国科大2017 |
您所在的位置:网站首页 › 中科院考试题目及答案 › 国科大2017 |
国科大2017
|
公众号每周推送区块链技术文章 个人踩坑日记
本文PDF文件下载地址
答案 选择题答案和卷子上有所区别
选择题涉及到的部分知识点总结
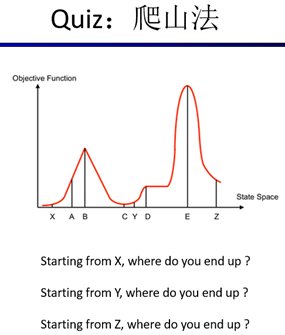
爬山法搜索 可在任意位置起始重复: 移动到最好的相邻状态,不允许向山下移动如果没有比当前更好的相邻状态,结束遗传算法 基于适应度函数,在每步中保留 N 个最好状态配对杂交操作产生可选的变异问题的目标函数天然的可作为遗传算法的适应度函数
图搜索主要是通过集合来维护,不会破坏完备性和最优性(通过启发式一致性来保证,估计耗散小于实际耗散)
简答题涉及到的知识点以及对应答案供参考 本文答案来自网络各种渠道进行整理总结,版权归原作者所有 不能保证答案的完全正确性 蚁群优化算法 https://blog.csdn.net/qq_27500493/article/details/83592938
搜索问题的形式化描述:状态空间+后继函数+初始状态和目标测试
BP算法 算法流程: 选取训练数据输入网络根据权重与激活函数计算输出算出实际输出与目标输出之间的误差反向传播误差使全局误差最小 输出层: 隐藏层: J在i之前,η是学习率,yj‘是j层的输出,yi是i层的输出,di是i层的目标输出 Goto1,直到算法收敛。
1-yi由于yi是sigmoid函数的输出位于0-1区间,因此1-yi必定位于0-1区间,所以传递的层数越多误差越小,最后导致梯度消失。 梯度消失
Sigmoid函数反向传播误差的时候是一个链式偏导,本来神经元经过前向传播sigmoid函数激活后就是一个0到1之间的书,现在还成1-x,两个小于1的数相乘,乘的多了(层数多了)就趋近于0了 Hopfield网络
Hopfield网络是经典的反馈网络模型,动态系统 稳定性问题通过能量函数解决。解决问题:从输入状态到达稳定状态 将要求解的问题转化为优化问题的能量函数,网络的稳定状态是优化问题的解 Lyapunov (Energy) Function 玻尔兹曼机
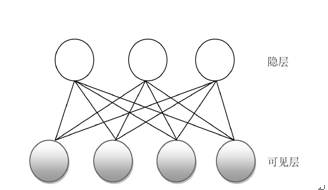
玻尔兹曼机结构类似于Hopfield 网络,但它是具有隐单元的反馈互联网络。 BM基本原理: Hopfield网络的神经元的结构功能及其在网络中的地位是一样的,但BM中一部分神经元与外部相连,可以起到网络的输入、输出功能,或者严格地说可以受到外部条件的约束。另一部分神经元则不与外部相连,因而属于隐单元(外部看不见)每个神经元只取1或0这两种状态:状态1代表该神经元处于接通状态,状态0代表该神经元处于断开状态 受限玻尔兹曼机
受限玻尔兹曼机RBM是一种玻尔兹曼机的变体,限定模型必须为二分图。学习的目标是极大似然。 DBN
非监督的预学习+监督微调(fine-tuning
训练的时候采用逐层贪婪训练使得网络层数堆积
Deep Belief Network DBN是由Hinton在2006年提出的一种概率生成模型, 由多个限制玻尔兹曼机(RBM)[3]堆栈而成: CNN 局部连接、参数共享、子采样、非逐层贪婪训练 卷积神经网络 http://blog.csdn.net/yunpiao123456/article/details/52437794
