python爬取“微博”移动端评论数据 |
您所在的位置:网站首页 › 为什么微博看不到最新动态内容 › python爬取“微博”移动端评论数据 |
python爬取“微博”移动端评论数据
|
目的
爬取微博移动端的评论数据(如下图),然后将数据保存到.txt文件和.xlsl文件中。 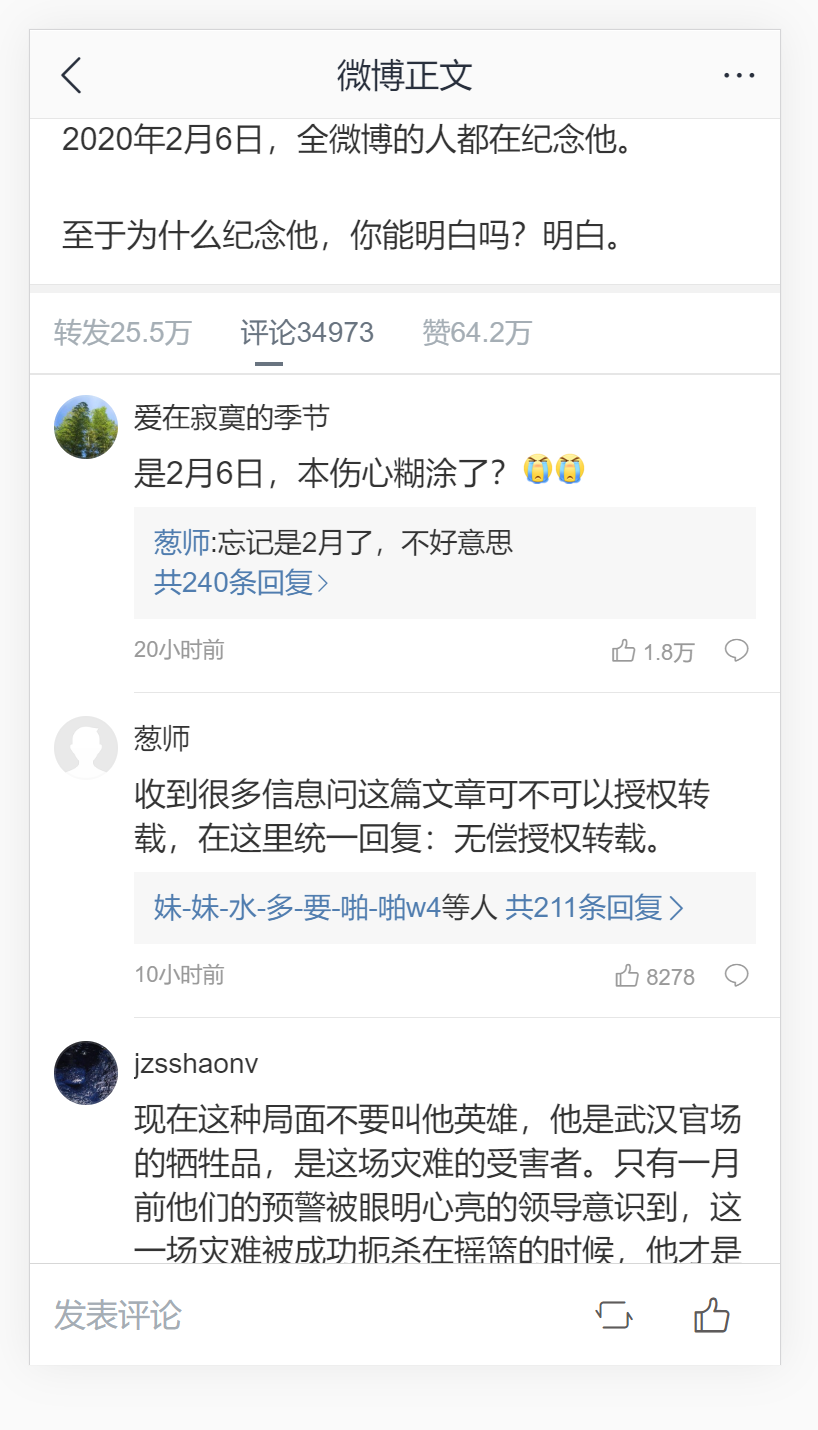 实现过程
实现过程
实现的方法很简单,就是模拟浏览器发送ajax请求,然后获取后端传过来的json数据。 一、找到获取评论数据的ajax请求按下F12,打开控制台,找到以下请求 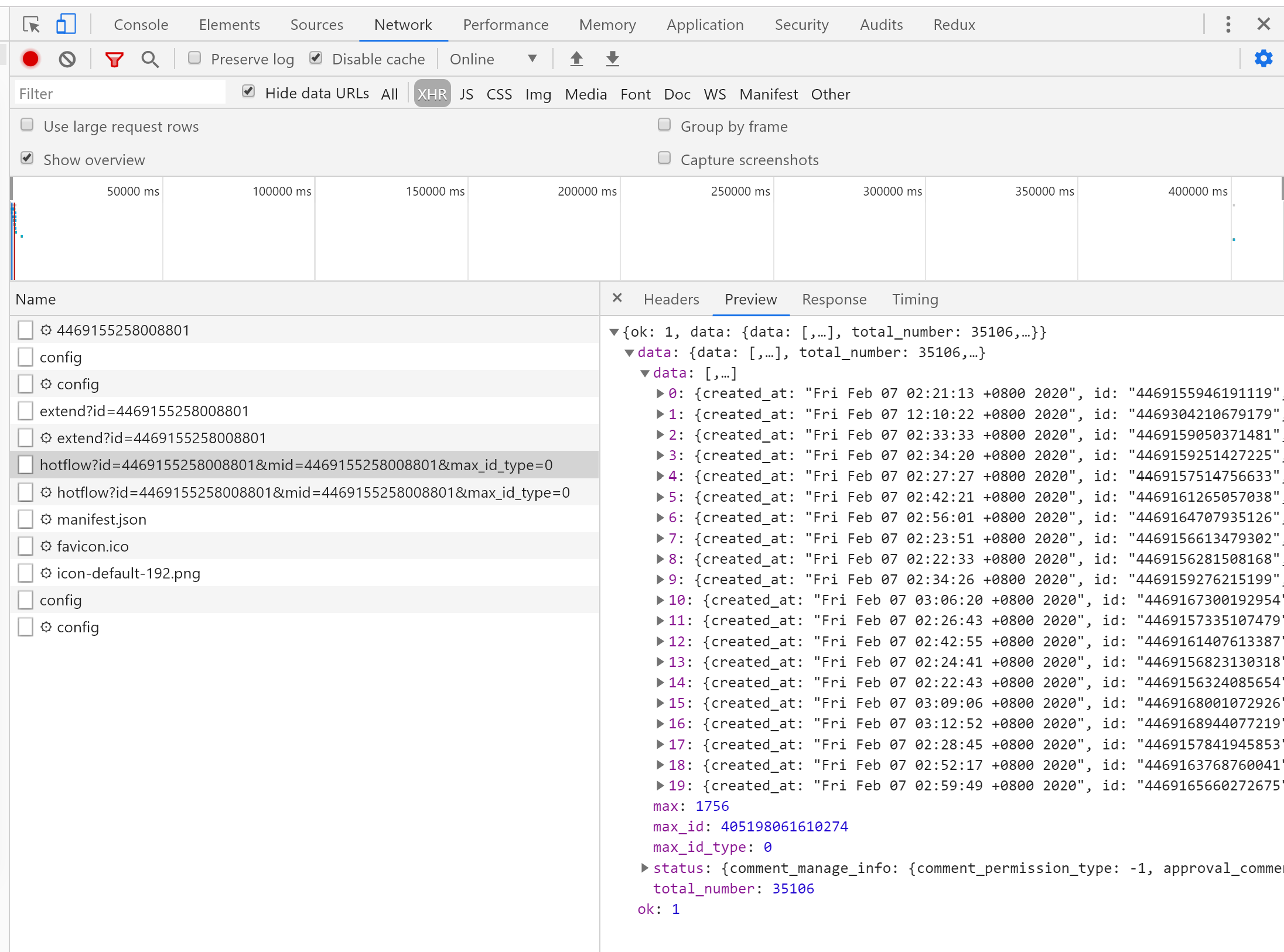
以 https://m.weibo.cn/detail/4467454577673256 为例,得到的ajax请求是这样的: https://m.weibo.cn/comments/hotflow?id=4467454577673256&mid=4467454577673256&max_id_type=0 然后,我们往下滚动屏幕,再观察几个获取评论数据的ajax请求(篇幅有限,只看两个),看有什么规律。 https://m.weibo.cn/comments/hotflow?id=4467454577673256&mid=4467454577673256&max_id=142552137895298&max_id_type=0 