Python基础 |
您所在的位置:网站首页 › 中国确诊人数最新动态图片 › Python基础 |
Python基础
|
前言
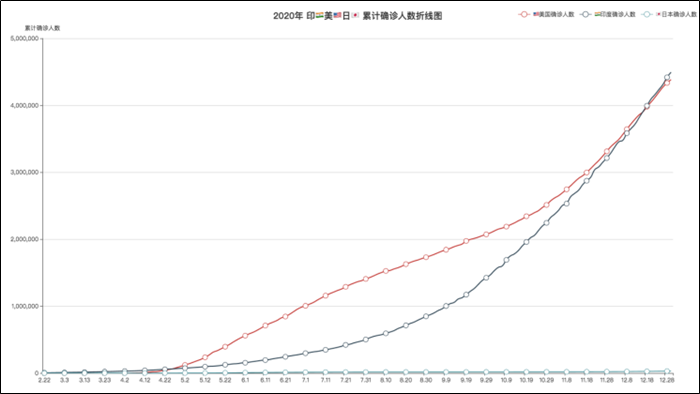
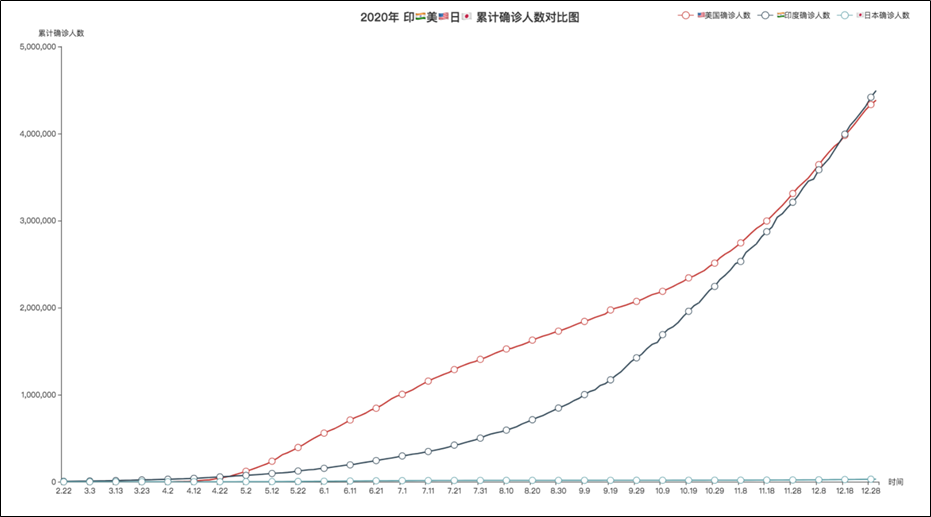
本文是根据黑马程序员Python教程所作之笔记,目的是为了方便我本人以及广大同学们查漏补缺。 不想做笔记直接来我的频道。当然啦,自己的笔记才是最好的哦! PS:感谢黑马程序员! 教程链接:黑马程序员最新Python教程,8天python从入门到精通,学python看这套就够了 Python基础模块总目录 第一章:你好Python 第二章:Python基础语法 第三章:Python判断语句 第四章:Python循环语句 第五章:Python函数 第六章:Python数据容器 第七章:Python函数进阶 第八章:Python文件操作 第九章:Python异常、模块与包 基础综合案例之数据可视化 目录 前言Python基础综合案例(数据可视化 - 折线图可视化)json数据格式pyecharts模块介绍pyecharts快速入门数据处理创建折线图 Python基础综合案例(数据可视化 - 