助于进行单元测试。参考文章 高内聚低耦合 简单来说就是一段代码完成一个小功能,各执其职,尽量不要一段代码写多个功能;如果每个代码块之间相互联系非常紧密,则耦合性就会很高,功能的独立性就越差! 优点:阅读性好,易扩展 其他模块 application(应用层):所有的应用程序从application开始执行 common:存放通用的类和接口 util:存放工具类 bean:存放实体类 二、举例说明案例:wordCount 1.写在一个scala文件中 package com.bigdata.SparkCore.wc import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} /** * @author wangbo * @version 1.0 */ object wordcount3 { def main(args: Array[String]): Unit = { //Application //Spark框架 // TODO 建立和Spark框架的连接 //JDBC:Connection val sparkConf = new SparkConf().setMaster("local").setAppName("wordCount") val sc = new SparkContext(sparkConf) // TODO 执行业务操作 // 1.读取文件数据 val value: RDD[String] = sc.textFile("datas") // 2.拆分数据,形成一个个单词 val words: RDD[String] = value.flatMap(_.split(" ")) // 3.将数据进行分组统计 val value1: RDD[(String, Int)] = words.map((_, 1)) // 使用spark中rudeceByKey分组聚合 val value2: RDD[(String, Int)] = value1.reduceByKey(_ + _) // 5.将转换结果采集到控制台打印 val tuples: Array[(String, Int)] = value2.collect() tuples.foreach(println) // TODO 关闭连接 sc.stop() } } 2.使用三层架构包名和文件名 代码部分 WordCountApplication.scala package com.bigdata.SparkCore.framework.application import com.bigdata.SparkCore.framework.common.TApplication import com.bigdata.SparkCore.framework.controller.WordCountController /** * @author wangbo * @version 1.0 */ /** * 应用层 */ object WordCountApplication extends App with TApplication{ //APP特质中有main方法,所有不用写main方法了 //启动应用程 start(){ val wordCountController = new WordCountController() wordCountController.execute() } }TApplication.scala package com.bigdata.SparkCore.framework.common import com.bigdata.SparkCore.framework.util.EnvUtil import org.apache.spark.{SparkConf, SparkContext} /** * @author wangbo * @version 1.0 */ trait TApplication { /** * 函数的柯里化 * 第一个参数:可以也有默认值,也可以传参 * 第二个参数:控制抽象:将一段代码传入函数中 */ def start(Master:String="local[*]",AppName:String = "wordCount")(op : => Unit): Unit ={ val sparkConf = new SparkConf().setMaster(Master).setAppName(AppName) val sc = new SparkContext(sparkConf) EnvUtil.put(sc) try { op }catch { case ex => println(ex.getMessage) } // TODO 关闭连接 sc.stop() EnvUtil.clear } }TController.scala package com.bigdata.SparkCore.framework.common /** * @author wangbo * @version 1.0 */ trait TController { //调度功能 def execute() : Unit }TDao.scala package com.bigdata.SparkCore.framework.common import com.bigdata.SparkCore.framework.util.EnvUtil /** * @author wangbo * @version 1.0 */ trait TDao { def readFile(path:String)={ EnvUtil.take().textFile(path) } }TService.scala package com.bigdata.SparkCore.framework.common /** * @author wangbo * @version 1.0 */ trait TService { def dataAnalysis(): Any }WordCountController.scala package com.bigdata.SparkCore.framework.controller import com.bigdata.SparkCore.framework.common.TController import com.bigdata.SparkCore.framework.service.WordCountService /** * @author wangbo * @version 1.0 */ /** * 控制层 */ class WordCountController extends TController{ private val wordCountService = new WordCountService() //数据调度 def execute(): Unit ={ // TODO 执行业务操作 val array = wordCountService.dataAnalysis() array.foreach(println) } }WordCountDao.scala package com.bigdata.SparkCore.framework.dao import com.bigdata.SparkCore.framework.common.TDao /** * @author wangbo * @version 1.0 */ /** * 持久层 */ class WordCountDao extends TDao{ }WordCountService.scala package com.bigdata.SparkCore.framework.service import com.bigdata.SparkCore.framework.common.TService import com.bigdata.SparkCore.framework.dao.WordCountDao import org.apache.spark.rdd.RDD /** * @author wangbo * @version 1.0 */ /** * 服务层 */ class WordCountService extends TService{ private val wordCountDao = new WordCountDao() //数据分析 def dataAnalysis(): Array[(String, Int)] = { // 1.读取文件数据 val value= wordCountDao.readFile("datas/2.txt") val words: RDD[String] = value.flatMap(_.split(" ")) val value1: RDD[(String, Int)] = words.map((_, 1)) val value2: RDD[(String, Int)] = value1.reduceByKey(_ + _) val tuples: Array[(String, Int)] = value2.collect() tuples } }EnvUtil.scala package com.bigdata.SparkCore.framework.util import org.apache.spark.SparkContext /** * @author wangbo * @version 1.0 */ object EnvUtil { /** * ThreadLocal:可以对线程内存进行控制,存储数据,共享数据,但不能保证数据的安全性 * 创建一个工具类将sc传入,然后放到一个线程中供该线程整个过程使用 */ private val scLocal = new ThreadLocal[SparkContext]() //将sc传入 def put(sc:SparkContext):Unit = { scLocal.set(sc) } //将sc取出 def take():SparkContext = { scLocal.get() } //将sc清除 def clear: Unit ={ scLocal.remove() } } |
【本文地址】
今日新闻 |
推荐新闻 |