https://m.weibo.cn/comments/hotflow?id=4467454577673256&mid=4467454577673256&max_id=139116183376416&max_id_type=0 可以看到这几个ajax都有几个共同的部分: https://m.weibo.cn/comments/hotflow?id=4467454577673256mid=4467454577673256max_id_type=0其中,id和mid的数值为微博链接的最后一串数字,max_id_type都为0(但事实上,不总为0,后面会讲)。到这一步,我们可以模拟获取评论数据的第一个ajax请求了,因为它就是由上面这些组成的。而后面的那些ajax请求,则是多了一个max_id参数。经过观察,该参数是从前一个ajax请求返回的数据中得到的。以前面第二个ajax请求为例: 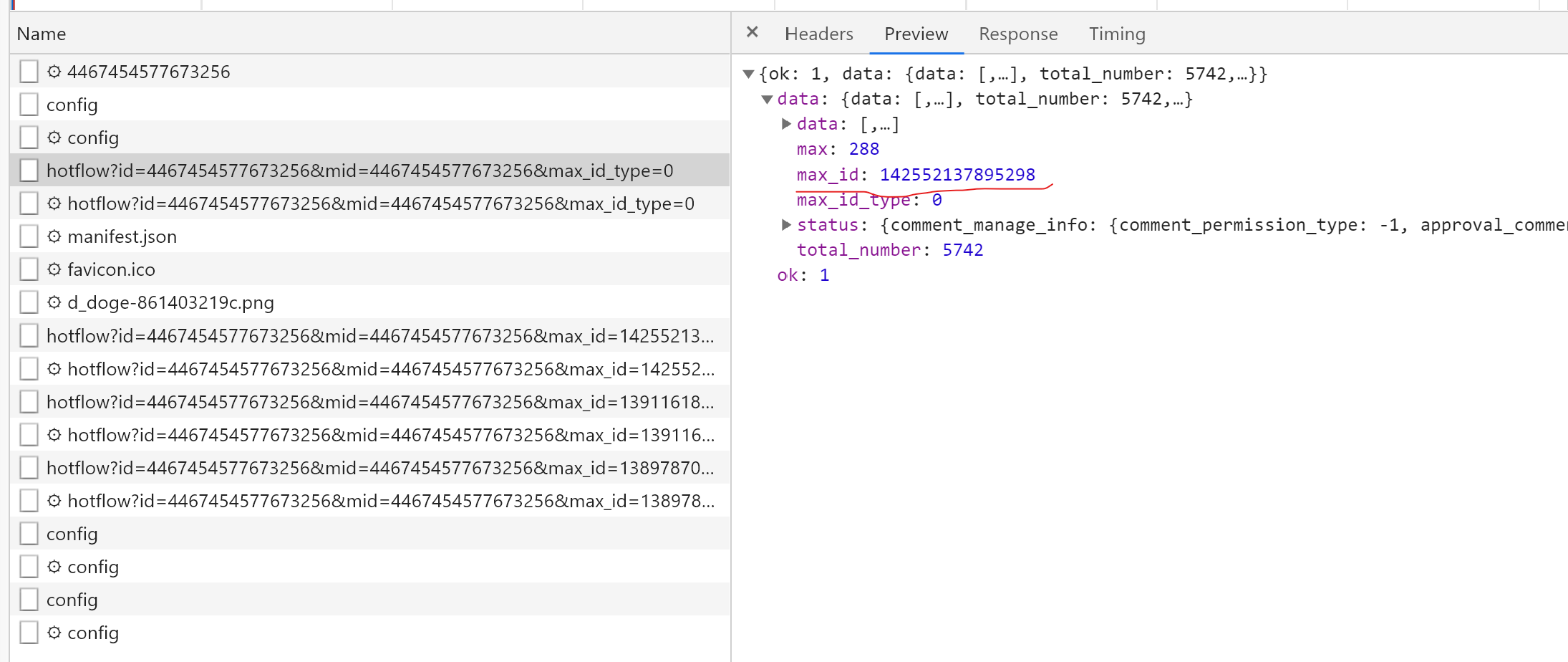
该请求中的max_id参数就是由从第一个ajax请求的max_id字段中得到。所以,后续的操作就是: 根据baseurl,id,mid,获取第一个ajax请求中的数据,然后将有用的评论信息数据保存到数组中,并返回一个max_id字段。模拟浏览器,根据前面获得的max_id字段,以及baseurl,id,mid发送下一个ajax请求,将评论数据结果append到前一次的结果中。