李宏毅自然语言处理 |
您所在的位置:网站首页 › 中文是语种吗 › 李宏毅自然语言处理 |
李宏毅自然语言处理
|
引用
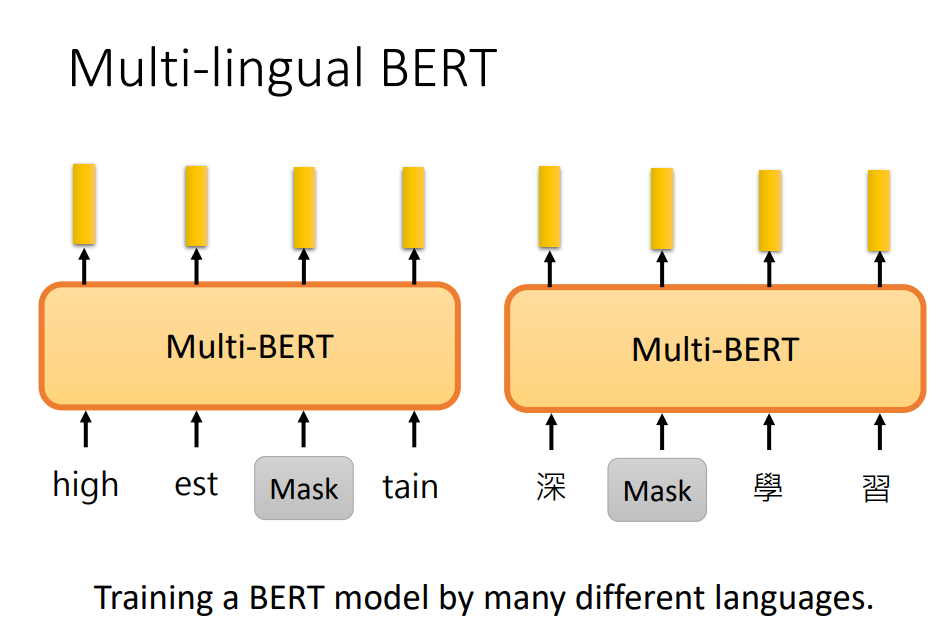
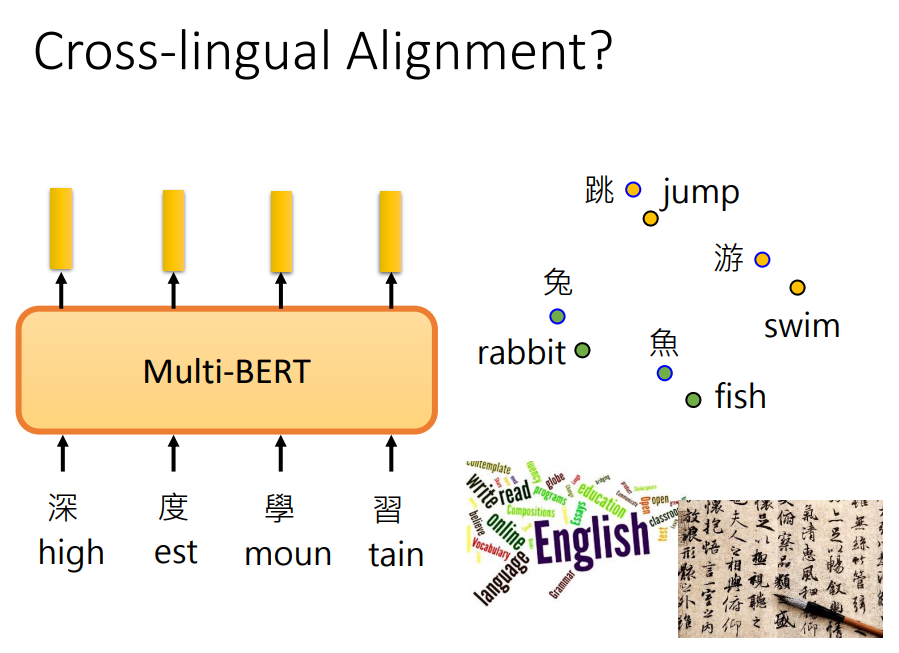
本文我们介绍多语言的BERT(Multilingual BERT),它能展现一些神奇的事情。 简介简单来说就是通过很多语言的数据,去训练一个模型。
由于不同语言有不同的token(单词),所以需要准备一个比较大的token集合,包含所有要训练语言的token。 然后和训练普通BERT一样,训练完结束了。
训练完之后,神奇的地方在于,它可以做到Zero-Shot Learning。训练完多语言的BERT之后,假设我们现在有英文的QA训练数据集,每份数据包含(文章、问题、答案)。 然后用这些训练数据去微调BERT,就可以做英文的QA。在英文上训练完后,它可以直接应用在中文的QA任务上。
