【机器学习】基于朴素贝叶斯的疾病预测模型 |
您所在的位置:网站首页 › 买车的计算方法有几种类型 › 【机器学习】基于朴素贝叶斯的疾病预测模型 |
【机器学习】基于朴素贝叶斯的疾病预测模型
|
【机器学习】基于朴素贝叶斯的疾病预测模型
目录 【机器学习】基于朴素贝叶斯的疾病预测模型 第1章 朴素贝叶斯 1.1 朴素贝叶斯简介 1.2 条件概率 1.3 朴素贝叶斯分类器 1.4 朴素贝叶斯分类器分类过程 1.5 朴素贝叶斯分类器在疾病分类中的难点 第2章 朴素贝叶斯的疾病预测模型 2.1 预测步骤 2.2 准备训练样本集 2.2.1 选取输入特征变量以及疾病类型标签 2.2.2 原始数据的合并 2.2.3 症状类、职业类数据消除特征冗余 2.2.4 数据的向量化处理 2.3 计算各种疾病的概率 2.4 计算各种疾病下各种症状/职业的概率 2.4.1 初始化数据 2.4.2 症状/职业样本数量的统计 2.4.3 收集数据、计算概率 2.4.4 获得概率数据 2.5 准备测试样本集 2.5.1 输入测试样本数据 2.5.2 测试样本数据向量化 2.5.3 测试样本对应概率匹配 2.5.4 测试样本获得对应概率 2.5.5 计算概率 2.5.6 比较概率,预测疾病类型 第3章 实验及结果分析 3.1 系统测试 3.2 结果展示 3.3 结果展示 3.3.1 测试样本输入合法 3.3.2 测试样本输入非法 3.4 结果分析 第1章 朴素贝叶斯本章将简单介绍基于概率论的分类方法,即朴素贝叶斯的基础概念以及基本特性。 1.1 朴素贝叶斯简介朴素贝叶斯是贝叶斯决策理论的一部分。其特点是:在数据较少的情况下仍然有效,可也处理多类别问题,但对于输入数据的准备方式较为敏感,适用标称型数据。 朴素贝叶斯的过程主要分为两个阶段。第一阶段,对实验样本进行分类,分别计算不同条件下其概率。第二阶段,输入测试样本,计算不同条件其概率,比较其概率大小,从而完成对测试样本的分类。下图显示两类实验样本的概率分布情况。
图1-1 两个实验样本已知概率分布 1.2 条件概率实现样本的分类,需要通过计算条件概率而得到,计算条件概率的方法称为贝叶斯准则。 条件概率的计算方法:
其中P(A|B)代表条件B下,结果A发生的概率,P(B|A)代表条件A下,结果B发生的概率,P(B)代表条件B发生的概率,P(A)代表条件A发生的概率。 当条件与结果发生交换,计算P(B|A)的方法,在已知P(A|B),P(B),P(A)的情况下可由如上公式得到。 1.3 朴素贝叶斯分类器朴素贝叶斯分类器,其核心方法是通过使用条件概率来实现分类。 应用贝叶斯准则可以得到:
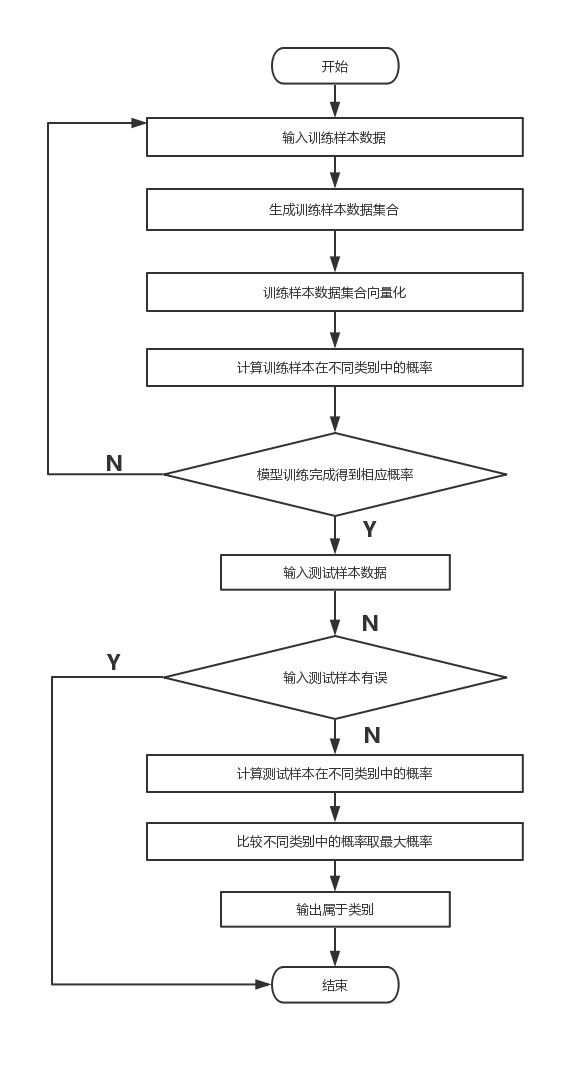
其中P(ci|x,y) 代表中给定某个由x、y表示的数据点,该数据点属于类别ci的概率。而朴素贝叶斯分类器基于一个简单的假定:给定目标值时属性之间相互条件独立。即 P(x,y|ci)(i=1,2,3…..n)相互独立,互不影响。 通过贝叶斯准则,定义贝叶斯分类准则为: 如果P(c1|x,y)> P(c2|x,y),那么属于类别c1; 如果P(c2|x,y)> P(c1|x,y),那么属于类别c2; 1.4 朴素贝叶斯分类器分类过程本节说明朴素贝叶斯分类器分类的总流程:
