NLP(四十一)使用HuggingFace翻译模型的一次尝试 |
您所在的位置:网站首页 › 中日互译翻译器下载安装 › NLP(四十一)使用HuggingFace翻译模型的一次尝试 |
NLP(四十一)使用HuggingFace翻译模型的一次尝试
|
本文将如何如何使用HuggingFace中的翻译模型。 HuggingFace是NLP领域中响当当的团体,它在预训练模型方面作出了很多接触的工作,并开源了许多预训练模型和已经针对具体某个NLP人物训练好的直接可以使用的模型。本文将使用HuggingFace提供的可直接使用的翻译模型。 HuggingFace的翻译模型可参考网址:https://huggingface.co/models?pipeline_tag=translation ,该部分模型中的绝大部分是由Helsinki-NLP(Language Technology Research Group at the University of Helsinki)机构开源,模型数量为1333个。 模型使用笔者将在PyTorch框架下使用HuggingFace的中译英模型和英译中模型。其中中译英模型的模型名称为:opus-mt-zh-en,下载网址为:https://huggingface.co/Helsinki-NLP/opus-mt-zh-en/tree/main;英译中模型的模型名称为opus-mt-en-zh,下载网址为:https://huggingface.co/Helsinki-NLP/opus-mt-en-zh/tree/main 。 首先我们先尝试中译英模型,即把中文翻译成英语,代码如下: # -*- coding: utf-8 -*- from transformers import AutoTokenizer, AutoModelForSeq2SeqLM tokenizer = AutoTokenizer.from_pretrained("./opus-mt-zh-en") model = AutoModelForSeq2SeqLM.from_pretrained("./opus-mt-zh-en") text = "从时间上看,中国空间站的建造比国际空间站晚20多年。" # Tokenize the text batch = tokenizer.prepare_seq2seq_batch(src_texts=[text]) # Make sure that the tokenized text does not exceed the maximum # allowed size of 512 batch["input_ids"] = batch["input_ids"][:, :512] batch["attention_mask"] = batch["attention_mask"][:, :512] # Perform the translation and decode the output translation = model.generate(**batch) result = tokenizer.batch_decode(translation, skip_special_tokens=True) print(result)翻译结果如下: ["In terms of time, the Chinese space station was built more than 20 years later than the International Space Station."]