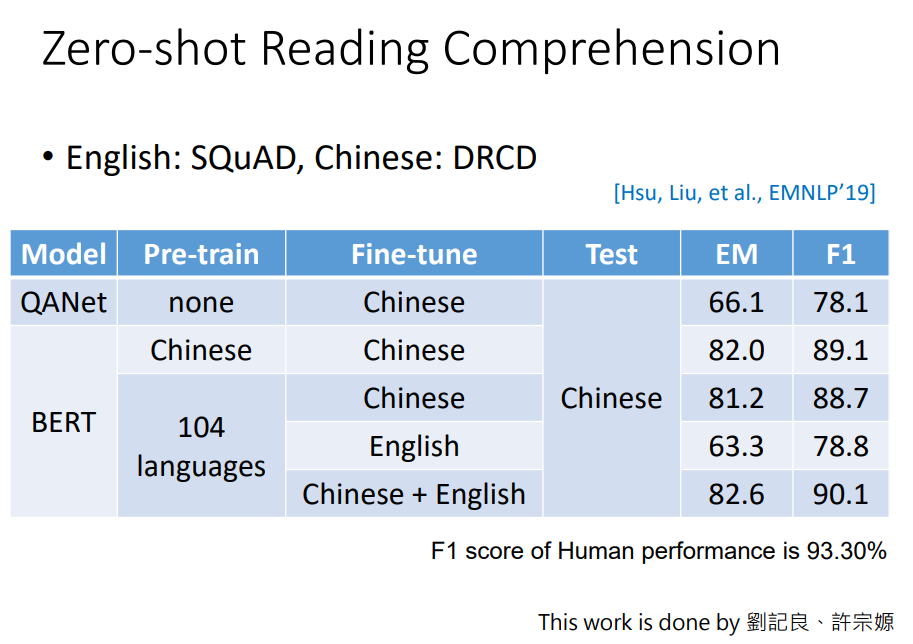
在QANet上训练中文数据,得到F1值是78.1; 然后用中文数据预训练BERT,并在中文数据上微调,可以得到89.1的F1; 然而用104中语言预训练的多语言BERT,在英文数据上微调,然后应用到中文上,居然得到了78.8的F1值,比QANet还要好; 如果同时用中文和英文数据微调,得到了最好结果90.1。
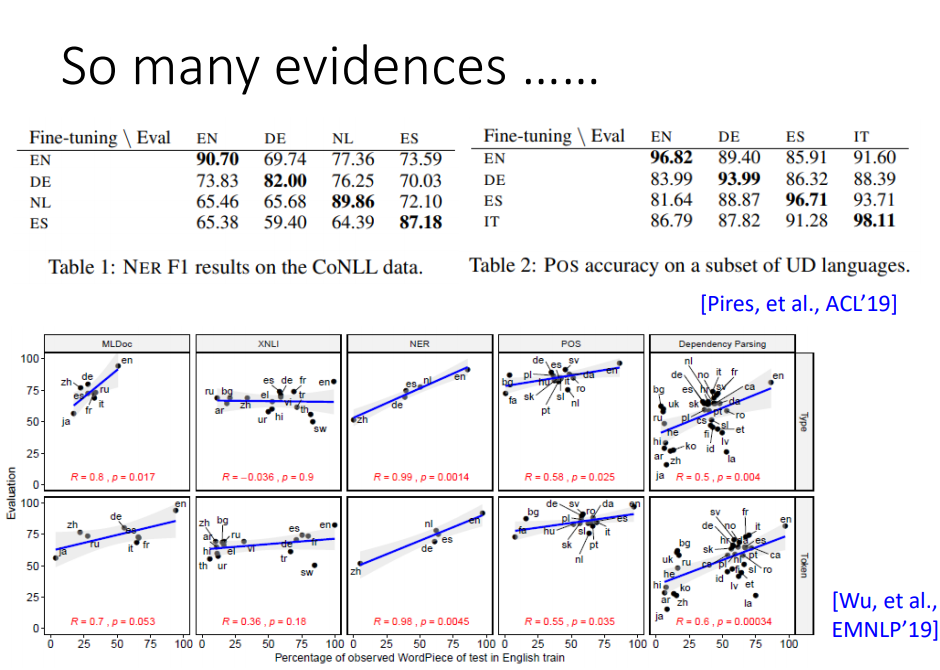
不是只有QA任务有这种现象,各种各样的NLP任务都有。 比如在命名实体识别(NER)和词性标注(POS)上都有。
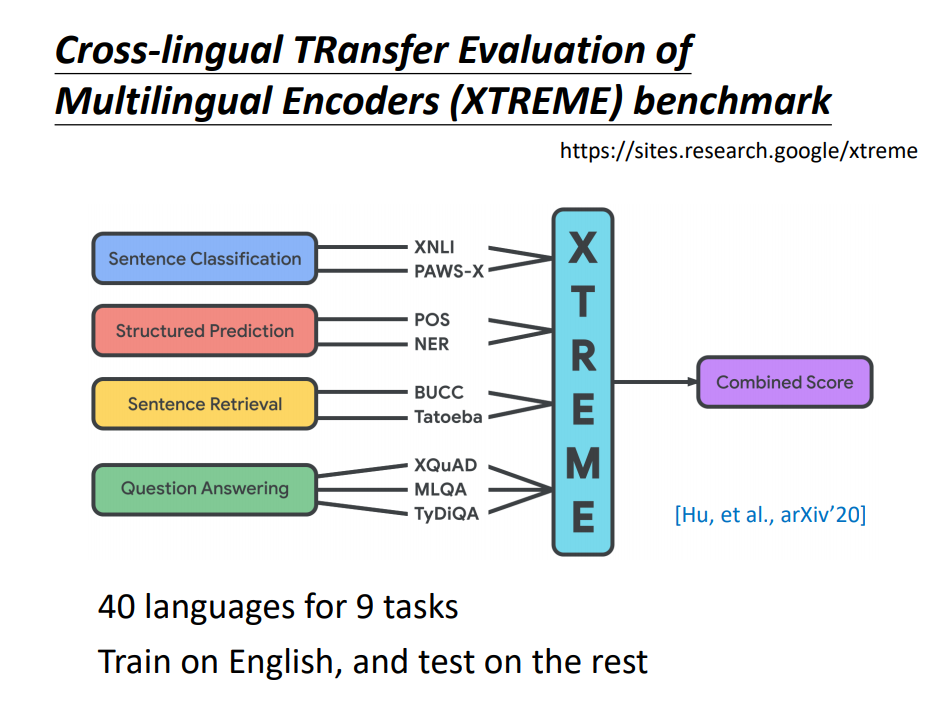
甚至谷歌还做了一个测试模型跨语言能力的基准(benchmark)。
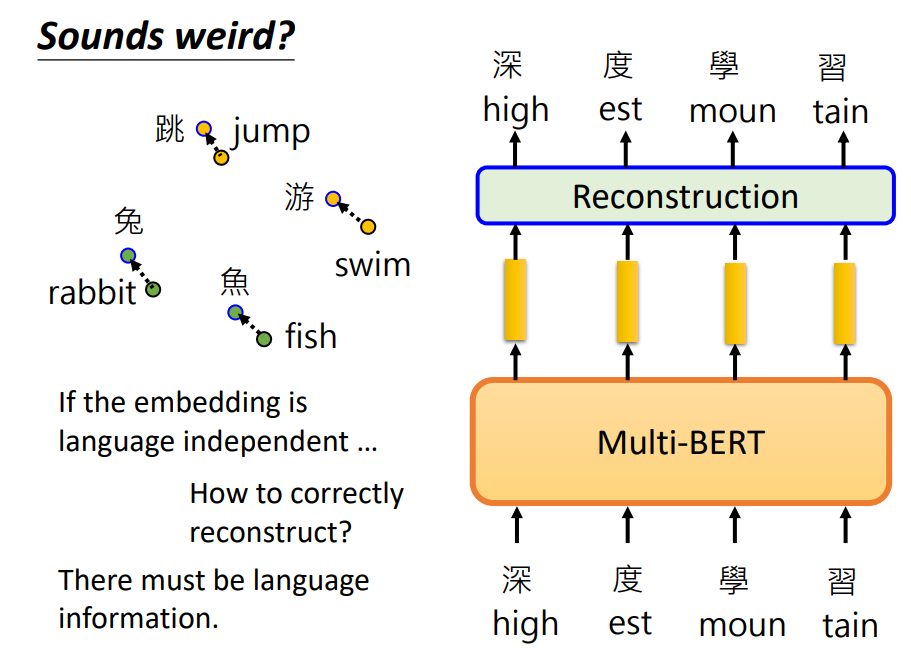