图1-2朴素贝叶斯分类器分类过程 朴素贝叶斯分类器是基于贝叶斯决策论额分类方法,朴素贝叶斯分类器的主要过程是:首先收集数据,统计数据中特征,计算不同独立特征的条件概率,输入需要完成分类测试样本,根据比较条件概率的大小,取出最大值,完成特征类别的分类。具体步骤如下: (1)输入训练样本,统计特征。 (2)完成训练样本的向量化。 (3)计算各个特征的条件概率。 (4)输入测试样本 (5)根据测试样本中提供的特征,计算不同类别的条件概率。 (6)根据最大条件概率,完成测试样本分类。 第一步,输入实验样本 通过输入的实验样本,切割数据,提取实验样本中特征、类别。 第二步,实验样本的向量化 实验样本为描述特征的文本信息,将其转换成向量,通过向量表示器特征。 第三步,计算各个特征的条件概率。
第四步,输入测试样本,测试样本向量化。 第五步,根据测试样本,计算条件概率。 第六步,比较条件概率大小,输出最大值,完成测试样本分类 。 1.5 朴素贝叶斯分类器在疾病分类中的难点利用朴素贝叶斯分类器对疾病进行分类,由于朴素贝叶斯的特点,所以在疾病分类中有着独特的优势。但是与此同时,朴素贝叶斯在疾病分类中也会面临一些问题与难点。 (1)特征具有关联性 通过选取不同特征,计算条件概率,是建立在特征之间的条件独立性为前提,然而在实际测试中,不同的特征之间存在关联。可以通过增加数据量,来获得不同特征间关联的规律。 (2)测试样本的选取 通过训练样本计算的条件概率模型,使得测试样本的特征必须存在于训练样本中,否则,将无法通过分类器进行测试样本的分类。可以通过测试样本特征检测,判断其是否满足条件,对于不满足条件的测试样本可以采取以下两种方法: 方法一:直接抛出错误,将错误信息返回。 方法二:将测试样本中出现的新的特征,加入到训练样本中,对训练样本计算条件概率模型进行重构,在新的模型下,完成对测试样本特征的分类。 第2章 朴素贝叶斯的疾病预测模型朴素贝叶斯是属于贝叶斯概率理论范畴。贝叶斯概率引入先验知识和逻辑推理来处理不确定的命题。通过实验训练样本数据(即历史数据)中获得各个样本特征的概率,获得概率模型,再输入实验测试样本数据,从概率模型中计算最大概率,最终,疾病最大概率,完成疾病预测。 2.1 预测步骤(1)输入训练样本数据。 (2)根据训练样本中的疾病类别标签,对训练样本中的特征进行分类。 (3)训练样本特征向量化,在对应的疾病类别标签中,完成对样本特征概率的计算。 (4)输入测试样本数据,根据测试样本数据的特征,匹配其对应训练样本的特征,计算对应特征概率,取出最大值,预测疾病类型。 2.2 准备训练样本集 2.2.1 选取输入特征变量以及疾病类型标签我们本次数据,分为疾病类、症状类、职业类。疾病类中有感冒标签、过敏标签、脑震荡标签;症状类中有打喷嚏特征、头痛特征;职业类中有护士特征、农夫特征、建筑工人特征、教师特征。
图 2-1 训练样本 本次数据由于分类较少,且类中特征有限,对于可预测的疾病类型将受到前两者的约束,可通过增加前两者的内容而增加可预测的疾病类型,以及提高疾病预测的准确率。 2.2.2 原始数据的合并将原始数据进行合并,以下分别是症状类数据、职业类数据、疾病类数据。
图2-2 症状类数据
图2-3 职业类数据
图 2-4 疾病类数据 2.2.3 症状类、职业类数据消除特征冗余症状类、职业类数据消除特征冗余在预测系统中计算概率中重要一步。首先,将特征数据逐一与一个初始值为空的集合取并集运算。最后,将得到一个无重复特征的集合,再将新集合列表化。该列表将在计算过程概率中,发挥着模板的作用。 症状类、职业类数据消除特征冗余后的结果如下图:
图 2-5 无特征冗余数据 2.2.4 数据的向量化处理数据的向量化处理,通过数值代表数据中的含义,向量化后的数据才可进行概率计算。通过判断症状类、职业类中的特征在其对应的疾病标签是否出现为标准,出现的特征,前其列表位置的值置1。 数据的向量化处理后的数据如下图:
图 2-6 症状、职业数据的向量化处理后的数据