循环第2步max次,其中max为发送ajax的次数(好像是错的,循环次数应该是≤max,自行打印试试),该字段由上面截图的max字段可得,初始值为1。最终,将评论数据结果保存到.txt和.xlsx文件中。 二、获取ajax请求的数据获取数据的方式有很多,我选择了request.get()来获取。 web_data = requests.get(url, headers=headers,timeout=5) js_con = web_data.json()使用以上代码,我们可以很轻松的获取第一个请求的数据。但是到获取第二第三个请求的数据时,就会报错。原因是没有加入Cookies。于是乎,我就在Request Headers中找含有Coookies的数据信息,结果全部文件找了一遍都没有。因此,我决定把微博站点的所有Cookies字段值都敲进去。如下。 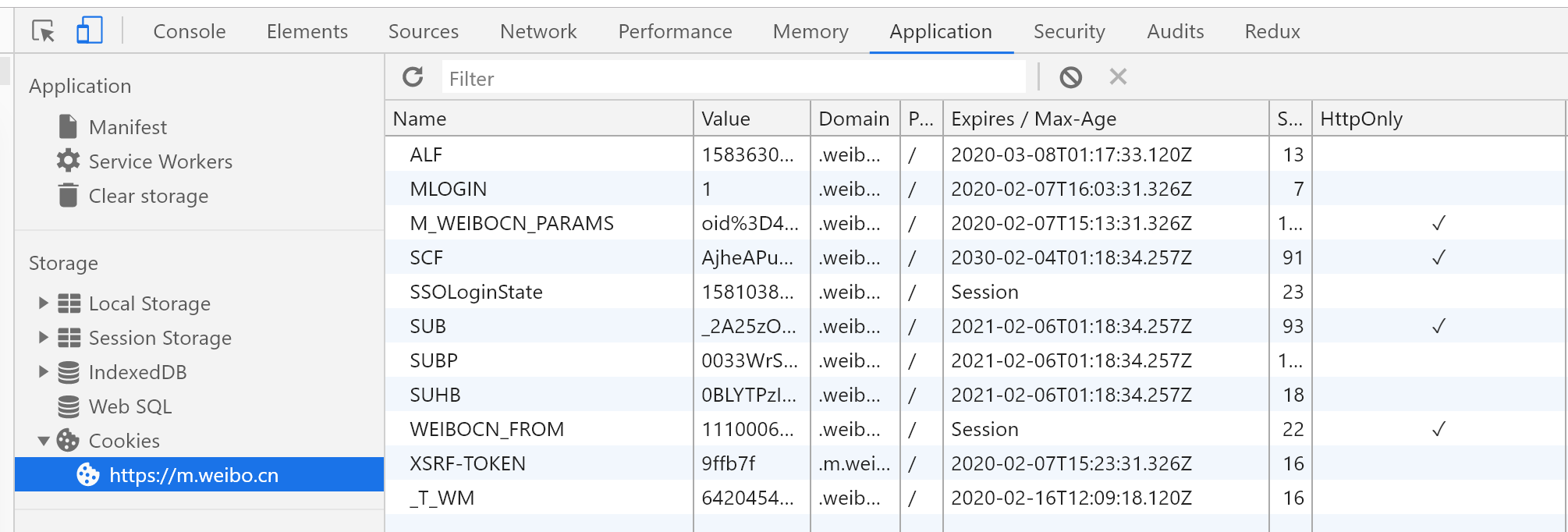
因此,解决了cookie问题之后,我们测试一下看是否能获取后面所有ajax请求的数据。答案是:no. 经无数次测试,在爬取第17次请求的数据时,总是抛出异常。而原因则是我们前面所提及的,max_id_type不总是等于0,当发送第17次请求时max_id_type等于1。 
于是到这一步,我们基本就可以爬取所有的数据了。但还是有一个小问题。就是有些微博的评论开启了精选模式,只显示回复数最多的几个评论。比如这个示例: 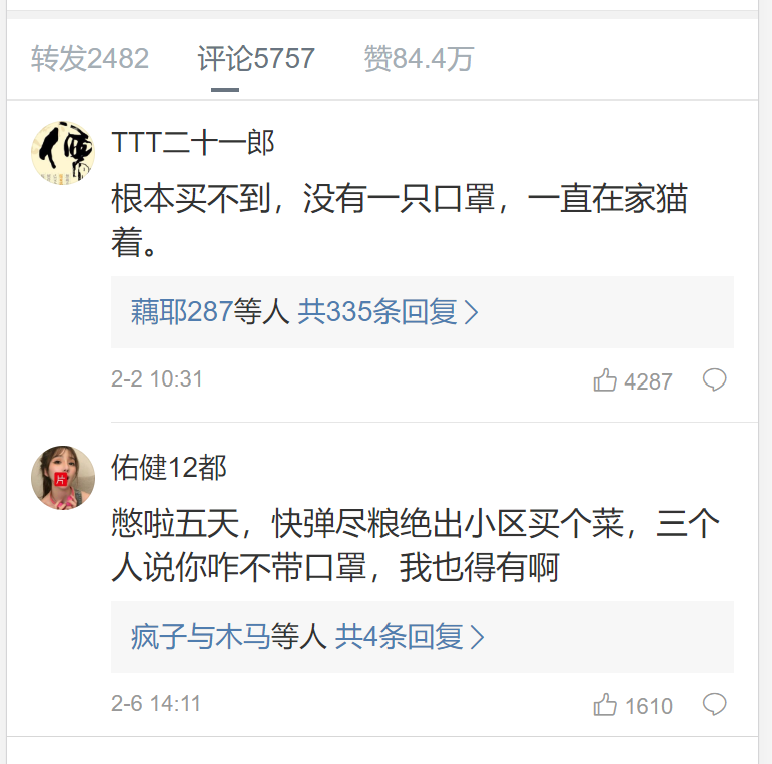