为什么跨语言能有作用呢,也许机器在Multi-BERT里面学到了把不同语言的信息去掉,只保留语义信息。 也许Multi-BERT对中文和英文的嵌入向量,看起来很接近。 那真的是这样吗
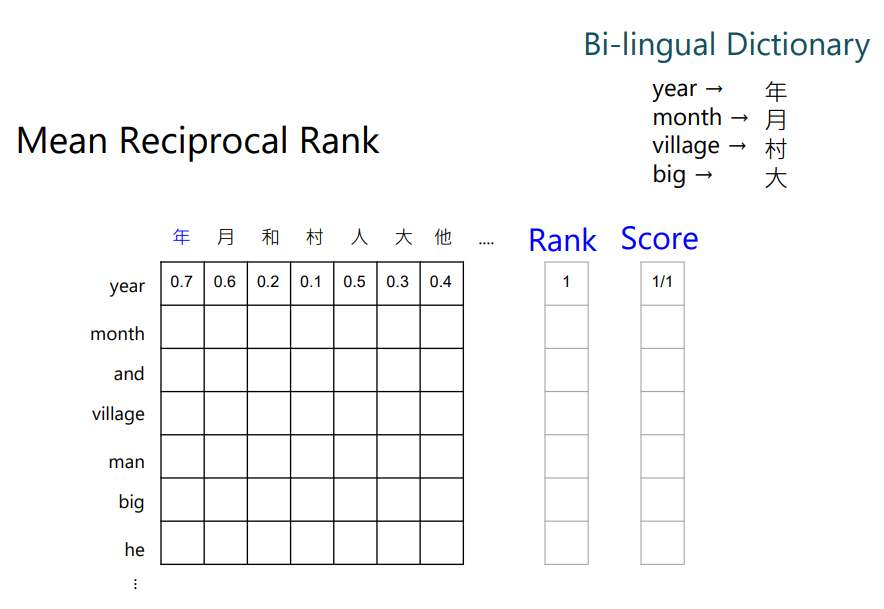
这里做了一个实验来验证这个结果,计算每个中文和对应英文token的嵌入向量。看不同语言,意思一样的token是否有一样的相似度。
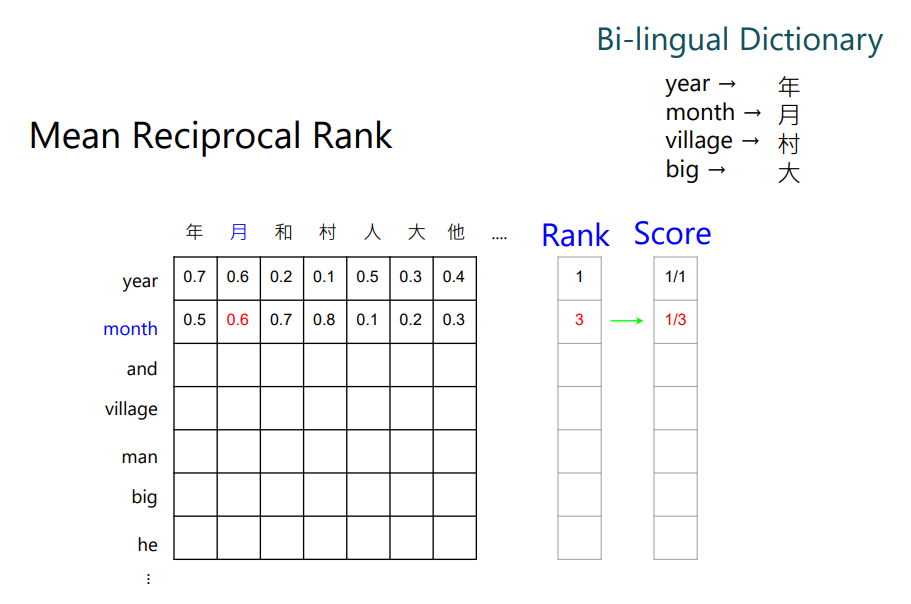
当然需要有个双语对照字典,比如year对应到中文的年;month对应到月。接下来就看year和哪个中文的token最接近,发现year和年最接近。然后就给year这个词1分。
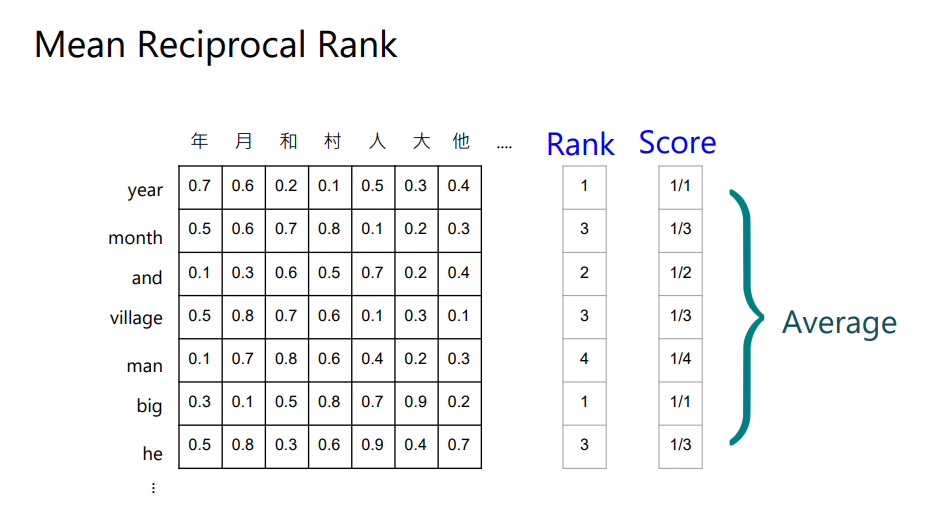
然后看month,可以看到月得到的值是排第三名,所以它的得分就是1/3(Mean Reciprocal Rank)。