卷积层+pooling层+输出层 它的神经元间的连接是非全连接的,同一层中某些神经元之间的连接的权重是共享的(即相同的)——减少了权值的数量,降低了网络模型的复杂度。 在CNN的一个卷积层中,通常包含若干个特征平面(featureMap),每个特征平面由一些矩形排列的的神经元组成,同一特征平面的神经元共享权值,这里共享的权值就是卷积核。(每个卷积核都会将图像生成为另一幅图像,一个卷积的特征提取是不充分的) 在每个卷积层之后,通常会立即应用一个非线性层(或激活层),其目的是给一个在卷积层中刚经过线性计算操作(只是数组元素依次(element wise)相乘与求和)的系统引入非线性特征。 GAN GAN 综述http://www.sohu.com/a/121189842_465975 GAN实现https://www.leiphone.com/news/201704/b8w2VNuvTV2CERMP.html
GAN 的核心思想来源于博弈论的纳什均衡:生成器(生成一个数据,会被判别结果优化)+ 判别器(判断是否是生成器生成的):生成器的目的是尽量去学习真实的数据分布。把噪声数据 z(也就是我们说的假数据)通过生成模型 G,伪装成了真实数据 x。判别器的目的是尽量正确判别输入数据是来自真实数据还是来自生成器。各自提高自己的生成能力和判别能力, 这个学习优化过程就是寻找二者之间的一个纳什均衡
判别函数的三种形式: 最大最小博弈
J(D) 代表判别网络(也就是警察 B)的目标函数——一个交叉熵(cross entropy)函数。 J(G) 就是代表生成网络的目标函数,它的目的是跟 D 反着干,所以前面加了个负号(类似于一个 Jensen-Shannon(JS)距离的表达式)。 最小最大博弈(minimax game):两个人的零和博弈,一个想最大,另一个想最小。那么,我们要找的均衡点(也就是纳什均衡)就是 J(D) 的鞍点(saddle point)。 非饱和博弈
但是,这也是有问题的:我们的生成模型跟源数据拟合之后就没法再继续学习了(因为常数线 y = 1/2 求导永远为 0) 用 G 自己的伪装成功率来表示自己的目标函数(不再是直接拿 J(D) 的负数)。这样的话,我们的均衡就不再是由损失(loss)决定的了。J(D) 跟 J(G) 没有简单粗暴的相互绑定,就算在 D 完美了以后,G 还可以继续被优化。 最大似然
形式1的JS距离可以变化为最大似然形式。
GAN的训练算法
这里红框圈出的部分是我们要额外注意的。第一步我们训练D,D是希望V(G, D)越大越好,所以是加上梯度(ascending)。第二步训练G时,V(G, D)越小越好,所以是减去梯度(descending)。整个训练过程交替进行。 从数学推导上严格证明了:在假设G和D都有足够的capacity的条件下,如果在迭代过程中的每一步,D都可以达到当下在给定G时的最优值,并在这之后再更新G,那么最终Pg就一定会收敛于Pdata。也正是基于上述的理论,原始文章中是每次迭代中优先保证D在给定当前G下达到最优,然后再去更新G到最优,如此循环迭代完成训练。
DCGAN其实就是一个反向的CNN——创造图片而非过滤
G/D就是两个深度神经模型,在训练的过程中可以用到BP算法。 先把真实数据标识为‘1’(真实分布),由生成器生成的数据标识为’0‘(生成分布),反复迭代训练 D先将 G 拼接在 D 的上方,即 G 的输出作为 D 的输入,而同时固定 D 的参数,并将进入 G 的噪音样本标签全部改成'1',为了最小化损失函数,此时就只能改变 G 的每一层权重,反复迭代后 G 的生成能力因此得以改进。反复迭代(1)(2),最终 G 就会得到较好的生成能力。
传教士野人问题求解 https://www.cnblogs.com/6DAN_HUST/archive/2010/08/23/1806560.html https://wenku.baidu.com/view/4c5ddb4c2b160b4e767fcf01
格子问题
|







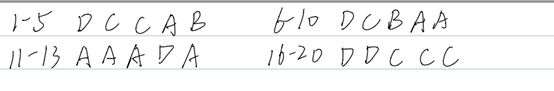




























【本文地址】