接着我们先尝试英译中模型,即把英文翻译成汉语,代码如下: # -*- coding: utf-8 -*- from transformers import AutoTokenizer, AutoModelForSeq2SeqLM tokenizer = AutoTokenizer.from_pretrained("./opus-mt-en-zh") model = AutoModelForSeq2SeqLM.from_pretrained("./opus-mt-en-zh") text = "In terms of time, the Chinese space station was built more than 20 years later than the International Space Station." # Tokenize the text batch = tokenizer.prepare_seq2seq_batch(src_texts=[text]) # Make sure that the tokenized text does not exceed the maximum # allowed size of 512 batch["input_ids"] = batch["input_ids"][:, :512] batch["attention_mask"] = batch["attention_mask"][:, :512] # Perform the translation and decode the output translation = model.generate(**batch) result = tokenizer.batch_decode(translation, skip_special_tokens=True) print(result)翻译结果如下: ['就时间而言,中国空间站的建造比国际空间站晚了20多年。']有了HuggingFace的transformers模块,我们使用起这些模型相当方便,同时也有很不错的翻译效果。 模型解释 接着我们再接触一款工具,名称为shap。shap是Python开发的一个模型解释包,可以任何机器学习模型的输出。其名称来源于SHapley Additive exPlanation,在合作博弈论的启发下SHAP构建一个加性的解释模型,所有的特征都视为“贡献者”。对于每个预测样本,模型都产生一个预测值,SHAP value就是该样本中每个特征所分配到的数值。 我们尝试着使用shap模块来对翻译模型进行解释,可以看到shap可视化效果非常棒的解释界面,如下:
模型解释的热力图效果如下:
|
 默认输出结果为翻译结果,如下:
默认输出结果为翻译结果,如下:
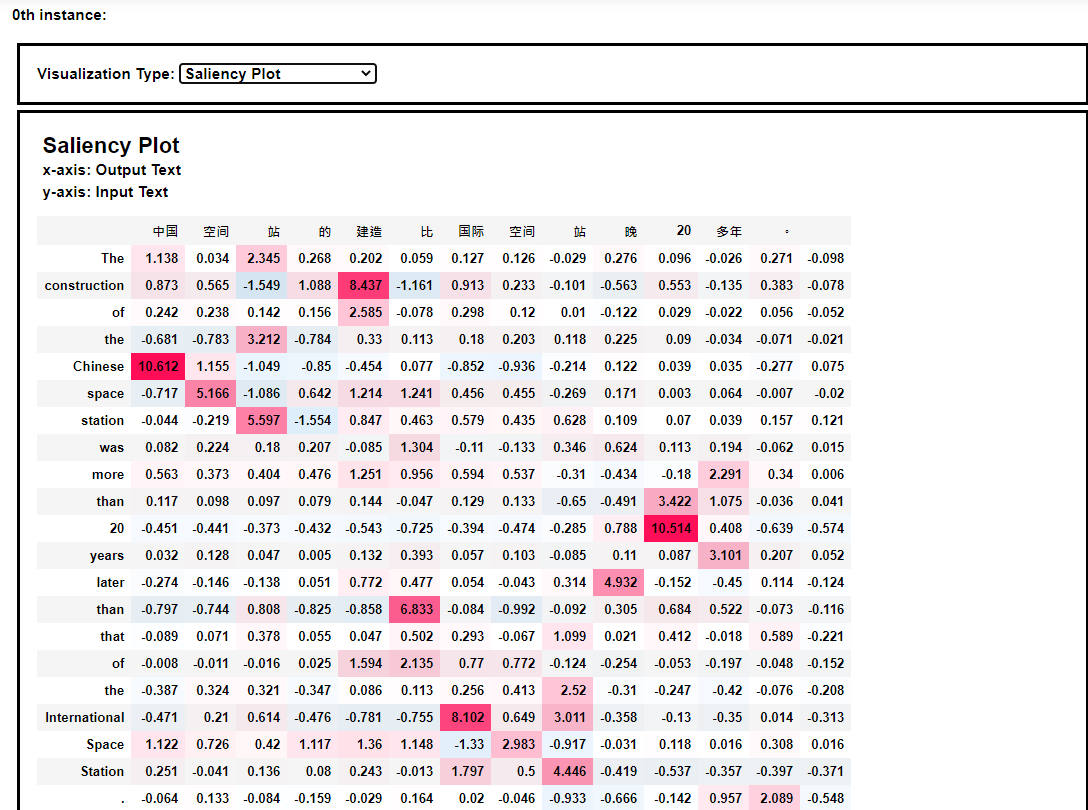 从热力图中我们可以发现,空间站这个词语被翻译成space station。 同样,我们可以看到英译中模型的热力图解释效果,如下:
从热力图中我们可以发现,空间站这个词语被翻译成space station。 同样,我们可以看到英译中模型的热力图解释效果,如下: 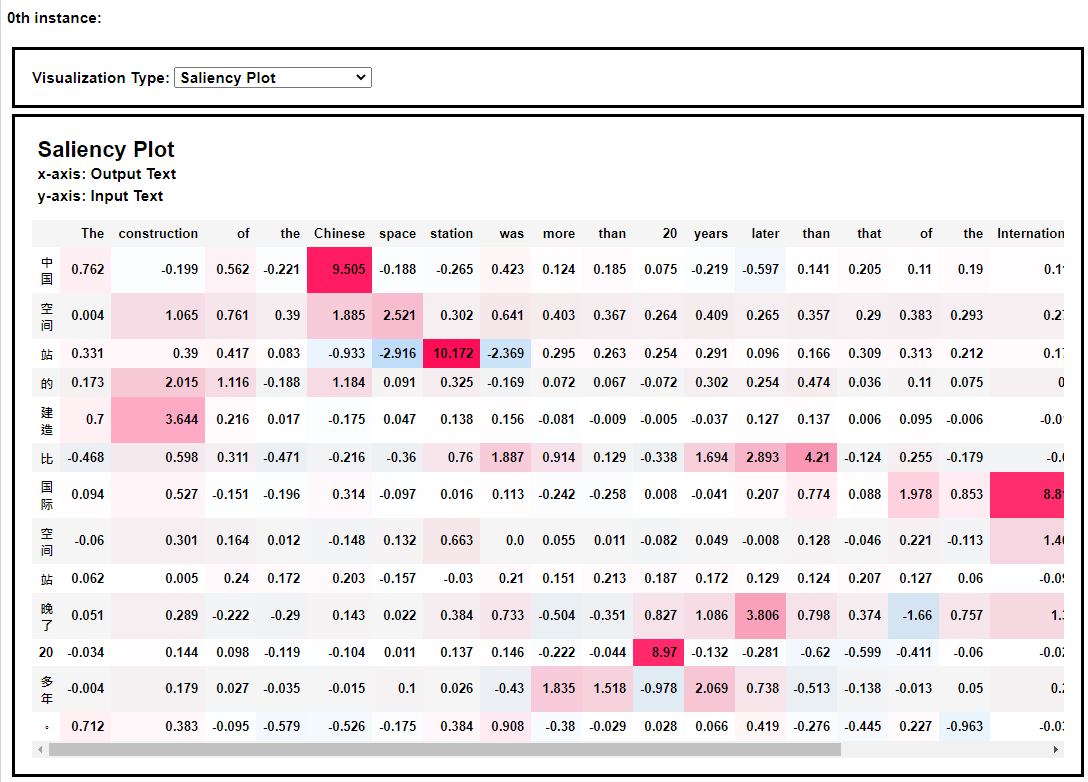 本次分享到此结束,感谢大家阅读~ 2021年3月10日于上海浦东~
本次分享到此结束,感谢大家阅读~ 2021年3月10日于上海浦东~【本文地址】
今日新闻 |
推荐新闻 |