压缩 |
您所在的位置:网站首页 › 为什么压缩文件后还是很大内存 › 压缩 |
压缩
|
本文为压缩相关内容部分内容:https://alvincr.com/2021/01/compress-entropy/
(数据压缩测试、字典、固实压缩、熵及其作用) 一:压缩原理 1 压缩前提首先需要明白压缩这个技术为什么能存在,首先先联想一下我们生活中的压缩,能够压缩的东西必须要有空隙,例如海绵中有大量的空气,因此才能把它压扁,而铁锭中就没有空气,很难再进行压缩。 计算机中的压缩亦是如此,但在压缩文件中,需要的不是空气,而是重复的内容。2^16=65536,理论上一个字就有这么多种表示方法,但是并不是每个字出现的概率都相同,有些字出现的概率就会高很多,同样使用这个字组成的词的概率 并不相同,而是某个特定的词使用次数更多,这就是文件中的“空气”。 一篇小说中会多次出现主角的名字,如果这个主角叫alvincr,那么我就可以用x来表示alvincr,在压缩的过程中遇到alvincr就替换成x,这样就能节省很多字母,解压的时候遇到x就变成alvincr,那么文件就又回来了。 假如有一个文件是写了一千遍的alvincr,
那么压缩的时候既可以直接用x替换alvincr,然后再统计x的数量为1000,最终输出的结果很可能就是这样的:x-?1000(假设这里-表示转义符,-?用于表示重复的次数) 如果我将alvincr重复无穷次,那么最后压缩的效率甚至能达到:1000000:1(个人随意写的数字,并没有做具体实验)
使用记事本打开效果:
压缩后的文件会变成:规则表+内容+附录 的形式,当我们进行解压的时候需要去查找解压的规则,即查找究竟X代表的是什么,是alvincr.com?还是alvincr? 压缩分为无损压缩和有损压缩,对于准确性要求不高的文件可采用有损压缩的形式,例如打电话时及时损失了一些原有的细节,也不会影响通话的质量;但是对于我写的文章,如果压缩软件进行有损压缩,你可能就完全看不出来我原来写的什么了。 3 字典通过将文本中比较长且出现次数较多的文字,替换成特定的ASCII码,例如将alvincr.com替换成01,01就是alvincr.com的字典,因此如果文本是:本文来自alvincr.com,那么压缩后就会变成:本文来自01,这样就能大幅度减少文字的长度。
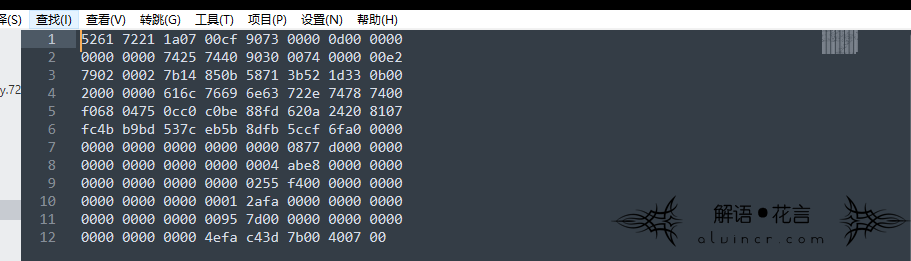
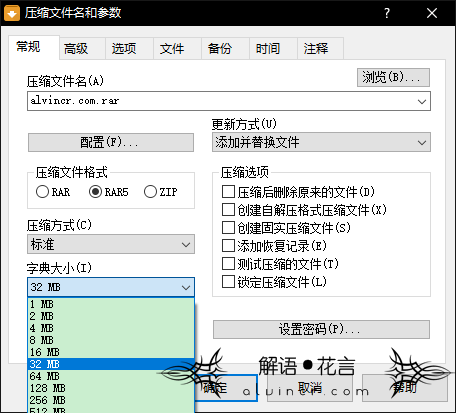
虽然字典设置的越大,压缩后的文件越小,但是压缩速度会变慢,资源消耗变大。从上图可以看出rar默认使用4MB的字典,rar5使用32MB字典。 字典设置的越大,那么能够处理的内容就越多,当字典空间耗尽后将会重新启动一个新字典,在运行字典的时候,整个字典全都保存在内存中,因此如果内存容量较小的用户,还是不要将字典设置那么大,经过下文测试(压缩选项-部分)发现rar的32MB字典完全能够实现压缩的效果。 |


【本文地址】
今日新闻 |
推荐新闻 |