计算机底层:高速缓冲存储器 |
您所在的位置:网站首页 › 主存和高速缓存 › 计算机底层:高速缓冲存储器 |
计算机底层:高速缓冲存储器
|
计算机底层:高速缓冲存储器
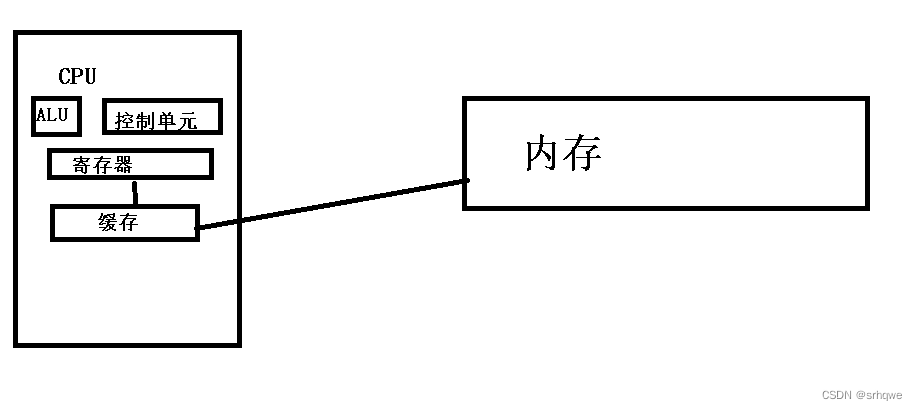
高速缓冲存储器(cache) 简称 缓存 ,位于CPU与内存之间的临时存储器,它的容量比内存小但交换速度快。在缓存中的数据是内存中的一小部分,但这一小部分是短时间内CPU即将访问的,当CPU调用大量数据时,就可避开内存直接从缓存中调用,从而加快读取速度。 那么为什么需要缓存呢? cpu的速度是内存速度的100倍 (100:1) 这里的速度是什么意思呢? 这里指的是,ALU读取寄存器数据和读取内存数据 之间速度的比率。也就是说:ALU访问寄存器的速度比访问内存的速度快100倍。 那么为什么ALU访问寄存器的速度比访问内存的速度快100倍呢? 这里说的是访问速度,不考虑存储器;其实很简单,就是因为:ALU距离内存近. 还有就是寄存器和内存本身寄存器与内存的区别:
1. 寄存器是CPU内部的一种高速存储器,它的容量比内存小,但是速度比内存快得多; 2. 内存是外部存储器,它的容量比寄存器大,但是速度比寄存器慢; 3. 寄存器只能存储少量的数据,而内存可以存储大量的数据; 4. 寄存器的数据只能在CPU内部使用,而内存的数据可以在CPU外部使用; 5. 寄存器的数据只能在一次程序执行中使用,而内存的数据可以在多次程序执行中使用。
这里想必都很好理解. 为什么寄存器处理数据的速度比内存快?这里说到的就是,处理数据的速度: 1.距离不同 2.硬件设计不同 3.工作方式不同 为什么寄存器处理数据的速度比内存快?_Wu Junwu的博客-CSDN博客 这里引出一个问题 :能不能让程序直接在寄存器内部执行,而不用放到内存里?当然是可以的。