虽然上面写着有5757条评论,但是后端只返回17条数据到前端。因此,如果按照前面的思维,循环max次发送ajax请求的话是会报错的,因此解决该问题的方法就是判断该ajax请求返回的数据中是否包含{ok: 0}(其他有效的返回结果都为ok:1)。如果有,则说明这个请求及之后的请求是无效的,不用一直循环下去,直接将结果保存到.txt和.xlsx文件即可。 三、将数据保存到txt和excel中将数据导出到这两种文件的代码,网上应有尽有,这里不加赘述。但是,这里要说明的是:因为要存储多个微博的评论数据,所以excel中要分不同sheet来存储;而txt中的数据仅仅是为了随便看看,所以微博的评论数据都追加到这里面。 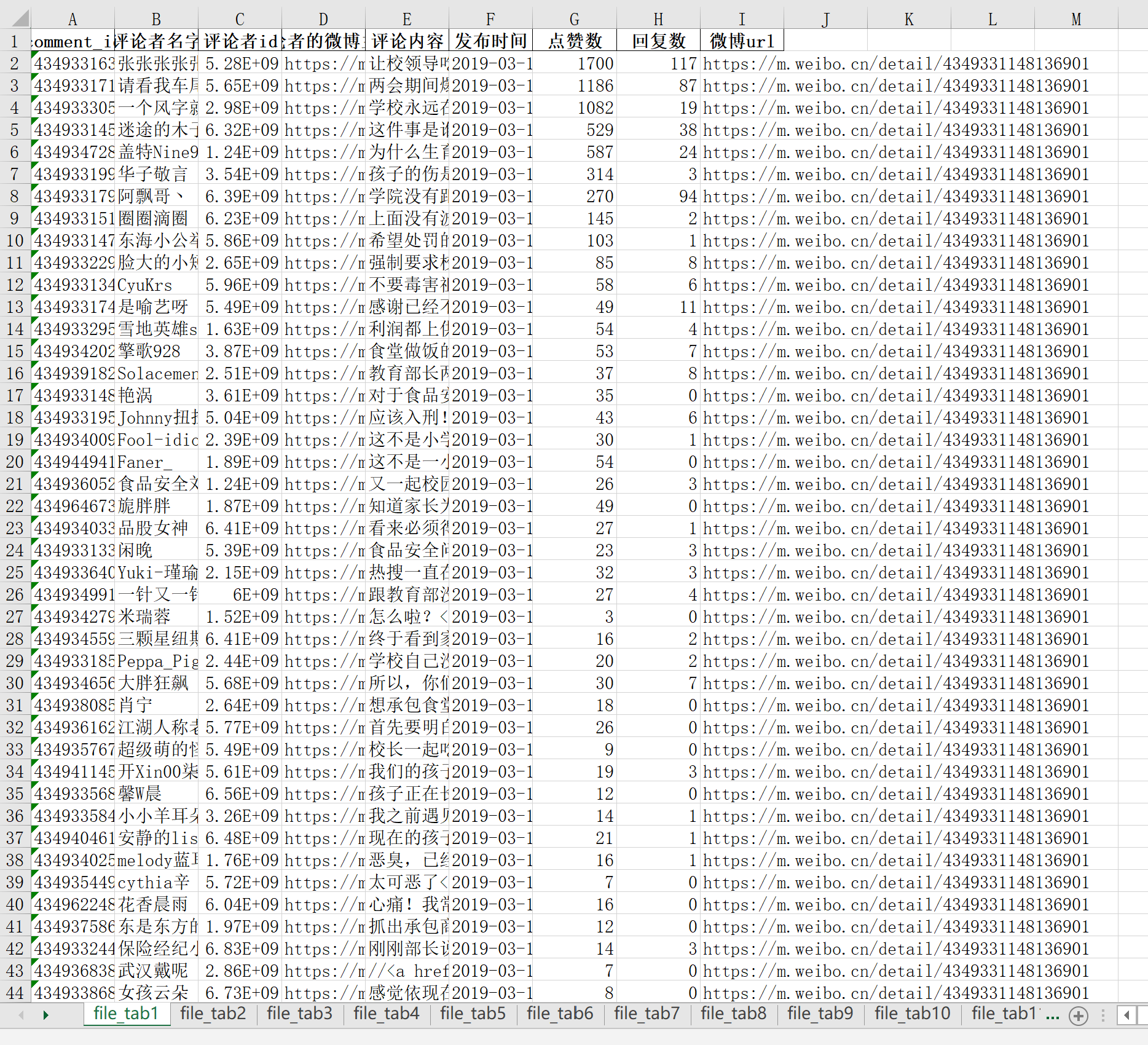
 四、源代码
四、源代码
comment.py(主文件) import requests import pandas as pd import time import openpyxl #导出excel需要用到 from config import headers,url,Cookie,base_url,weiboComment,excel_name,txt_name #将中国标准时间(Sat Mar 16 12:12:03 +0800 2019)转换成年月日 def formatTime(time_string, from_format, to_format='%Y.%m.