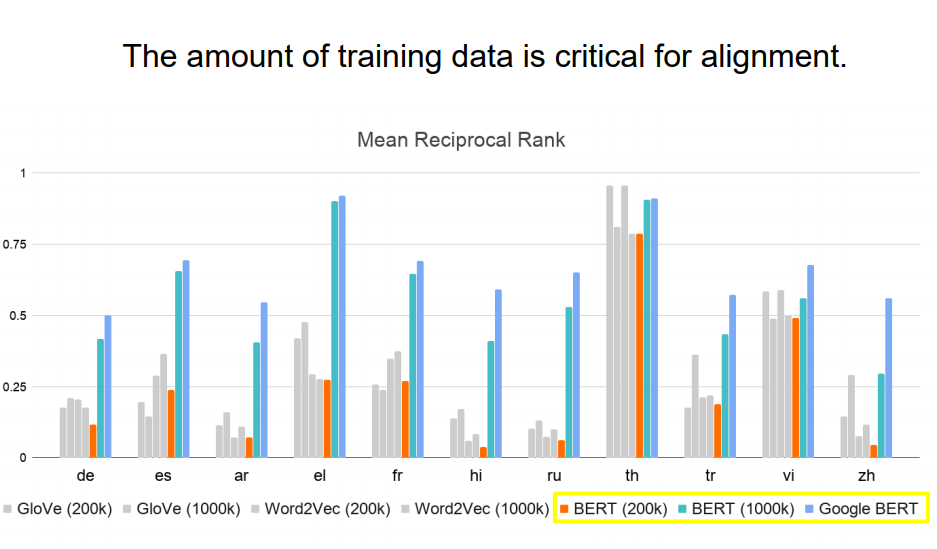
然后对每个英文token,都可以得到一个分数,把这些分数平均起来,就代表中文和英文对齐的关系。 分数越高,代表对齐的越好。
上面是实验结果,测试了英文和另外10种语言对齐的关系, 上面Google BERT就是多语言BERT,可以看到,它的表现不是排名第一就是第二。 中间括号里面的数字表示数据量,可以看到数据量是很关键的,比如BERT在200K数据下的表现不好,而在1000K数据下的表现就起飞了。
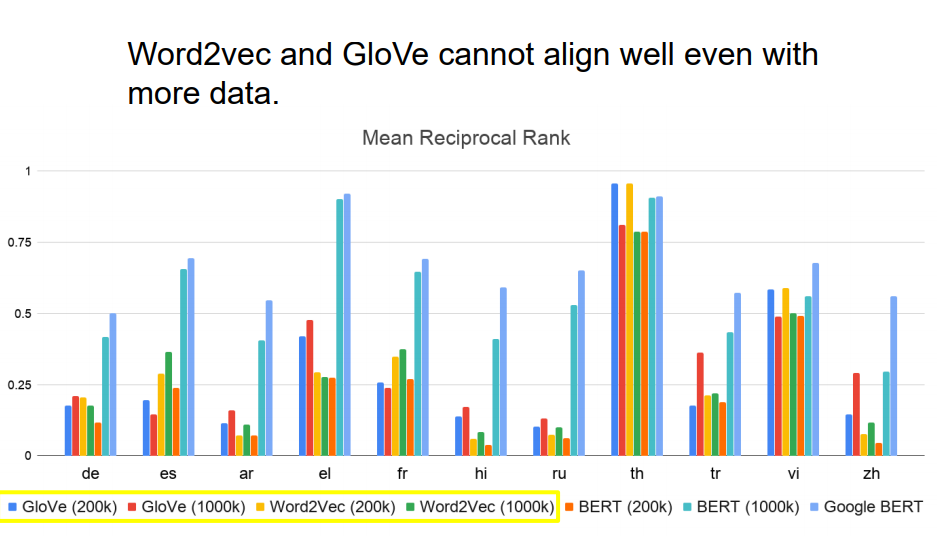
是不是因为过去的数据量不够,导致没有发现之前的模型也有这个对齐能力呢,上面就实验了给GloVe和Word2Vec多很多的数据量,看效果怎样 发现BERT结果还是要比它们要好。 BERT是如何做到对齐的
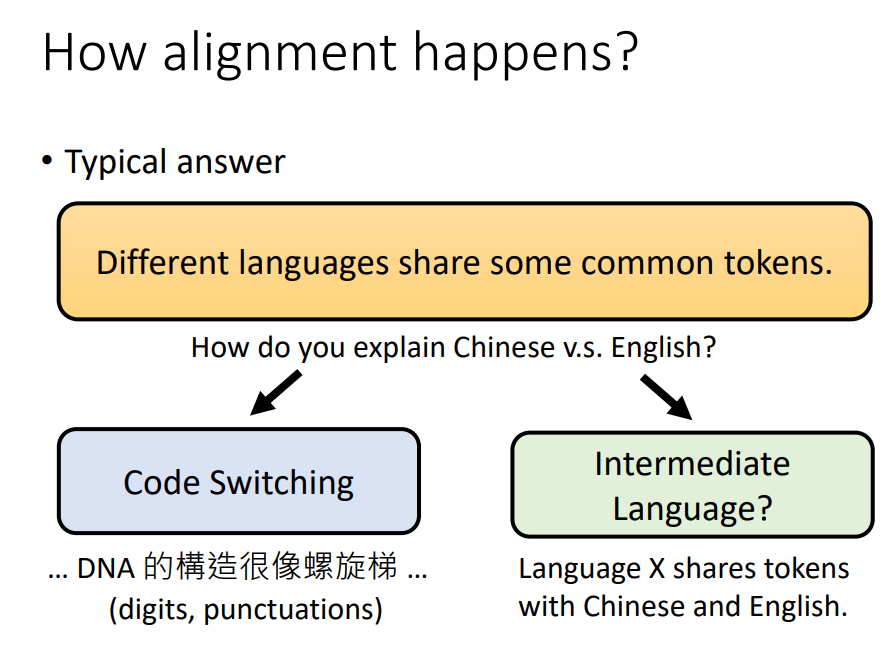