地图可视化)基础地图使用疫情地图-国内疫情地图疫情地图-省级疫情地图 Python基础综合案例(数据可视化 - 动态柱状图)基础柱状图基础时间线柱状图GDP动态柱状图绘制 Python基础综合案例(数据可视化 - 折线图可视化)效果一:2020年印美日新冠累计确诊人数 2020年是新冠疫情爆发的一年,随着疫情的爆发,国内外确诊人数成了大家关心的热点,相信大家都有看过类似的疫情报告。本案例对印度美国日本三个国家确诊人数的进行了可视化处理,形成了可视化的疫情确诊人数报告。
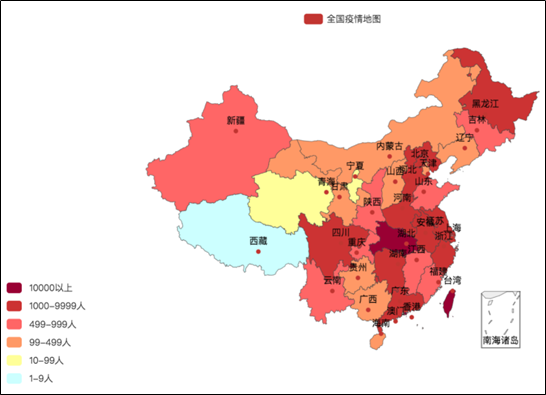
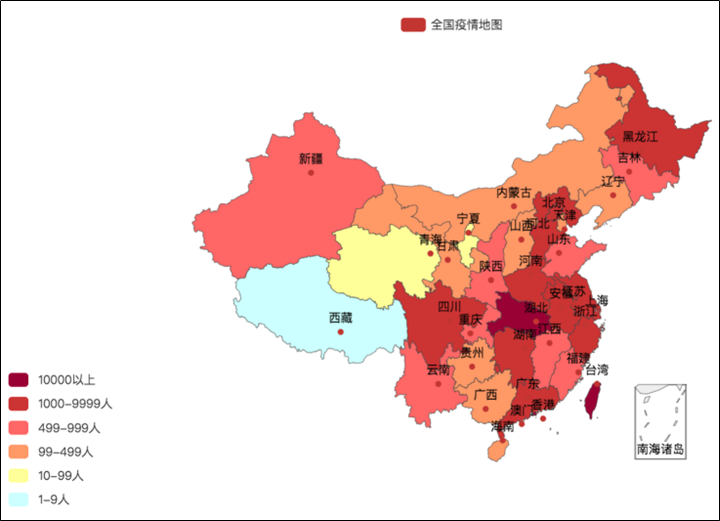
效果二:全国疫情地图可视化
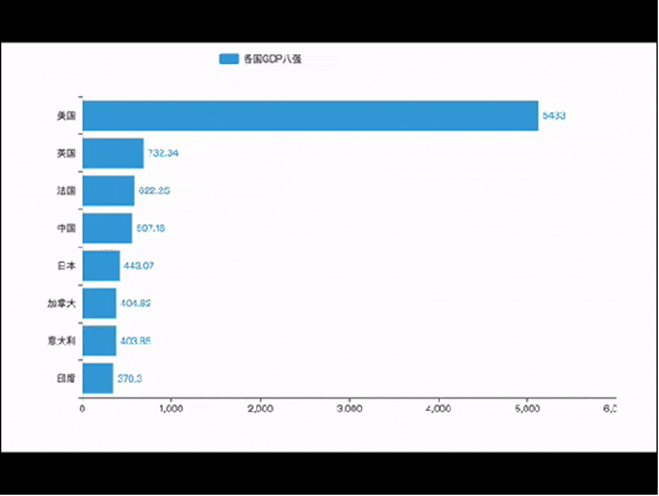
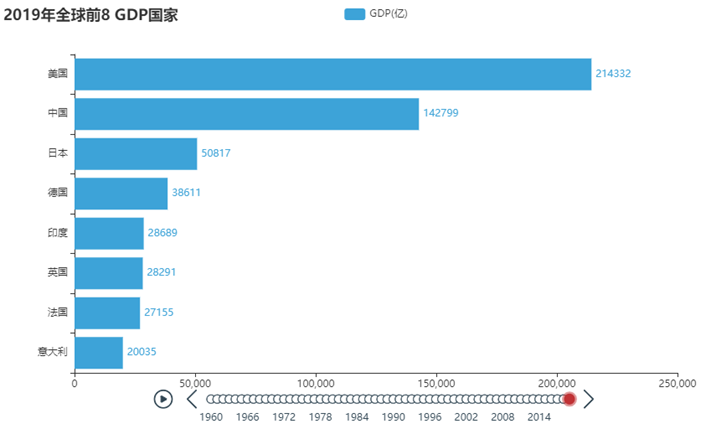
效果三:动态GDP增长图
数据来源 本案例数据全部来自 ,及公开的全球各国GDP数据 使用的技术: Echarts 是个由百度开源的数据可视化,凭借着良好的交互性,精巧的图表设计,得到了众多开发者的认可. 而 Python 是门富有表达力的语言,很适合用于数据处理. 当数据分析遇上数据可视化时pyecharts 诞生了.