但是前提就是寄存器存储能力得足够,这显然很难实现,因为需要考虑性价比,寄存器比内存贵很多!8g内存400块,而8g寄存器却要40w。主要还是因为硬件设计不同,因为:内存每个位就是一个电容和一个晶体管,而寄存器的设计则完全不同,多出好几个电子元件。每个位多出好几个电子元件,寄存器有6000多位,可想而知这价格得放大多少?6000多位1024bit=1kb,这才多少?更何况想跑一个程序, 在程序执行时,需要从内存中拿数据,拿到寄存器上,再进入ALU,会发现:从寄存器上拿数据确实很快,但是每次CPU都需要从内存拿数据这却很慢,所以为了提高效率就出现了缓存的概念。 缓存立于CPU和内存之间,包含在CPU内部。
原理: 原理其实很简单,就像你在北京,你需要买个东西,如果你之间从海南买东西是不是要很久,但是从上海买东西是不是就比从海南买来得快。 从内存离得远拿数据慢,但是可以距离缓存进,拿数据就快了一些。 那么缓存应该怎么装数据呢?是从内存中一个一个装到缓存里吗? 显然不是,如果一个一个进入到缓存,那和到内存里一个一个拿,有什么区别?还不如直接从内存拿,还要什么缓存。所以肯定是没区别的。其实拿数据时,是拿一整块数据,比如由一个数组,我不是拿数组里的一个元素,而是把一整个数组拿到缓存里。
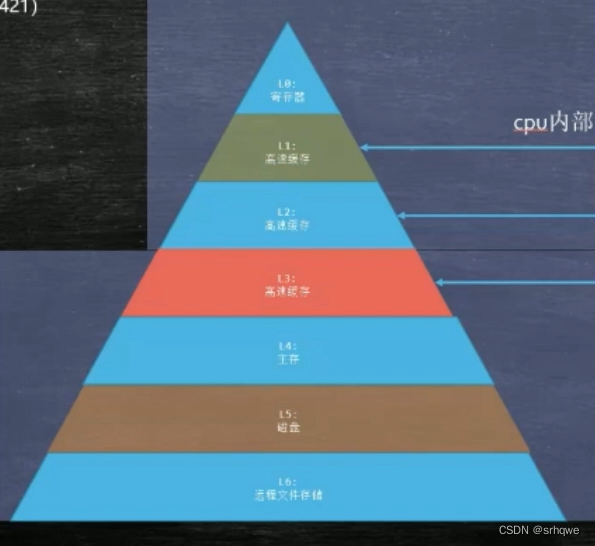
一个缓存实现了让访问速度提高,拿能不能有多个缓存,让速度再提高呢? 就像:从北京—海南的距离变成了从北京—上海的距离,拿还能不能变成从北京—河南?北京—山东,甚至就在北京本地? 答案是可以的。 现在一般CPU都有多层缓存,以达到提升访问速度的作业,那么有几层呢? 现在工业实践中,多采用三层缓存,也就是说寄存器到内存之间有三个缓存
但如果有一天CPU访问内存的速度变快了,也许中间的缓存也会随之减少。