%d %H:%M:%S'): time_struct = time.strptime(time_string,from_format) times = time.strftime(to_format, time_struct) return times # 爬取第一页的微博评论 def first_page_comment(weibo_id, url, headers): try: url = url + str(weibo_id) + '&mid=' + str(weibo_id) + '&max_id_type=0' web_data = requests.get(url, headers=headers,cookies = Cookie,timeout=20) js_con = web_data.json() # 获取连接下一页评论的max_id max_id = js_con['data']['max_id'] max = js_con['data']['max'] comments_list = js_con['data']['data'] for commment_item in comments_list: Obj = { 'commentor_id':commment_item['user']['id'], 'commentor_name':commment_item['user']['screen_name'], 'commentor_blog_url':commment_item['user']['profile_url'], 'comment_id':commment_item['id'], 'comment_text':commment_item['text'], 'create_time':formatTime(commment_item['created_at'],'%a %b %d %H:%M:%S +0800 %Y','%Y-%m-%d %H:%M:%S'), 'like_count':commment_item['like_count'], 'reply_number':commment_item['total_number'], 'full_path':base_url+str(weibo_id), 'max_id': max_id, 'max':max } commentLists.append(Obj) print("已获取第1页的评论") return commentLists except Exception as e: print("遇到异常") return [] #运用递归思想,爬取剩余页面的评论。因为后面每一页的url都有一个max_id,这只有从前一个页面返回的数据中获取。 def orther_page_comments(count,weibo_id, url, headers,max,max_id): if count |
【本文地址】
今日新闻 |
推荐新闻 |