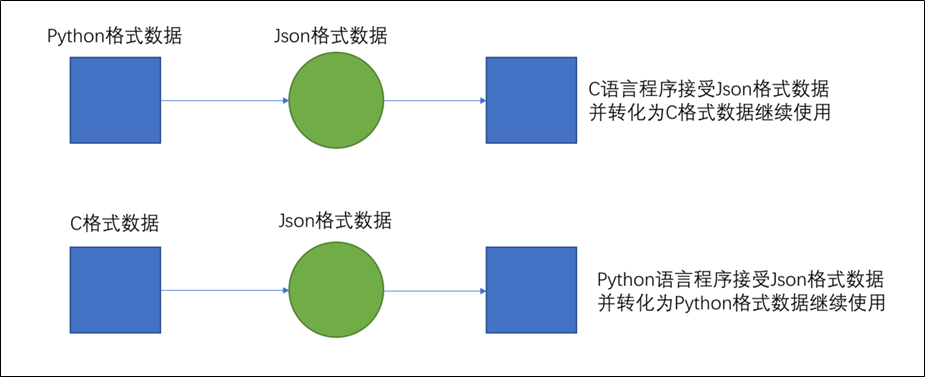
什么是json JSON是一种轻量级的数据交互格式。可以按照JSON指定的格式去组织和封装数据 JSON本质上是一个带有特定格式的字符串 主要功能:json就是一种在各个编程语言中流通的数据格式,负责不同编程语言中的数据传递和交互。类似于: 国际通用语言-英语 中国56个民族不同地区的通用语言-普通话 Python语言使用JSON有很大优势,因为:JSON无非就是一个单独的字典或一个内部元素都是字典的列表 所以JSON可以直接和Python的字典或列表进行无缝转换。 json有什么用 各种编程语言存储数据的容器不尽相同,在Python中有字典dict这样的数据类型,而其它语言可能没有对应的字典。为了让不同的语言都能够相互通用的互相传递数据,JSON就是一种非常良好的中转数据格式。如下图,以Python和C语言互传数据为例:
json格式数据转化 json格式的数据要求很严格,下面我们看一下他的要求
Python数据和Json数据的相互转化 Python数据和Json数据的相互转化
通过 json.dumps(data) 方法把python数据转化为了 json数据 data = json.dumps(data) 如果有中文可以带上:ensure_ascii=False 参数来确保中文正常转换 通过 json.loads(data) 方法把josn数据转化为了 python列表或字典 data = json.loads(data) """ 演示JSON数据和Python字典的相互转换 """ import json # 准备列表,列表内每一个元素都是字典,将其转换为JSON data = [{"name": "张大山", "age": 11}, {"name": "王大锤", "age": 13}, {"name": "赵小虎", "age": 16}] json_str = json.dumps(data, ensure_ascii=False) print(type(json_str)) print(json_str) # 准备字典,将字典转换为JSON d = {"name":"周杰轮", "addr":"台北"} json_str = json.dumps(d, ensure_ascii=False) print(type(json_str)) print(json_str) # 将JSON字符串转换为Python数据类型[{k: v, k: v}, {k: v, k: v}] s = '[{"name": "张大山", "age": 11}, {"name": "王大锤", "age": 13}, {"name": "赵小虎", "age": 16}]' l = json.loads(s) print(type(l)) print(l) # 将JSON字符串转换为Python数据类型{k: v, k: v} s = '{"name": "周杰轮", "addr": "台北"}' d = json.loads(s) print(type(d)) print(d) pyecharts模块介绍pyecharts模块 如果想要做出数据可视化效果图, 可以借助pyecharts模块来完成 概况 : Echarts 是个由百度开源的数据可视化,凭借着良好的交互性,精巧的图表设计,得到了众多开发者的认可。