图 2-7 疾病数据的向量化处理后的数据 2.3 计算各种疾病的概率通过统计疾病类中标签的类别,进行各种疾病概率的计算。计算过程如下图。 公式:P(某种疾病)=不同疾病标签类别 / 标签总数
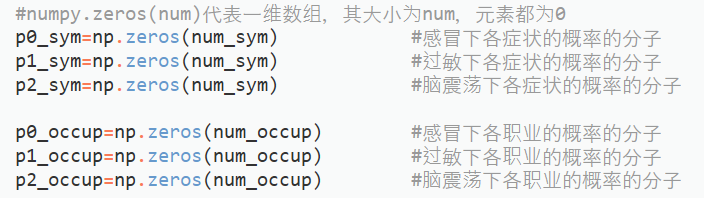
图 2-8疾病概率计算过程 2.4 计算各种疾病下各种症状/职业的概率通过统计疾病类中标签,完成各种症状/职业在疾病中的分类,从而各种疾病下各种症状/职业的概率的计算。 2.4.1 初始化数据定义、初始化数组,用于保存计算概率的分子部分。
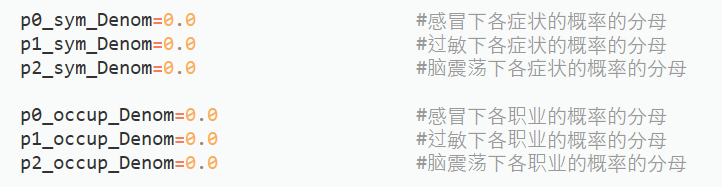
图 2-9计算概率的分子部分 定义变量,用于保存计算概率的分母部分。
图 2-10计算概率的分母部分 2.4.2 症状/职业样本数量的统计在不同疾病标签下,实现症状/职业特征在不同的疾病标签下的分类,并对样本数量进行统计,即为计算概率的分子、分母赋值。
图 2-11分类并完成样本数量统计 2.4.3 收集数据、计算概率不同疾病下症状的概率的计算。
图 2-12不同疾病下症状的概率的计算 不同疾病下职业的概率的计算。
图 2-13不同疾病下职业的概率的计算 2.4.4 获得概率数据以下为各症状/职业的概率。
图 2-14各症状/职业的概率 2.5 准备测试样本集通过终端输入测试样本数据,对测试样本进行向量化,再将测试样本与训练样本进行匹配,匹配对应症状或是职业特征的概率,计算概率,实现根据测试样本,预测疾病概率。 2.5.1 输入测试样本数据通过input函数输入测试样本数据,该数据类型为字符串。
图 2-15输入测试样本数据 2.5.2 测试样本数据向量化通过将测试样本数据传入相关函数,完成其向量化。
图 2-16测试样本数据向量化 下图为数据向量化结果形式,由于每次输入的测试样本数据不同,取其某次结果用于说明。
图 2-17数据向量化结果形式 2.5.3 测试样本对应概率匹配通过测试样本,匹配训练样本中概率列表中的位置
图 2-18匹配概率列表中位置 2.5.4 测试样本获得对应概率根据训练样本中的概率列表第一个位置为“1”的下标,获得该下标所对应的概率
图 2-19获得对应概率 2.5.5 计算概率通过公式:P(疾病|症状*职业) =P(疾病)* P(症状|疾病)* P(职业|疾病)计算概率。
图 2-20计算概率 2.5.6 比较概率,预测疾病类型通过计算概率得到,不同疾病的概率,比较其概率大小,概率最大值即为该模型预测的疾病类型。
图 2-21预测疾病类型 第3章 实验及结果分析本章将根据表中3-1的数据信息,对本系统进行实验及结果分析
表3-1 数据信息 3.1 系统测试系统在服务器(本机作为服务器)上部署后,客户机在本机运行相关的程序,开始对采集到的数据进行训练集的结果获取。 3.2 结果展示测试样本输入合法,实现疾病预测。 3.3 结果展示 3.3.1 测试样本输入合法测试样本输入合法,实现疾病预测。
图 3-1 疾病预测 3.3.2 测试样本输入非法测试样本输入非法,无法实现疾病类型预测,抛出错误信息。
图 3-2 错误信息 3.4 结果分析根据上一小节的预测结果显示,根据相关数据信息建立疾病预测模型,由于相关信息的不全面性,导致疾病预测模型其预测范围有限,在输入测试数据符合该模型的条件下,可以实现疾病类型的预测;对于不合法数据,该模型采取抛出错误信息的方式结束预测。
|

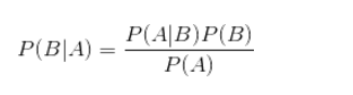
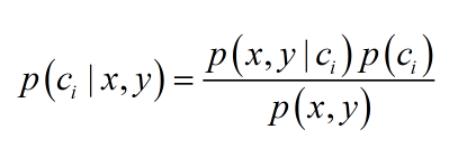
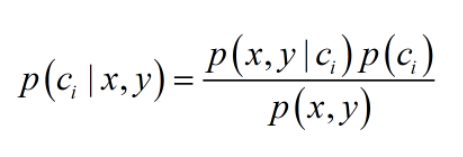























【本文地址】