一种直觉的想法是,不同的语言可能会有同样的token,这些同样的token在不同语言中,可能也对应到同样的意思。 然后Multi-BERT可以把这些不同语言,同样的token对齐在一起。 真的是这样吗? 那如何解释Multi-BERT也能把中文和英文对齐。英文是字母组成的,中文是方块字。 也许是英文Code Switching的关系,Code Switching就是中英交杂的意思,比如解说喜欢说的,这次抓人的timing很好。 中文和英文都有阿拉伯数字,这一些共同的token。 另外一种猜测是,会不会有一种神秘的中间语言,这种中间语言在中文和英文中共用了一些token。
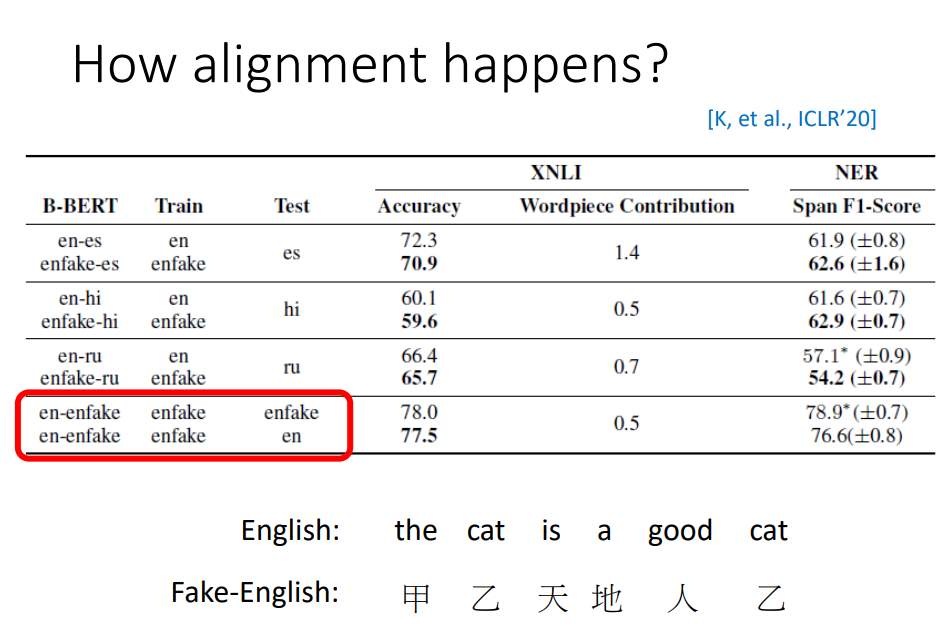
有人做了一个实验,把英文中的token都换成了另外一个不存在于英文中的token。比如把“the”换成了“甲”,制造了Fake-English(假英文)这种语言。 它们绝对没有Code Switching和共用的token(中间语言)。 