而 Python 是门富有表达力的语言,很适合用于数据处理。当数据分析遇上数据可视化时 pyecharts 诞生了 pyecharts模块安装 使用在前面学过的pip命令即可快速安装PyEcharts模块 pip install pyecharts
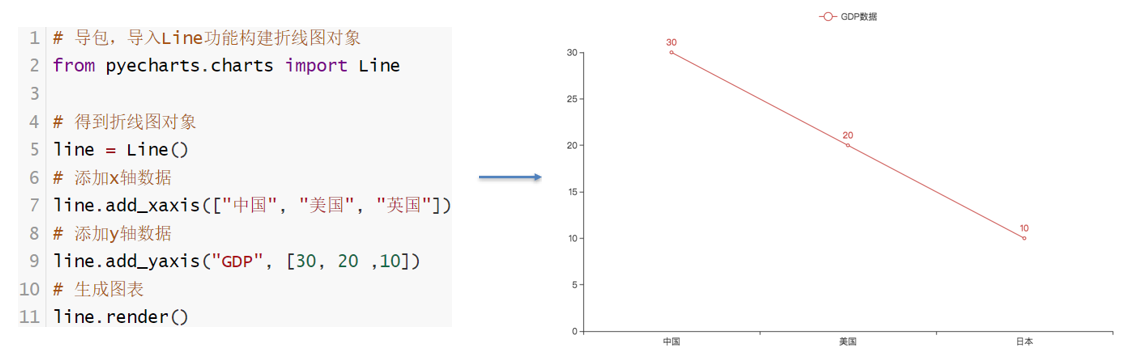
查看官方示例 打开官方画廊: https://gallery.pyecharts.org/#/README pyecharts快速入门pyechars入门 基础折线图
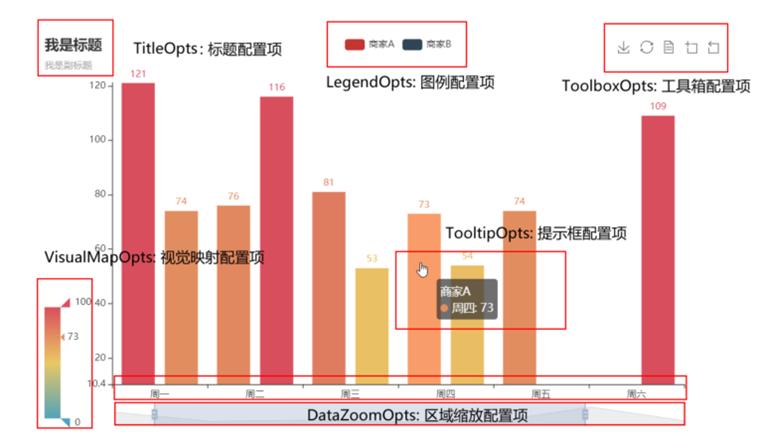
pyecharts有哪些配置选项 pyecharts模块中有很多的配置选项,常用到2个类别的选项: 全局配置选项 系列配置选项 全局配置项能做什么? 配置图表的标题 配置图例 配置鼠标移动效果 配置工具栏 等整体配置项 set_global_opts方法 这里全局配置选项可以通过 set_global_opts 方法来进行配置,相应的选项和选项的功能如下:
系列配置项,我们在后面构建案例时讲解
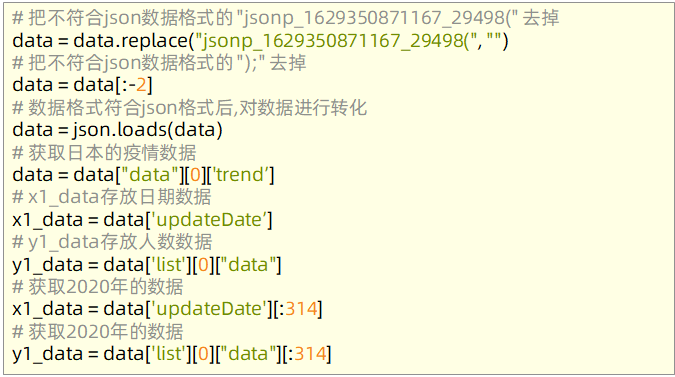
数据处理 原始数据格式:
导入模块:
对数据进行整理,让数据符合json格式:
导入模块 导入模块:
折线图相关配置项 折线图相关配置项:
创建折线图
这里的Line()是构建类对象,我们先不必理解是什么意思,后续在Python高阶中进行详细讲解。 目前我们简单的会用即可 添加数据
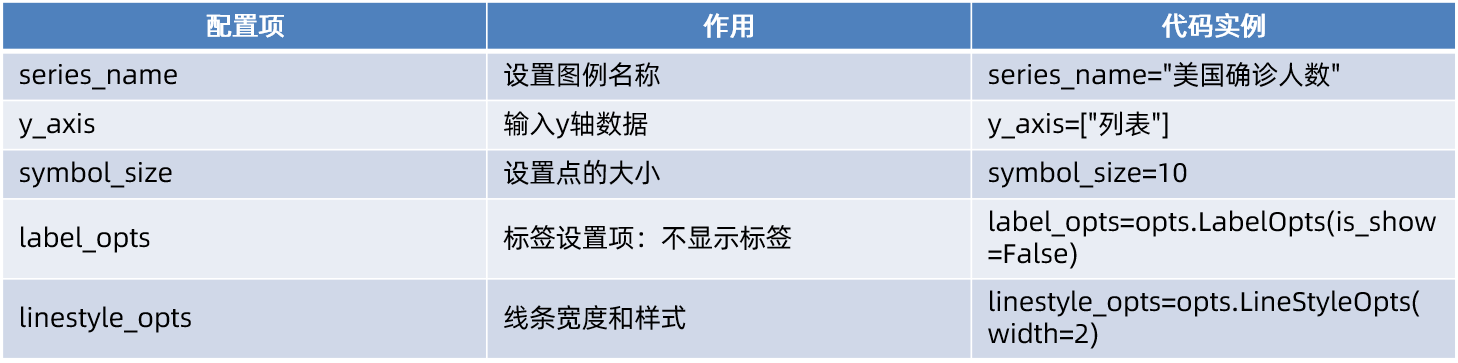
.add_yaxis相关配置选项:
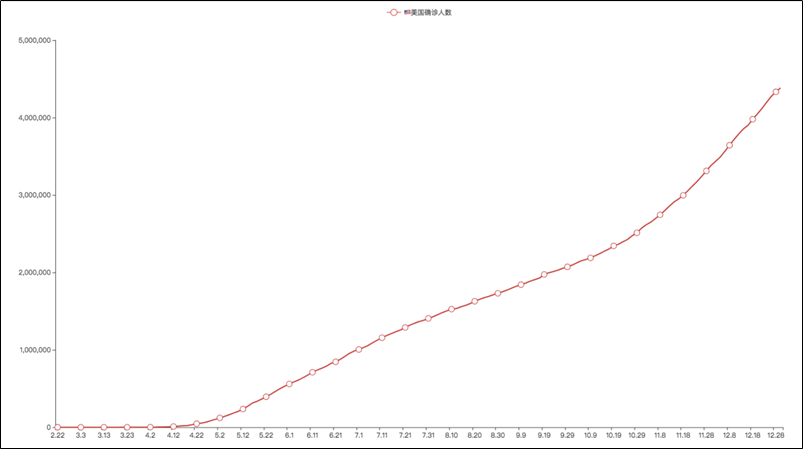
运行效果图:
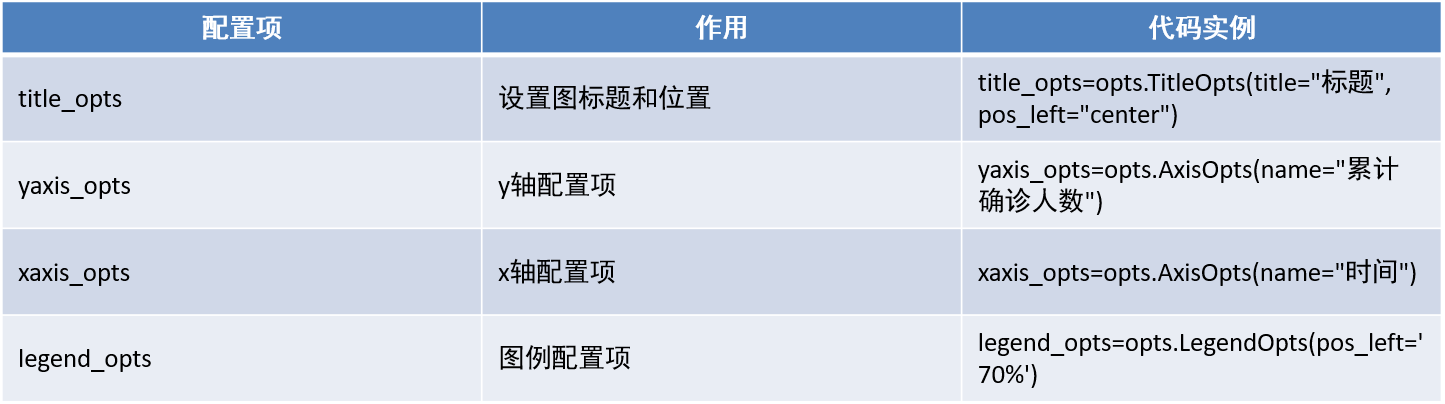
全局配置选项 .set_global_opts全局配置选项:
运行效果图:
基础地图演示
基础地图演示 - 视觉映射器
案例效果
代码总览 """ 演示全国疫情可视化地图开发 """ import json from pyecharts.charts import Map from pyecharts.options import * # 读取数据文件 f = open("C:/地图数据疫情.txt", "r", encoding="UTF-8") data = f.read() # 全部数据 # 关闭文件 f.close() # 取到各省数据 # 将字符串json转换为python的字典 data_dict = json.loads(data) # 基础数据字典 # 从字典中取出省份的数据 province_data_list = data_dict["areaTree"][0]["children"] # 组装每个省份和确诊人数为元组,并各个省的数据都封装入列表内 data_list = [] # 绘图需要用的数据列表 for province_data in province_data_list: province_name = province_data["name"] # 省份名称 province_confirm = province_data["total"]["confirm"] # 确诊人数 data_list.append((province_name, province_confirm)) # 创建地图对象 map = Map() # 添加数据 map.add("各省份确诊人数", data_list, "china") # 设置全局配置,定制分段的视觉映射 map.set_global_opts( title_opts=TitleOpts(title="全国疫情地图"), visualmap_opts=VisualMapOpts( is_show=True, # 是否显示 is_piecewise=True, # 是否分段 pieces=[ {"min": 1, "max": 99, "lable": "1~99人", "color": "#CCFFFF"}, {"min": 100, "max": 999, "lable": "100~9999人", "color": "#FFFF99"}, {"min": 1000, "max": 4999, "lable": "1000~4999人", "color": "#FF9966"}, {"min": 5000, "max": 9999, "lable": "5000~99999人", "color": "#FF6666"}, {"min": 10000, "max": 99999, "lable": "10000~99999人", "color": "#CC3333"}, {"min": 100000, "lable": "100000+", "color": "#990033"}, ] ) ) # 绘图 map.render("全国疫情地图.html") 疫情地图-省级疫情地图省疫情地图 效果展示
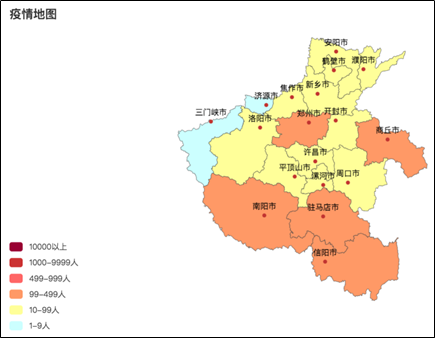
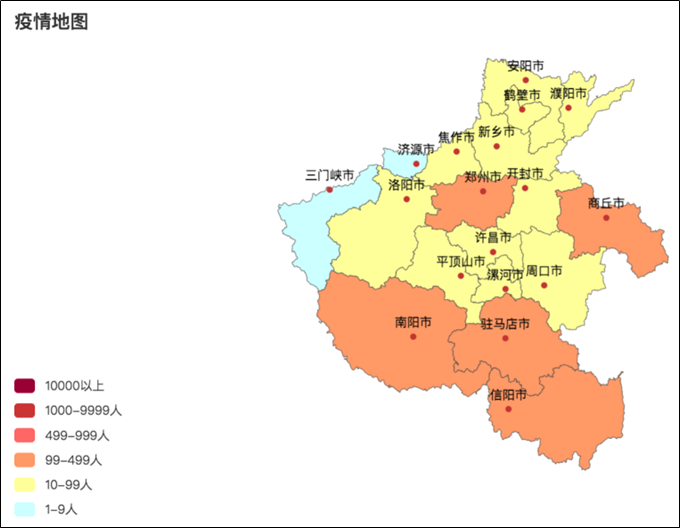
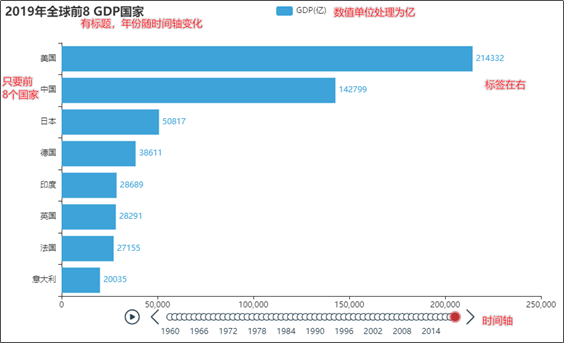