①ALU想拿数据进来,会去寄存器拿。 ②寄存器发现没有ALU想要的数据,找一级缓存。 ③一级缓存发现没有寄存器想要的数据,找二级缓存。 ④二级缓存发现没有一级缓存想要的数据,找三级缓存。 ⑤三级缓存发现没有二级缓存想要的数据,找内存。 ⑥内存发现有三级缓存想要的数据,把数据给三级缓存。 ⑦三级缓存把数据给二级缓存。 ⑧二级缓存把数据给一级缓存。 ⑨一级缓存把数据给寄存器。 ⑩寄存器把数据给ALU。 缓存行: 缓存行就是一次性读取的数据块。什么意思呢? 上面也说了,CPU不会从内存一个数据一个数据地拿。当你要从内存拿一个数据时,为了下次不用再次访问内存,缓存就会从内存拿到这个数据附近所合起来的一块数据,这就叫缓存行。 为什么是拿数据附近所合起来的数据呢? 这是存在一个理论的,即: 程序的局部性原理:①空间局部性、②时间局部性。 这是在工业事件中得到的。 空间局部性:如果一个内存位置(数据/指令)被引用了一次,那么程序很可能在不远的将来引用其附近的一个内存位置(数据/指令)。
时间局部性:被引用过一次的内存位置(数据/指令)很可能在不远的将来再被多次引用。
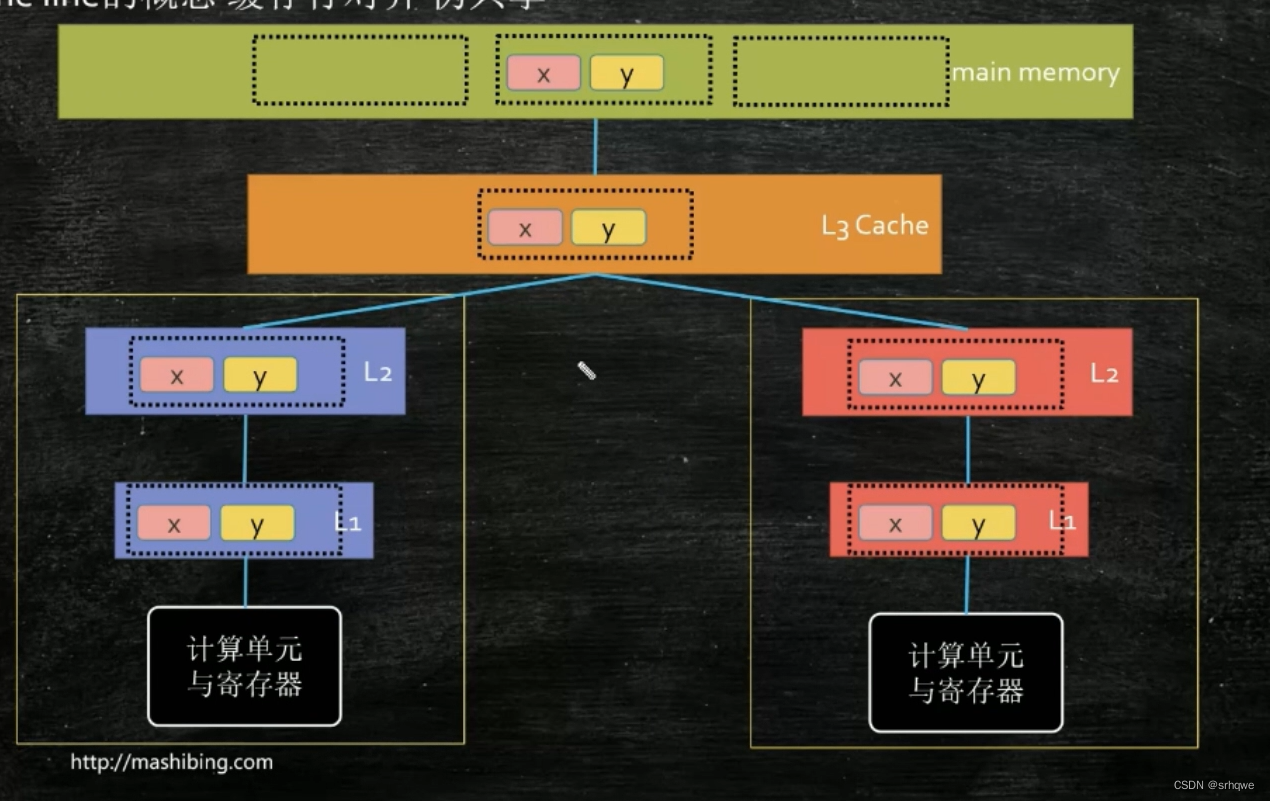
既然一个,数据会被多次引用 并且也会很可能也会马上访问到临边的数据,因此缓存就会从内存拿到这个数据附近所合起来的一块数据。 那么又引出了一个问题:缓存行越大越好,还是越小越好? 其实都不好,一个缓存行太大,cpu拿一次数据就需要很久;一个缓存行太小,cpu就要多次地从内存拿数据。所以应该适中。 其实规定了工业上规定了缓存行的大小,这也是在工业实践中得到的:64字节到256字节不等. 缓存行与缓存一致性协议:【计算机组成】8.如何保持缓存一致性_哔哩哔哩_bilibili 当你用多线程写程序时,比如创建了两个数组,你要用两个线程去分别去修改两个数组的内容。 如果你在两个数组前后加上64-256个字节的变量,你会发现程序的速度跑得更快。 这是因为缓存一致性协议的存在。 原理:首先,就需要知道一点,由于空间局部性,这两个数组很可能创建在同一行(距离很近)