那这种情况下,Multi-BERT能把这两种语言对齐吗 实验结果看起来是有可能的,用英文和假英文进行预训练,然后在假英文上微调,在假英文上测试,得到的结果如上,还不错; 然后又在真正的英文上测试,发现在XNLI的正确率是77.5,在NER任务上是76.6。 说明这种跨语言的能力,不需要两个语言有同样的token,也不需要中间语言的存在。现在还不知道到底是如何学到跨语言的能力。
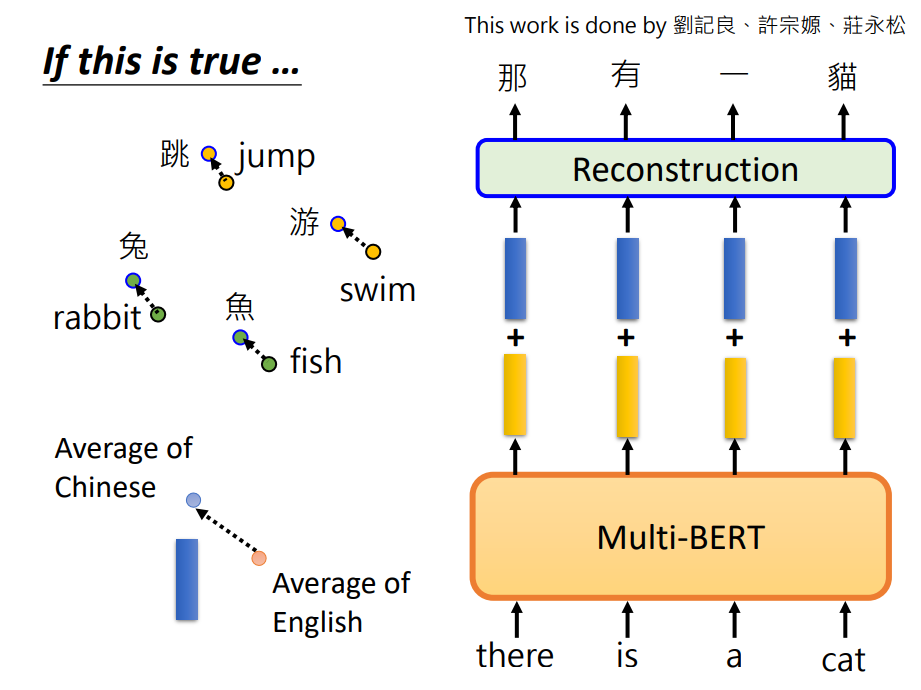
我们想不同语言,同样意思的token,训练完了之后,它们的向量就可以相邻,这样的想法合理吗。 现在我们输入英文,它就会输出英文;我们输入中文,它就会输出中文。 如果Multi-BERT把语言间的差异抹掉,它是如何做到输入中文,输出中文;输入英文就输出英文的。 所以Multi-BERT显然是知道语言的信息的。那我们来找找语言的信息。