代码总览 """ 演示河南省疫情地图开发 """ import json from pyecharts.charts import Map from pyecharts.options import * # 读取文件 f = open("C:/疫情.txt", "r", encoding="UTF-8") data = f.read() # 关闭文件 f.close() # 获取河南省数据 # json数据转换为python字典 data_dict = json.loads(data) # 取到河南省数据 cities_data = data_dict["areaTree"][0]["children"][3]["children"] # 准备数据为元组并放入list data_list = [] for city_data in cities_data: city_name = city_data["name"] + "市" city_confirm = city_data["total"]["confirm"] data_list.append((city_name, city_confirm)) # 手动添加济源市的数据 data_list.append(("济源市", 5)) # 构建地图 map = Map() map.add("河南省疫情分布", data_list, "河南") # 设置全局选项 map.set_global_opts( title_opts=TitleOpts(title="河南省疫情地图"), visualmap_opts=VisualMapOpts( is_show=True, # 是否显示 is_piecewise=True, # 是否分段 pieces=[ {"min": 1, "max": 99, "lable": "1~99人", "color": "#CCFFFF"}, {"min": 100, "max": 999, "lable": "100~9999人", "color": "#FFFF99"}, {"min": 1000, "max": 4999, "lable": "1000~4999人", "color": "#FF9966"}, {"min": 5000, "max": 9999, "lable": "5000~99999人", "color": "#FF6666"}, {"min": 10000, "max": 99999, "lable": "10000~99999人", "color": "#CC3333"}, {"min": 100000, "lable": "100000+", "color": "#990033"}, ] ) ) # 绘图 map.render("河南省疫情地图.html") Python基础综合案例(数据可视化 - 动态柱状图)案例效果 通过pyechars可以实现数据的动态显示, 直观的感受1960~2019年全世界各国GDP的变化趋势
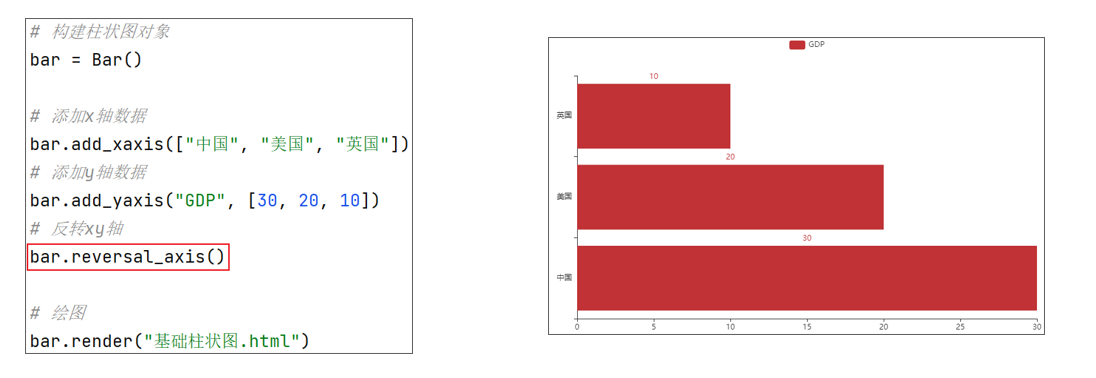
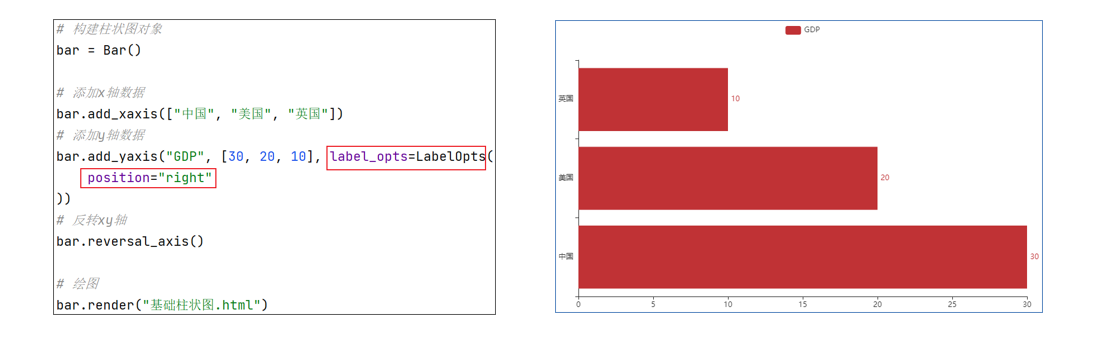