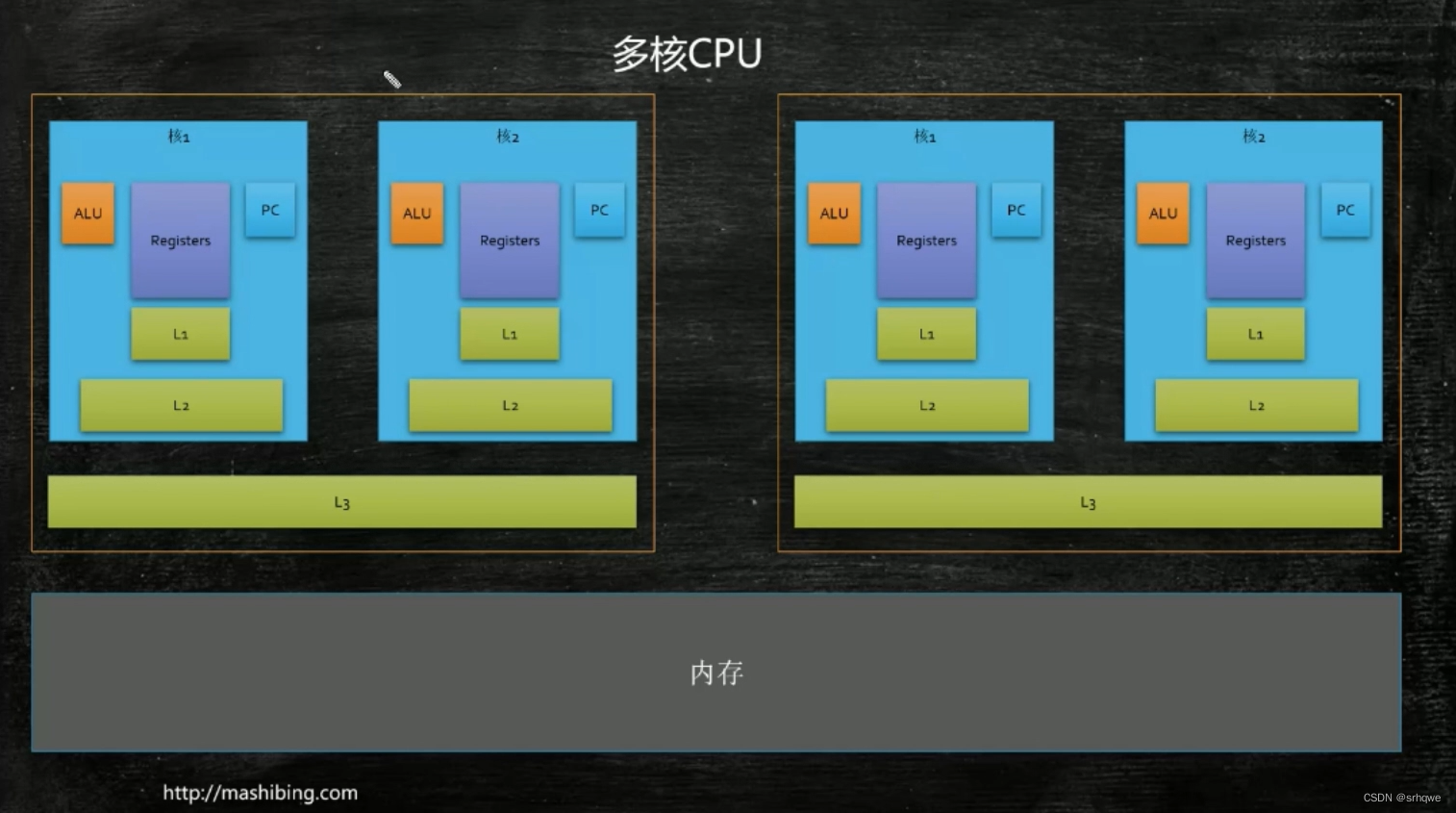
内存到多个CPU(内核)的缓存中会发生拷贝,就是每个CPU内部缓存中,都会有一份其中一个CPU会用到的数据,这是为了提高访问速度,也就是说所有cpu内部缓存都会有同样的一份数据块。 并且,当这个数据块被修改时,其他CPU如果有用到这块数据块,为了数据的一致性,就会同步修改过这块数据的CPU,更新上传到内存,要用这块的CPU再从CPU拿下来. 当多个处理器的运算任务都涉及同一 块主内存区域时,将可能导致各自的缓存数据不一致的情况,如果真的发生这种情况,那同步回到主内存时以谁的缓存数据为准呢?为了解决一致性的问题,需要各个处理器访问缓存时都遵循一些协议,在读写时要根据协议来进行操作,这类协议有MSI、MESI(IllinoisProtocol)、MOSI、Synapse、Firefly及DragonProtocol,等等。不同厂家都有不同的协议MESI就是因特尔的,这些就叫做 缓存一致性协议 缓存一致性原则的概念以及流程:缓存一致性协议:MESI_bingaPang的博客-CSDN博客
因此,当两个数组距离很近时,左边的cpu需要和右边的cpu同步(使用缓存一致性协议),同步的前提是两边会用到同一份(不需要是一块)数据。所以,如果再两个数组前后都加上64-256个字节的数据,那么两个数组还会在同一行吗?显然不会,它们完全被隔开了,不会因为空间局部性而在同一行,那么如果不在同一行,那么缓存拿一块数据时,最多拿64-256个字节,缓存行怎么也不可能拿到两个数组的数据,因此只能分成两块缓存行拿,那么两块缓存行就互不影响,从而不需要同步。
总结:由于缓存行和程序的局部性原理的存在,我们需要一种机制,来保证数据的一致性, 这种机制叫做:缓存一致性协议。
|

【本文地址】
今日新闻 |
推荐新闻 |