有人实验了不同语言的嵌入平均起来,发现不同语言还是有一些差异的。但是同样语系的语言,它们嵌入向量的平均值就会比较接近。 那Multi-BERT是通过什么样的方式,把语言信息存储的呢
假设我们把所有英文嵌入向量平均起来,假设在上图橙色点那里; 把所有的中文嵌入向量平均起来,在上图蓝色点那里。 然后中文和英文间的差异,就用这两个向量想减,得到上面的蓝色向量。 虽然中文和英文嵌入向量是混杂在一起的,但是也许同样中文的嵌入向量都在英文向量的左上角。 所以只要我们计算出它们之间的差异——蓝色向量,而Multi-BERT就是看这个差异,来决定输出中文还是英文的嵌入向量。 如果真的是这样子,理论上我们就可以做到,把英文的嵌入向量加上这个蓝色差异向量,然后Multi-BERT就以为它看到了中文的嵌入,就可以输出中文的翻译结果。
这种思想和GAN有点类似。
假设今天输入一段英文,然后丢到Multi-BERT中,接下来在某层加入蓝色的向量,输出的句子真的就出现了一些中文。同时设置一些权重,把差异放大。在权重 α = 1 \alpha=1 α=1的时候,达到了一点点效果。 如果设置 α = 2 , 3 \alpha=2,3 α=2,3,可以发现基本输出都是中文了,不过翻译的结果不太好,不过可以从侧面验证,Multi-BERT确实可以包含语言的信息,我们可以修改这个信息,就可以改变Multi-BERT输出的语言。 那知道这一点有什么用呢。
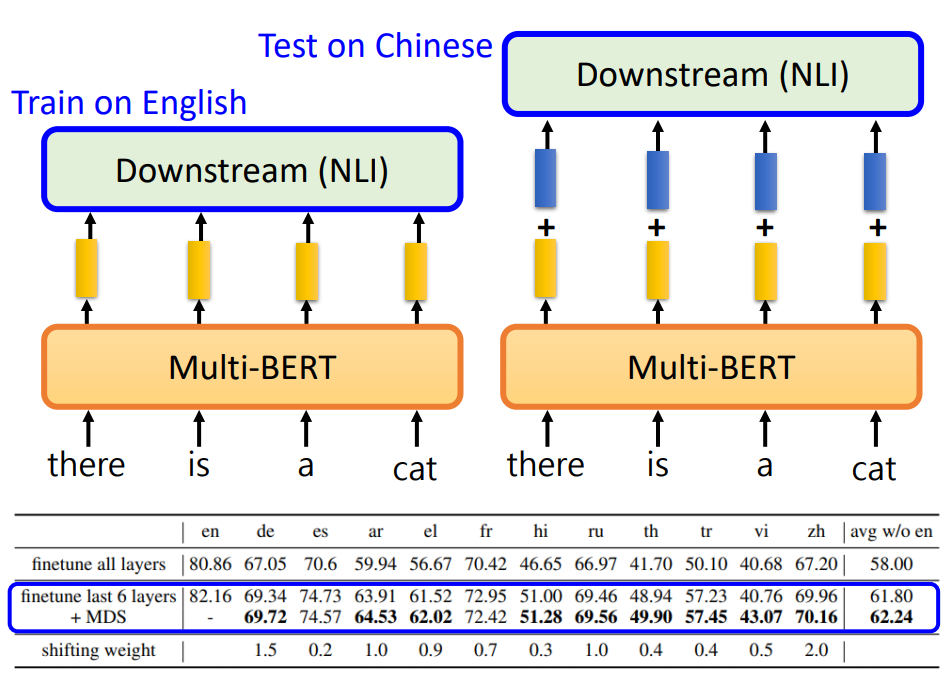
我们能否把这种语言的信息抹掉,让Multi-BERT跨语言的效果更好? 在NLI任务中,我们把Multi-BERT在英文上微调,接下来在中文上测试。 但是在测试的时候,我们让输入英文得到的嵌入向量,看起来更像中文,我们再它们的嵌入向量基础上,加上上面得到的蓝色差异向量,这个步骤不需要微调,我们只要在测试的时候直接做这件事就可以了,我们发现在不同的语言上,加上差异向量得到的结果好了一点。 |




【本文地址】
今日新闻 |
推荐新闻 |