通过 Bar() 构建一个柱状图对象 和折线图一样,通过 add_xaxis() 和 add_yaxis() 添加x和y轴数据 通过柱状图对象的:reversal_axis(),反转x和y轴 通过 label_opts=LabelOpts(position="right") 设置数值标签在右侧显示 通过Bar构建基础柱状图
反转x和y轴
数值标签在右侧
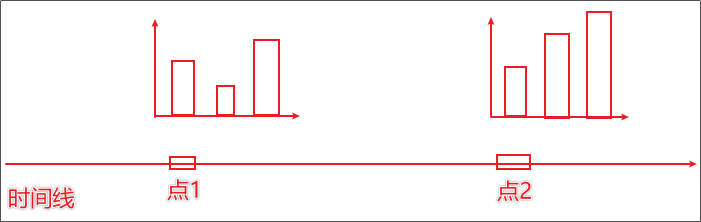
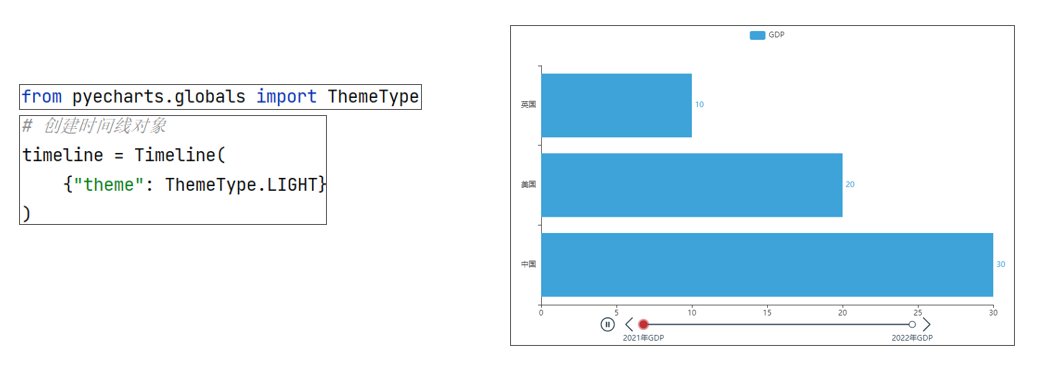
创建时间线 Timeline() - 时间线 柱状图描述的是分类数据,回答的是每一个分类中『有多少?』这个问题。这是柱状图的主要特点,同时柱状图很难动态的描述一个趋势性的数据。这里pyecharts为我们提供了一种解决方案 - 时间线 如果说一个Bar、Line对象是一张图表的话,时间线就是创建一个一维的x轴,轴上每一个点就是一个图表对象
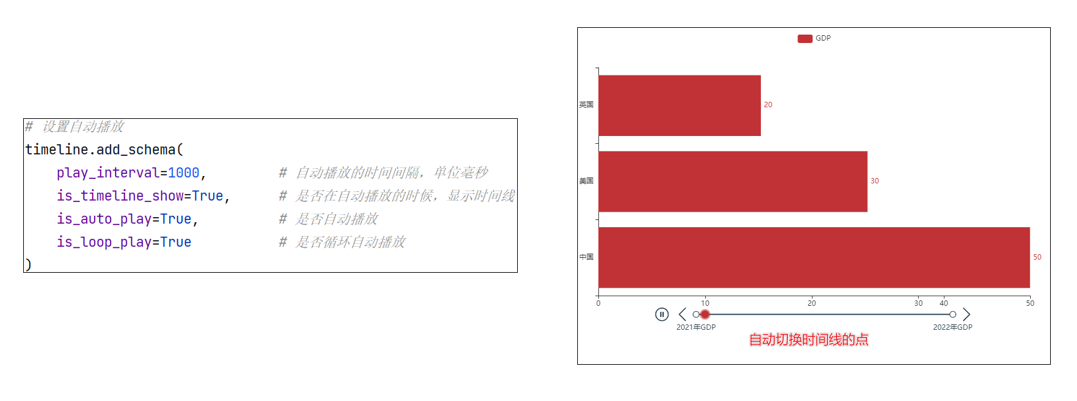
自动播放
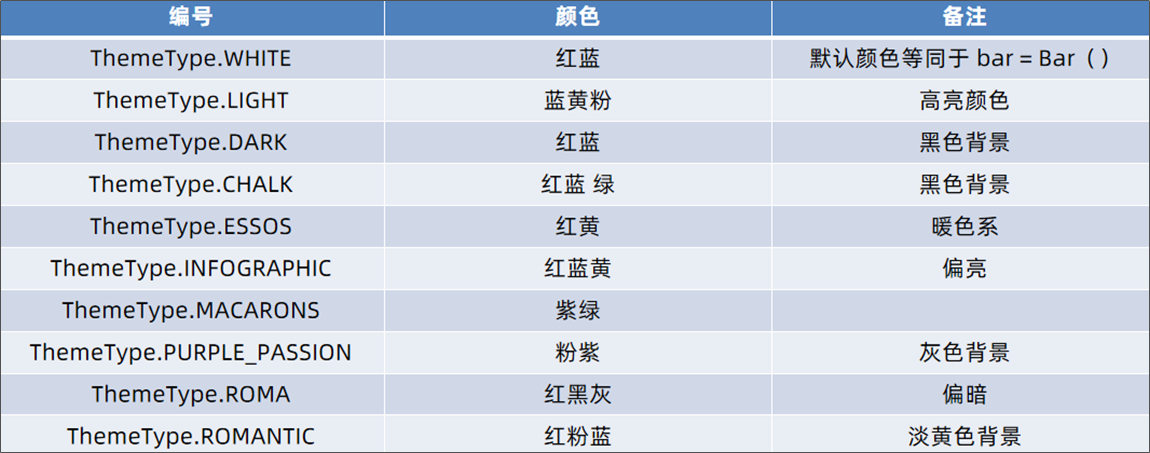
时间线设置主题 timeline = Timeline({"theme": ThemeType.LIGHT})
需求分析
简单分析后,发现最终效果图中需要: GDP数据处理为亿级 有时间轴,按照年份为时间轴的点 x轴和y轴反转,同时每一年的数据只要前8名国家 有标题,标题的年份会动态更改 设置了主题为LIGHT 列表的sort方法 在前面我们学习过sorted函数,可以对数据容器进行排序。 在后面的数据处理中,我们需要对列表进行排序,并指定排序规则,sorted函数就无法完成了。 我们补充学习列表的sort方法。 使用方式: 列表.sort(key=选择排序依据的函数, reverse=True|False) 参数key,是要求传入一个函数,表示将列表的每一个元素都传入函数中,返回排序的依据 参数reverse,是否反转排序结果,True表示降序,False表示升序
代码总览 """ 演示第三个图表:GDP动态柱状图开发 """ from pyecharts.charts import Bar, Timeline from pyecharts.options import * from pyecharts.globals import ThemeType # 读取数据 f = open("C:/1960-2019全球GDP数据.csv", "r", encoding="GB2312") data_lines = f.readlines() # 关闭文件 f.close() # 删除第一条数据 data_lines.pop(0) # 将数据转换为字典存储,格式为: # { 年份: [ [国家, gdp], [国家,gdp], ...... ], 年份: [ [国家, gdp], [国家,gdp], ...... ], ...... } # { 1960: [ [美国, 123], [中国,321], ...... ], 1961: [ [美国, 123], [中国,321], ...... ], ...... } # 先定义一个字典对象 data_dict = {} for line in data_lines: year = int(line.split(",")[0]) # 年份 country = line.split(",")[1] # 国家 gdp = float(line.split(",")[2]) # gdp数据 # 如何判断字典里面有没有指定的key呢? try: data_dict[year].append([country, gdp]) except KeyError: data_dict[year] = [] data_dict[year].append([country, gdp]) # 创建时间线对象 timeline = Timeline({"theme": ThemeType.LIGHT}) # 排序年份 sorted_year_list = sorted(data_dict.keys()) for year in sorted_year_list: data_dict[year].sort(key=lambda element: element[1], reverse=True) # 取出本年份前8名的国家 year_data = data_dict[year][0:8] x_data = [] y_data = [] for country_gdp in year_data: x_data.append(country_gdp[0]) # x轴添加国家 y_data.append(country_gdp[1] / 100000000) # y轴添加gdp数据 # 构建柱状图 bar = Bar() x_data.reverse() y_data.reverse() bar.add_xaxis(x_data) bar.add_yaxis("GDP(亿)", y_data, label_opts=LabelOpts(position="right")) # 反转x轴和y轴 bar.reversal_axis() # 设置每一年的图表的标题 bar.set_global_opts( title_opts=TitleOpts(title=f"{year}年全球前8GDP数据") ) timeline.add(bar, str(year)) # for循环每一年的数据,基于每一年的数据,创建每一年的bar对象 # 在for中,将每一年的bar对象添加到时间线中 # 设置时间线自动播放 timeline.add_schema( play_interval=1000, is_timeline_show=True, is_auto_play=True, is_loop_play=False ) # 绘图 timeline.render("1960-2019全球GDP前8国家.html") |

















【本文地址】
今日新闻 |
推荐新闻 |